 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRidhi Jain
Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models
Apr 29, 2024
This study provides a comparative analysis of state-of-the-art large language models (LLMs), analyzing how likely they generate vulnerabilities when writing simple C programs using a neutral zero-shot prompt. We address a significant gap in the literature concerning the security properties of code produced by these models without specific directives. N. Tihanyi et al. introduced the FormAI dataset at PROMISE '23, containing 112,000 GPT-3.5-generated C programs, with over 51.24% identified as vulnerable. We expand that work by introducing the FormAI-v2 dataset comprising 265,000 compilable C programs generated using various LLMs, including robust models such as Google's GEMINI-pro, OpenAI's GPT-4, and TII's 180 billion-parameter Falcon, to Meta's specialized 13 billion-parameter CodeLLama2 and various other compact models. Each program in the dataset is labelled based on the vulnerabilities detected in its source code through formal verification using the Efficient SMT-based Context-Bounded Model Checker (ESBMC). This technique eliminates false positives by delivering a counterexample and ensures the exclusion of false negatives by completing the verification process. Our study reveals that at least 63.47% of the generated programs are vulnerable. The differences between the models are minor, as they all display similar coding errors with slight variations. Our research highlights that while LLMs offer promising capabilities for code generation, deploying their output in a production environment requires risk assessment and validation.
CyberMetric: A Benchmark Dataset for Evaluating Large Language Models Knowledge in Cybersecurity
Feb 12, 2024Large Language Models (LLMs) excel across various domains, from computer vision to medical diagnostics. However, understanding the diverse landscape of cybersecurity, encompassing cryptography, reverse engineering, and managerial facets like risk assessment, presents a challenge, even for human experts. In this paper, we introduce CyberMetric, a benchmark dataset comprising 10,000 questions sourced from standards, certifications, research papers, books, and other publications in the cybersecurity domain. The questions are created through a collaborative process, i.e., merging expert knowledge with LLMs, including GPT-3.5 and Falcon-180B. Human experts spent over 200 hours verifying their accuracy and relevance. Beyond assessing LLMs' knowledge, the dataset's main goal is to facilitate a fair comparison between humans and different LLMs in cybersecurity. To achieve this, we carefully selected 80 questions covering a wide range of topics within cybersecurity and involved 30 participants of diverse expertise levels, facilitating a comprehensive comparison between human and machine intelligence in this area. The findings revealed that LLMs outperformed humans in almost every aspect of cybersecurity.
The FormAI Dataset: Generative AI in Software Security Through the Lens of Formal Verification
Jul 05, 2023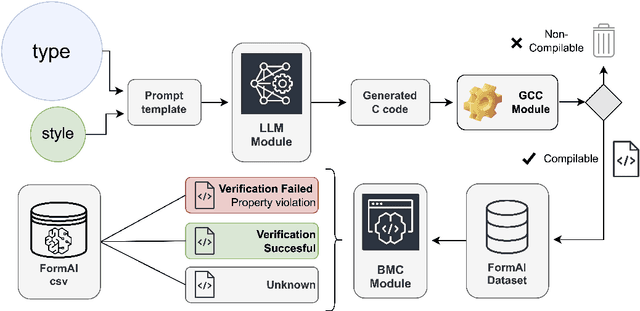
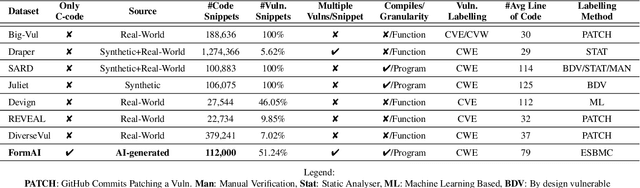

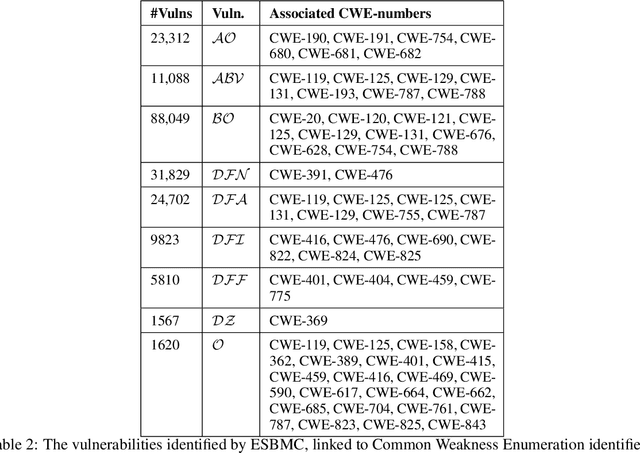
This paper presents the FormAI dataset, a large collection of 112,000 AI-generated compilable and independent C programs with vulnerability classification. We introduce a dynamic zero-shot prompting technique, constructed to spawn a diverse set of programs utilizing Large Language Models (LLMs). The dataset is generated by GPT-3.5-turbo and comprises programs with varying levels of complexity. Some programs handle complicated tasks such as network management, table games, or encryption, while others deal with simpler tasks like string manipulation. Every program is labeled with the vulnerabilities found within the source code, indicating the type, line number, and vulnerable function name. This is accomplished by employing a formal verification method using the Efficient SMT-based Bounded Model Checker (ESBMC), which performs model checking, abstract interpretation, constraint programming, and satisfiability modulo theories, to reason over safety/security properties in programs. This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports. This property of the dataset makes it suitable for evaluating the effectiveness of various static and dynamic analysis tools. Furthermore, we have associated the identified vulnerabilities with relevant Common Weakness Enumeration (CWE) numbers. We make the source code available for the 112,000 programs, accompanied by a comprehensive list detailing the vulnerabilities detected in each individual program including location and function name, which makes the dataset ideal to train LLMs and machine learning algorithms.
A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification
May 24, 2023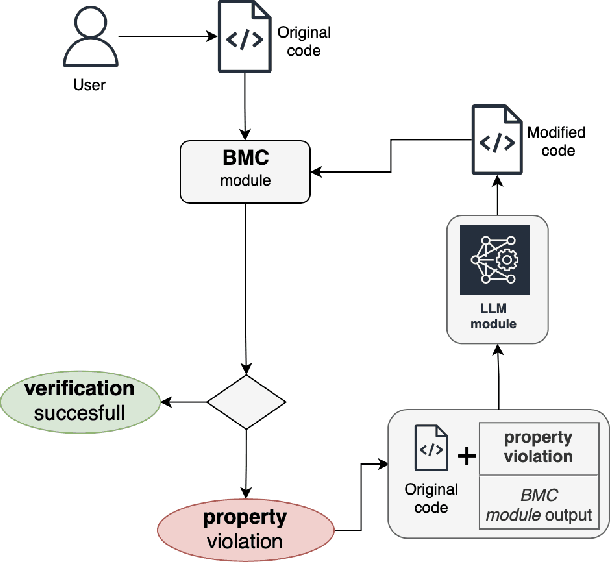
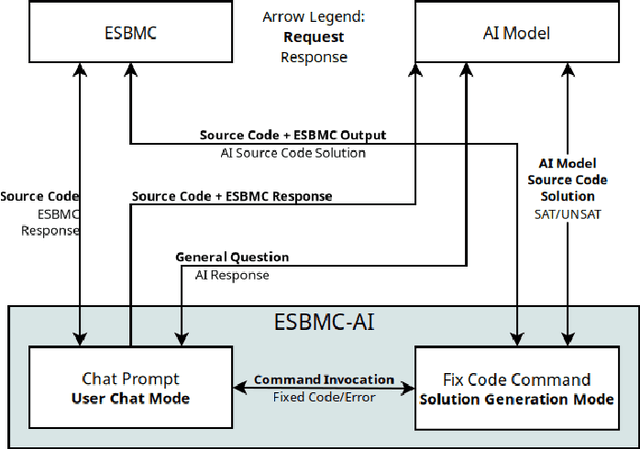
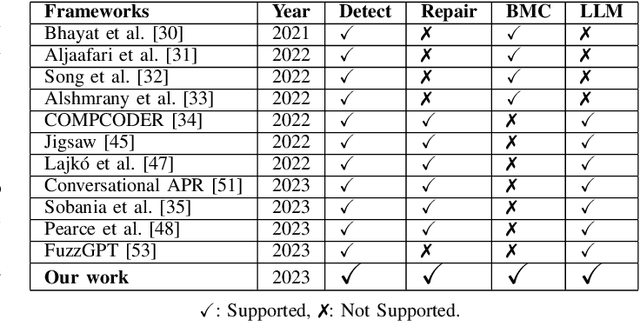
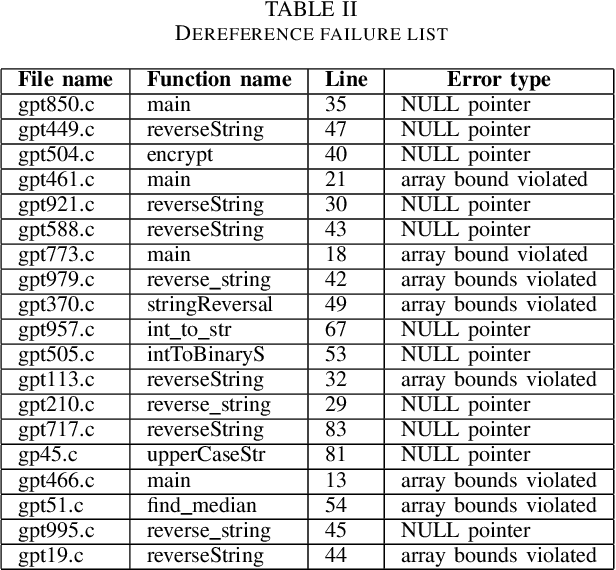
In this paper we present a novel solution that combines the capabilities of Large Language Models (LLMs) with Formal Verification strategies to verify and automatically repair software vulnerabilities. Initially, we employ Bounded Model Checking (BMC) to locate the software vulnerability and derive a counterexample. The counterexample provides evidence that the system behaves incorrectly or contains a vulnerability. The counterexample that has been detected, along with the source code, are provided to the LLM engine. Our approach involves establishing a specialized prompt language for conducting code debugging and generation to understand the vulnerability's root cause and repair the code. Finally, we use BMC to verify the corrected version of the code generated by the LLM. As a proof of concept, we create ESBMC-AI based on the Efficient SMT-based Context-Bounded Model Checker (ESBMC) and a pre-trained Transformer model, specifically gpt-3.5-turbo, to detect and fix errors in C programs. Our experimentation involved generating a dataset comprising 1000 C code samples, each consisting of 20 to 50 lines of code. Notably, our proposed method achieved an impressive success rate of up to 80% in repairing vulnerable code encompassing buffer overflow and pointer dereference failures. We assert that this automated approach can effectively incorporate into the software development lifecycle's continuous integration and deployment (CI/CD) process.