 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucas C. Cordeiro
Tasks People Prompt: A Taxonomy of LLM Downstream Tasks in Software Verification and Falsification Approaches
Apr 14, 2024
Prompting has become one of the main approaches to leverage emergent capabilities of Large Language Models [Brown et al. NeurIPS 2020, Wei et al. TMLR 2022, Wei et al. NeurIPS 2022]. During the last year, researchers and practitioners have been playing with prompts to see how to make the most of LLMs. By homogeneously dissecting 80 papers, we investigate in deep how software testing and verification research communities have been abstractly architecting their LLM-enabled solutions. More precisely, first, we want to validate whether downstream tasks are an adequate concept to convey the blueprint of prompt-based solutions. We also aim at identifying number and nature of such tasks in solutions. For such goal, we develop a novel downstream task taxonomy that enables pinpointing some engineering patterns in a rather varied spectrum of Software Engineering problems that encompasses testing, fuzzing, debugging, vulnerability detection, static analysis and program verification approaches.
NeuroCodeBench: a plain C neural network benchmark for software verification
Sep 07, 2023


Safety-critical systems with neural network components require strong guarantees. While existing neural network verification techniques have shown great progress towards this goal, they cannot prove the absence of software faults in the network implementation. This paper presents NeuroCodeBench - a verification benchmark for neural network code written in plain C. It contains 32 neural networks with 607 safety properties divided into 6 categories: maths library, activation functions, error-correcting networks, transfer function approximation, probability density estimation and reinforcement learning. Our preliminary evaluation shows that state-of-the-art software verifiers struggle to provide correct verdicts, due to their incomplete support of the standard C mathematical library and the complexity of larger neural networks.
SecureFalcon: The Next Cyber Reasoning System for Cyber Security
Jul 13, 2023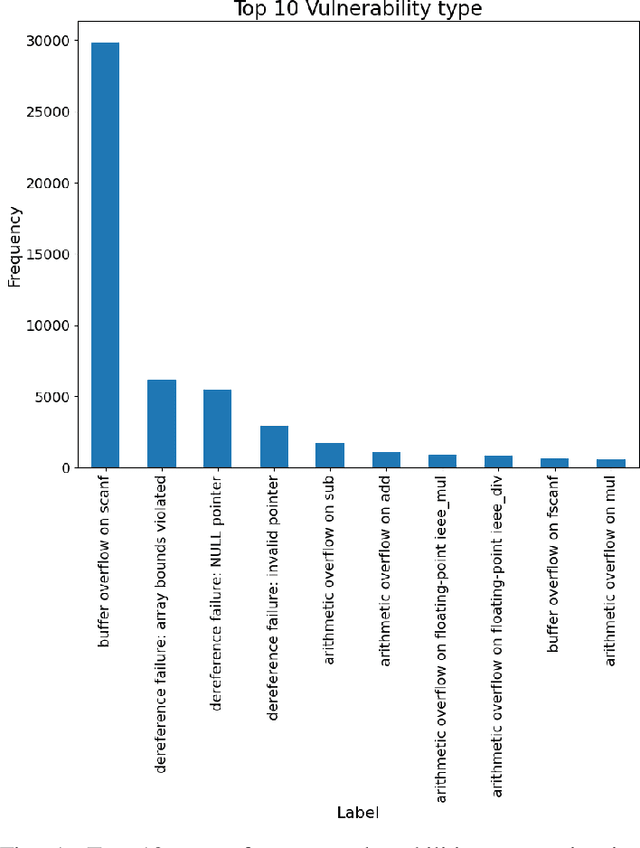
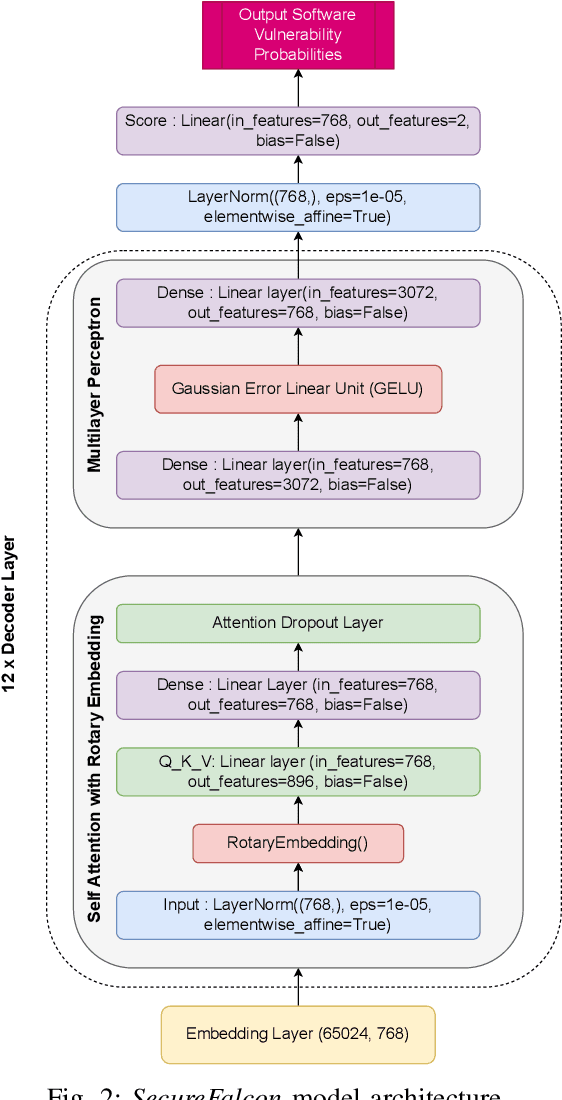
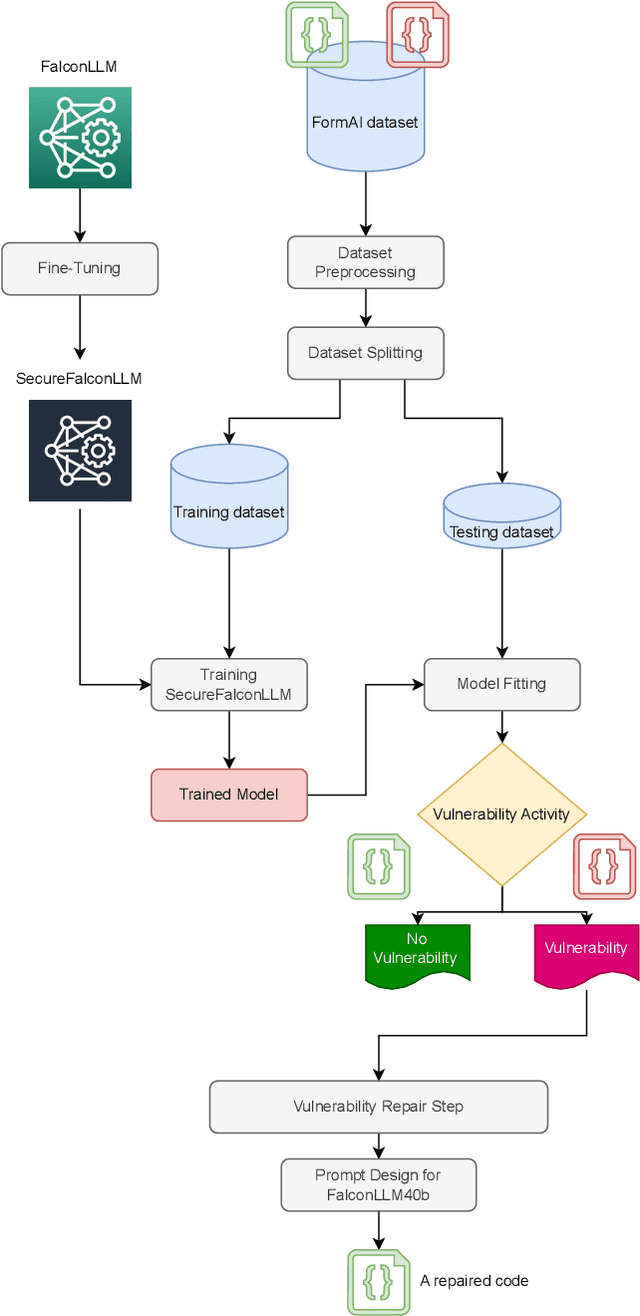
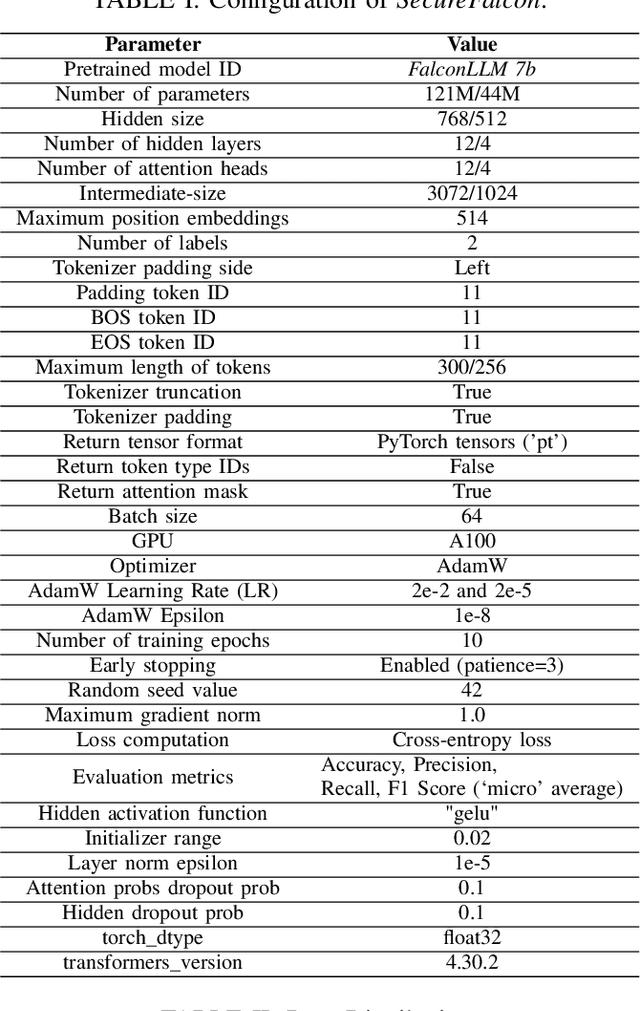
Software vulnerabilities leading to various detriments such as crashes, data loss, and security breaches, significantly hinder the quality, affecting the market adoption of software applications and systems. Although traditional methods such as automated software testing, fault localization, and repair have been intensively studied, static analysis tools are most commonly used and have an inherent false positives rate, posing a solid challenge to developer productivity. Large Language Models (LLMs) offer a promising solution to these persistent issues. Among these, FalconLLM has shown substantial potential in identifying intricate patterns and complex vulnerabilities, hence crucial in software vulnerability detection. In this paper, for the first time, FalconLLM is being fine-tuned for cybersecurity applications, thus introducing SecureFalcon, an innovative model architecture built upon FalconLLM. SecureFalcon is trained to differentiate between vulnerable and non-vulnerable C code samples. We build a new training dataset, FormAI, constructed thanks to Generative Artificial Intelligence (AI) and formal verification to evaluate its performance. SecureFalcon achieved an impressive 94% accuracy rate in detecting software vulnerabilities, emphasizing its significant potential to redefine software vulnerability detection methods in cybersecurity.
The FormAI Dataset: Generative AI in Software Security Through the Lens of Formal Verification
Jul 05, 2023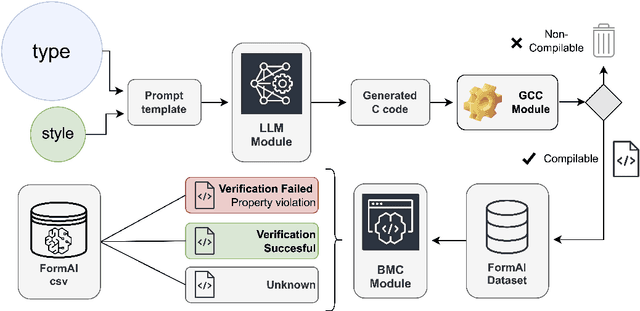
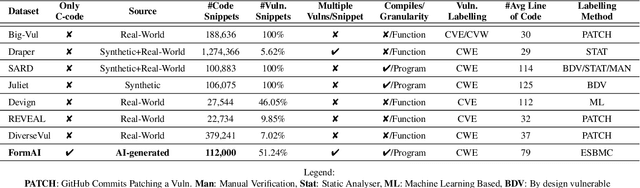

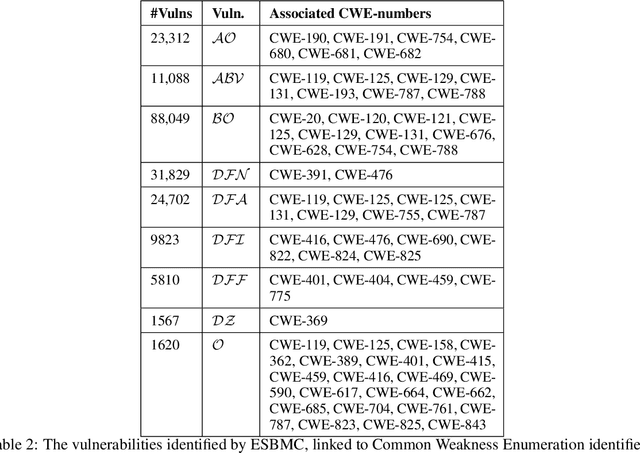
This paper presents the FormAI dataset, a large collection of 112,000 AI-generated compilable and independent C programs with vulnerability classification. We introduce a dynamic zero-shot prompting technique, constructed to spawn a diverse set of programs utilizing Large Language Models (LLMs). The dataset is generated by GPT-3.5-turbo and comprises programs with varying levels of complexity. Some programs handle complicated tasks such as network management, table games, or encryption, while others deal with simpler tasks like string manipulation. Every program is labeled with the vulnerabilities found within the source code, indicating the type, line number, and vulnerable function name. This is accomplished by employing a formal verification method using the Efficient SMT-based Bounded Model Checker (ESBMC), which performs model checking, abstract interpretation, constraint programming, and satisfiability modulo theories, to reason over safety/security properties in programs. This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports. This property of the dataset makes it suitable for evaluating the effectiveness of various static and dynamic analysis tools. Furthermore, we have associated the identified vulnerabilities with relevant Common Weakness Enumeration (CWE) numbers. We make the source code available for the 112,000 programs, accompanied by a comprehensive list detailing the vulnerabilities detected in each individual program including location and function name, which makes the dataset ideal to train LLMs and machine learning algorithms.
QNNRepair: Quantized Neural Network Repair
Jun 27, 2023We present QNNRepair, the first method in the literature for repairing quantized neural networks (QNNs). QNNRepair aims to improve the accuracy of a neural network model after quantization. It accepts the full-precision and weight-quantized neural networks and a repair dataset of passing and failing tests. At first, QNNRepair applies a software fault localization method to identify the neurons that cause performance degradation during neural network quantization. Then, it formulates the repair problem into a linear programming problem of solving neuron weights parameters, which corrects the QNN's performance on failing tests while not compromising its performance on passing tests. We evaluate QNNRepair with widely used neural network architectures such as MobileNetV2, ResNet, and VGGNet on popular datasets, including high-resolution images. We also compare QNNRepair with the state-of-the-art data-free quantization method SQuant. According to the experiment results, we conclude that QNNRepair is effective in improving the quantized model's performance in most cases. Its repaired models have 24% higher accuracy than SQuant's in the independent validation set, especially for the ImageNet dataset.
Revolutionizing Cyber Threat Detection with Large Language Models
Jun 25, 2023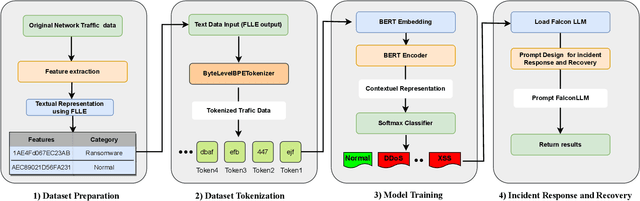

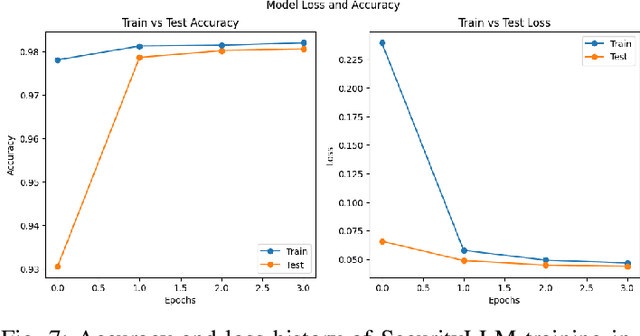
Natural Language Processing (NLP) domain is experiencing a revolution due to the capabilities of Pre-trained Large Language Models ( LLMs), fueled by ground-breaking Transformers architecture, resulting into unprecedented advancements. Their exceptional aptitude for assessing probability distributions of text sequences is the primary catalyst for outstanding improvement of both the precision and efficiency of NLP models. This paper introduces for the first time SecurityLLM, a pre-trained language model designed for cybersecurity threats detection. The SecurityLLM model is articulated around two key generative elements: SecurityBERT and FalconLLM. SecurityBERT operates as a cyber threat detection mechanism, while FalconLLM is an incident response and recovery system. To the best of our knowledge, SecurityBERT represents the inaugural application of BERT in cyber threat detection. Despite the unique nature of the input data and features, such as the reduced significance of syntactic structures in content classification, the suitability of BERT for this duty demonstrates unexpected potential, thanks to our pioneering study. We reveal that a simple classification model, created from scratch, and consolidated with LLMs, exceeds the performance of established traditional Machine Learning (ML) and Deep Learning (DL) methods in cyber threat detection, like Convolutional Neural Networks (CNN) or Recurrent Neural Networks (RNN). The experimental analysis, conducted using a collected cybersecurity dataset, proves that our SecurityLLM model can identify fourteen (14) different types of attacks with an overall accuracy of 98%
A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification
May 24, 2023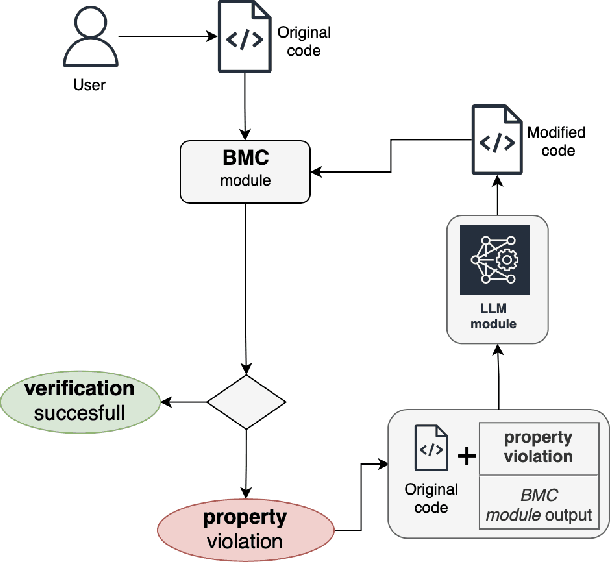
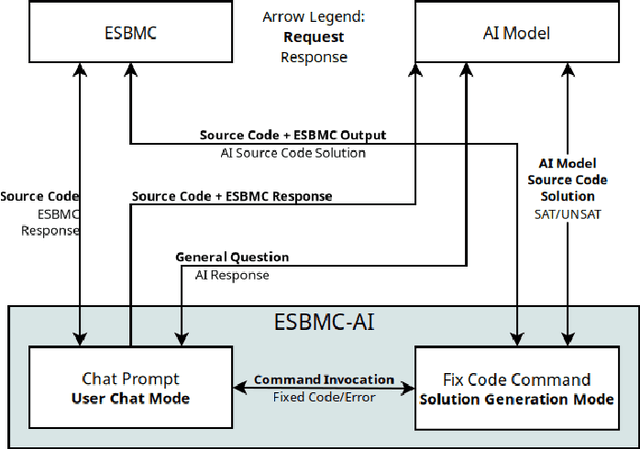
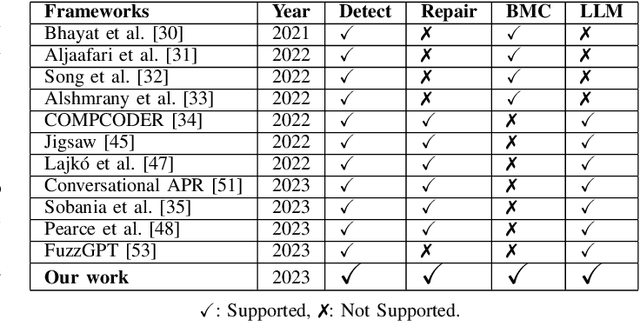
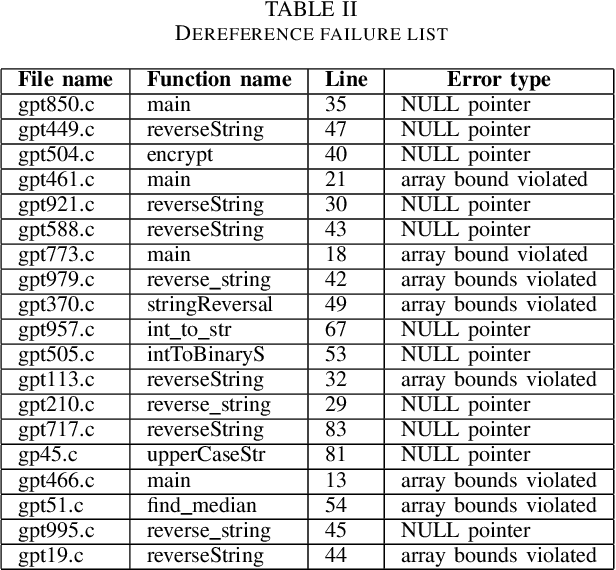
In this paper we present a novel solution that combines the capabilities of Large Language Models (LLMs) with Formal Verification strategies to verify and automatically repair software vulnerabilities. Initially, we employ Bounded Model Checking (BMC) to locate the software vulnerability and derive a counterexample. The counterexample provides evidence that the system behaves incorrectly or contains a vulnerability. The counterexample that has been detected, along with the source code, are provided to the LLM engine. Our approach involves establishing a specialized prompt language for conducting code debugging and generation to understand the vulnerability's root cause and repair the code. Finally, we use BMC to verify the corrected version of the code generated by the LLM. As a proof of concept, we create ESBMC-AI based on the Efficient SMT-based Context-Bounded Model Checker (ESBMC) and a pre-trained Transformer model, specifically gpt-3.5-turbo, to detect and fix errors in C programs. Our experimentation involved generating a dataset comprising 1000 C code samples, each consisting of 20 to 50 lines of code. Notably, our proposed method achieved an impressive success rate of up to 80% in repairing vulnerable code encompassing buffer overflow and pointer dereference failures. We assert that this automated approach can effectively incorporate into the software development lifecycle's continuous integration and deployment (CI/CD) process.
Poisoning Attacks in Federated Edge Learning for Digital Twin 6G-enabled IoTs: An Anticipatory Study
Mar 21, 2023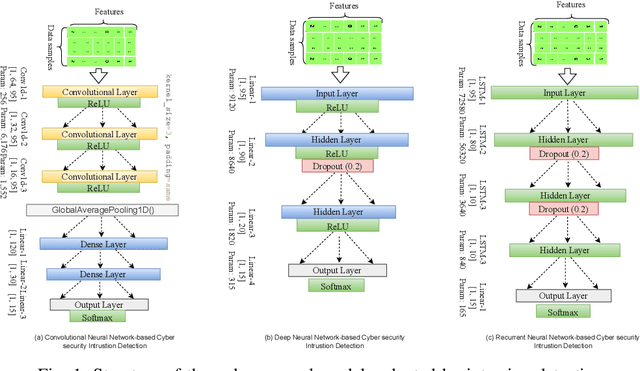
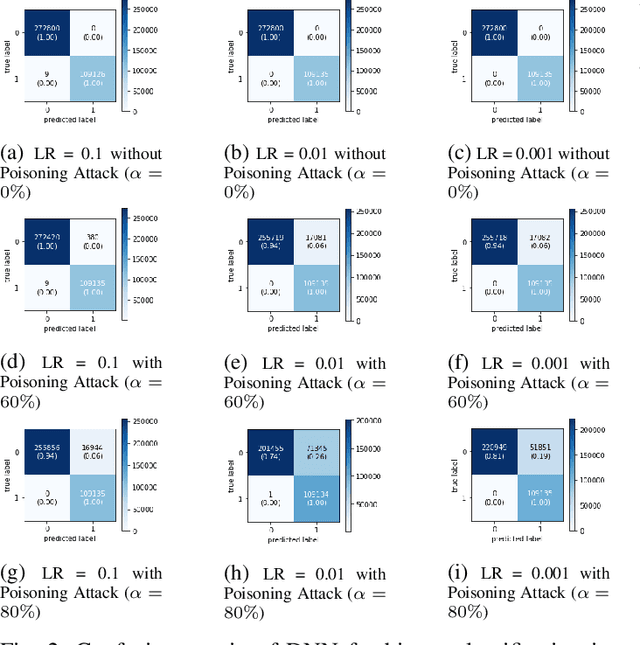
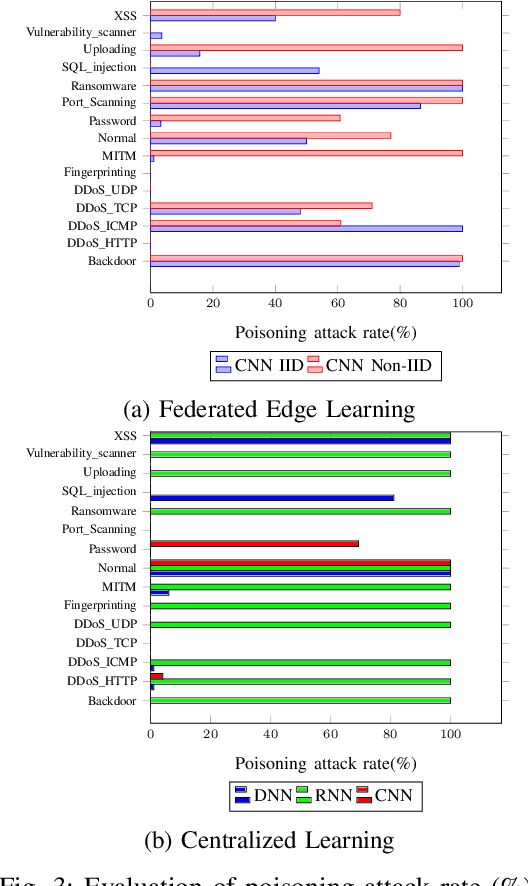
Federated edge learning can be essential in supporting privacy-preserving, artificial intelligence (AI)-enabled activities in digital twin 6G-enabled Internet of Things (IoT) environments. However, we need to also consider the potential of attacks targeting the underlying AI systems (e.g., adversaries seek to corrupt data on the IoT devices during local updates or corrupt the model updates); hence, in this article, we propose an anticipatory study for poisoning attacks in federated edge learning for digital twin 6G-enabled IoT environments. Specifically, we study the influence of adversaries on the training and development of federated learning models in digital twin 6G-enabled IoT environments. We demonstrate that attackers can carry out poisoning attacks in two different learning settings, namely: centralized learning and federated learning, and successful attacks can severely reduce the model's accuracy. We comprehensively evaluate the attacks on a new cyber security dataset designed for IoT applications with three deep neural networks under the non-independent and identically distributed (Non-IID) data and the independent and identically distributed (IID) data. The poisoning attacks, on an attack classification problem, can lead to a decrease in accuracy from 94.93% to 85.98% with IID data and from 94.18% to 30.04% with Non-IID.
LF-checker: Machine Learning Acceleration of Bounded Model Checking for Concurrency Verification (Competition Contribution)
Jan 22, 2023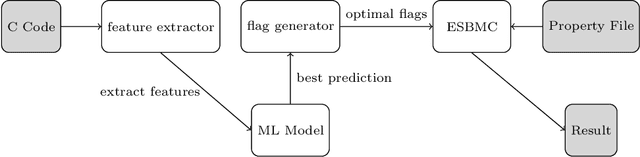
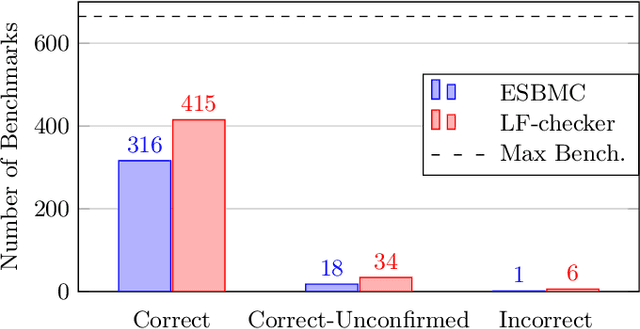

We describe and evaluate LF-checker, a metaverifier tool based on machine learning. It extracts multiple features of the program under test and predicts the optimal configuration (flags) of a bounded model checker with a decision tree. Our current work is specialised in concurrency verification and employs ESBMC as a back-end verification engine. In the paper, we demonstrate that LF-checker achieves better results than the default configuration of the underlying verification engine.
CEG4N: Counter-Example Guided Neural Network Quantization Refinement
Jul 09, 2022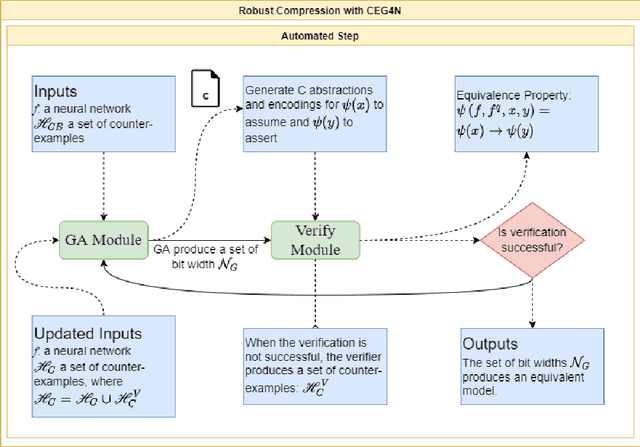
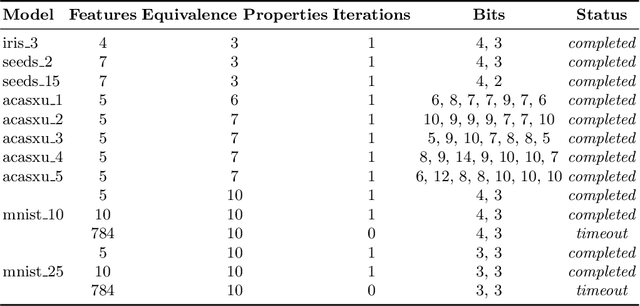
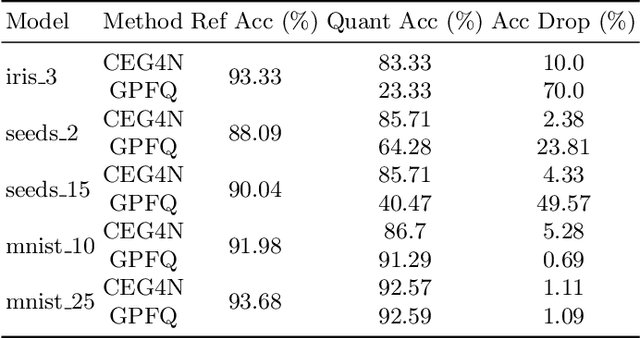
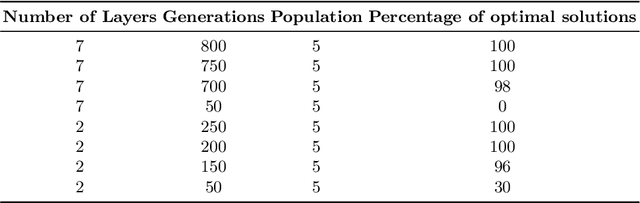
Neural networks are essential components of learning-based software systems. However, their high compute, memory, and power requirements make using them in low resources domains challenging. For this reason, neural networks are often quantized before deployment. Existing quantization techniques tend to degrade the network accuracy. We propose Counter-Example Guided Neural Network Quantization Refinement (CEG4N). This technique combines search-based quantization and equivalence verification: the former minimizes the computational requirements, while the latter guarantees that the network's output does not change after quantization. We evaluate CEG4N~on a diverse set of benchmarks, including large and small networks. Our technique successfully quantizes the networks in our evaluation while producing models with up to 72% better accuracy than state-of-the-art techniques.