 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuping Ji
Weakly-Supervised Residual Evidential Learning for Multi-Instance Uncertainty Estimation
May 07, 2024
Uncertainty estimation (UE), as an effective means of quantifying predictive uncertainty, is crucial for safe and reliable decision-making, especially in high-risk scenarios. Existing UE schemes usually assume that there are completely-labeled samples to support fully-supervised learning. In practice, however, many UE tasks often have no sufficiently-labeled data to use, such as the Multiple Instance Learning (MIL) with only weak instance annotations. To bridge this gap, this paper, for the first time, addresses the weakly-supervised issue of Multi-Instance UE (MIUE) and proposes a new baseline scheme, Multi-Instance Residual Evidential Learning (MIREL). Particularly, at the fine-grained instance UE with only weak supervision, we derive a multi-instance residual operator through the Fundamental Theorem of Symmetric Functions. On this operator derivation, we further propose MIREL to jointly model the high-order predictive distribution at bag and instance levels for MIUE. Extensive experiments empirically demonstrate that our MIREL not only could often make existing MIL networks perform better in MIUE, but also could surpass representative UE methods by large margins, especially in instance-level UE tasks.
Pseudo-Bag Mixup Augmentation for Multiple Instance Learning-Based Whole Slide Image Classification
Jul 03, 2023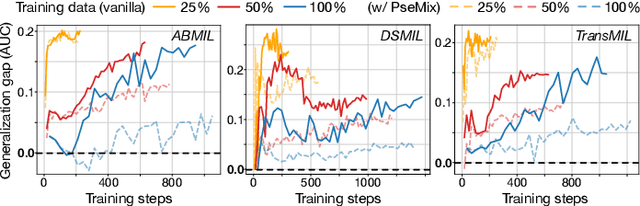

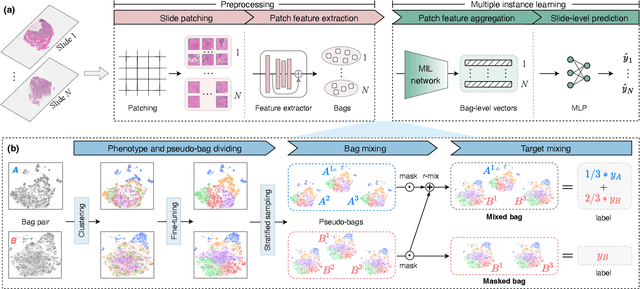
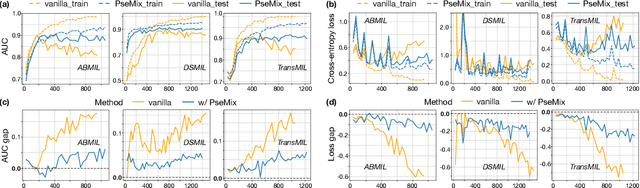
Given the special situation of modeling gigapixel images, multiple instance learning (MIL) has become one of the most important frameworks for Whole Slide Image (WSI) classification. In current practice, most MIL networks often face two unavoidable problems in training: i) insufficient WSI data, and ii) the sample memorization inclination inherent in neural networks. These problems may hinder MIL models from adequate and efficient training, suppressing the continuous performance promotion of classification models on WSIs. Inspired by the basic idea of Mixup, this paper proposes a new Pseudo-bag Mixup (PseMix) data augmentation scheme to improve the training of MIL models. This scheme generalizes the Mixup strategy for general images to special WSIs via pseudo-bags so as to be applied in MIL-based WSI classification. Cooperated by pseudo-bags, our PseMix fulfills the critical size alignment and semantic alignment in Mixup strategy. Moreover, it is designed as an efficient and decoupled method, neither involving time-consuming operations nor relying on MIL model predictions. Comparative experiments and ablation studies are specially designed to evaluate the effectiveness and advantages of our PseMix. Experimental results show that PseMix could often assist state-of-the-art MIL networks to refresh the classification performance on WSIs. Besides, it could also boost the generalization ability of MIL models, and promote their robustness to patch occlusion and noisy labels. Our source code is available at https://github.com/liupei101/PseMix.
ProtoDiv: Prototype-guided Division of Consistent Pseudo-bags for Whole-slide Image Classification
Apr 13, 2023
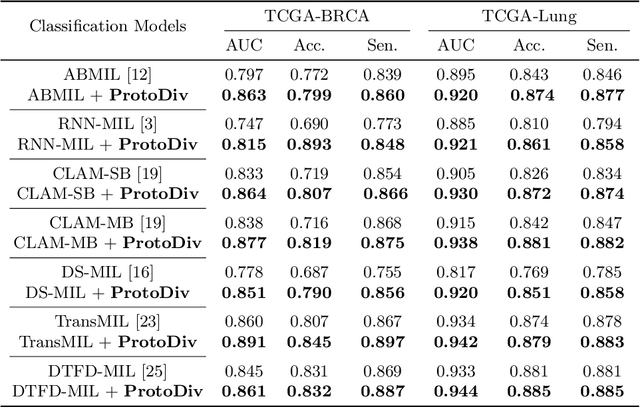
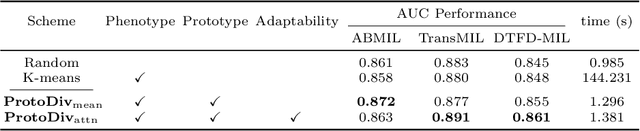
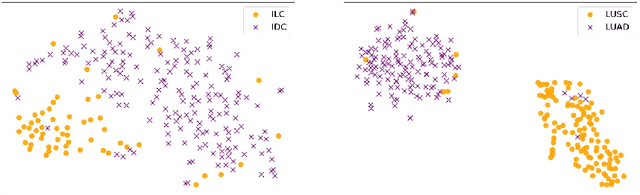
Due to the limitations of inadequate Whole-Slide Image (WSI) samples with weak labels, pseudo-bag-based multiple instance learning (MIL) appears as a vibrant prospect in WSI classification. However, the pseudo-bag dividing scheme, often crucial for classification performance, is still an open topic worth exploring. Therefore, this paper proposes a novel scheme, ProtoDiv, using a bag prototype to guide the division of WSI pseudo-bags. Rather than designing complex network architecture, this scheme takes a plugin-and-play approach to safely augment WSI data for effective training while preserving sample consistency. Furthermore, we specially devise an attention-based prototype that could be optimized dynamically in training to adapt to a classification task. We apply our ProtoDiv scheme on seven baseline models, and then carry out a group of comparison experiments on two public WSI datasets. Experiments confirm our ProtoDiv could usually bring obvious performance improvements to WSI classification.
Shared Coupling-bridge for Weakly Supervised Local Feature Learning
Dec 14, 2022

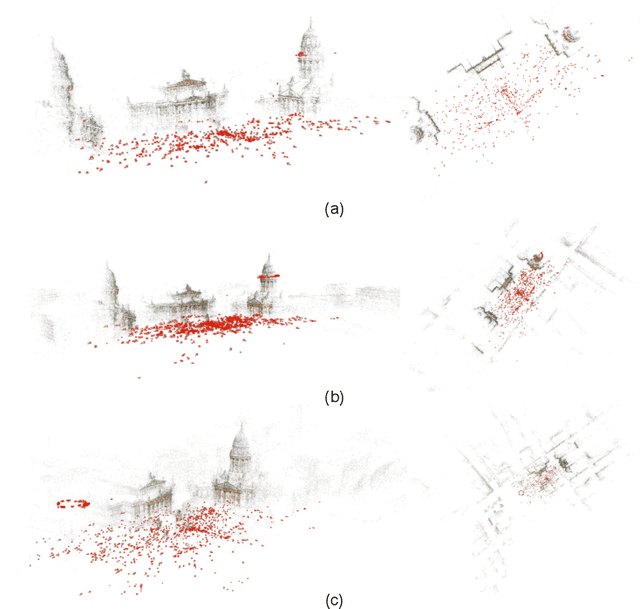
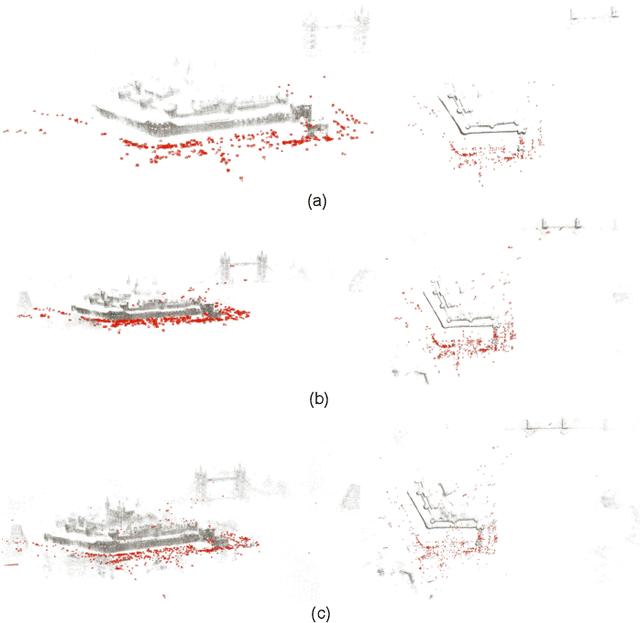
Sparse local feature extraction is usually believed to be of important significance in typical vision tasks such as simultaneous localization and mapping, image matching and 3D reconstruction. At present, it still has some deficiencies needing further improvement, mainly including the discrimination power of extracted local descriptors, the localization accuracy of detected keypoints, and the efficiency of local feature learning. This paper focuses on promoting the currently popular sparse local feature learning with camera pose supervision. Therefore, it pertinently proposes a Shared Coupling-bridge scheme with four light-weight yet effective improvements for weakly-supervised local feature (SCFeat) learning. It mainly contains: i) the \emph{Feature-Fusion-ResUNet Backbone} (F2R-Backbone) for local descriptors learning, ii) a shared coupling-bridge normalization to improve the decoupling training of description network and detection network, iii) an improved detection network with peakiness measurement to detect keypoints and iv) the fundamental matrix error as a reward factor to further optimize feature detection training. Extensive experiments prove that our SCFeat improvement is effective. It could often obtain a state-of-the-art performance on classic image matching and visual localization. In terms of 3D reconstruction, it could still achieve competitive results. For sharing and communication, our source codes are available at https://github.com/sunjiayuanro/SCFeat.git.
AdvMIL: Adversarial Multiple Instance Learning for the Survival Analysis on Whole-Slide Images
Dec 13, 2022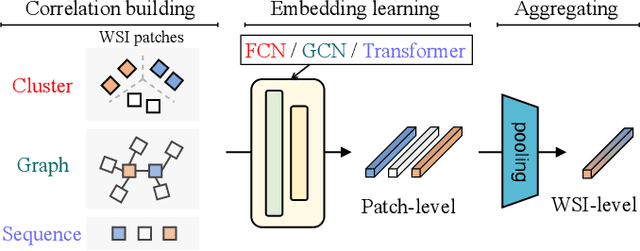
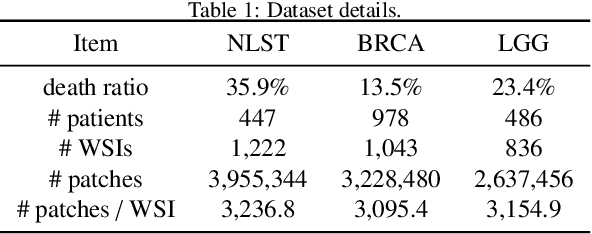
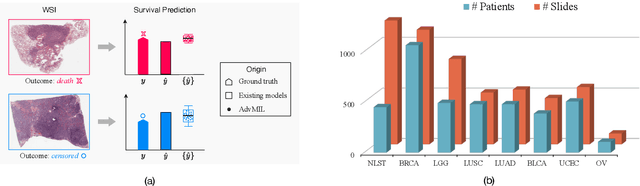

The survival analysis on histological whole-slide images (WSIs) is one of the most important means to estimate patient prognosis. Although many weakly-supervised deep learning models have been developed for gigapixel WSIs, their potential is generally restricted by classical survival analysis rules and fully-supervision requirements. As a result, these models provide patients only with a completely-certain point estimation of time-to-event, and they could only learn from the well-annotated WSI data currently at a small scale. To tackle these problems, we propose a novel adversarial multiple instance learning (AdvMIL) framework. This framework is based on adversarial time-to-event modeling, and it integrates the multiple instance learning (MIL) that is much necessary for WSI representation learning. It is a plug-and-play one, so that most existing WSI-based models with embedding-level MIL networks can be easily upgraded by applying this framework, gaining the improved ability of survival distribution estimation and semi-supervised learning. Our extensive experiments show that AdvMIL could not only bring performance improvement to mainstream WSI models at a relatively low computational cost, but also enable these models to learn from unlabeled data with semi-supervised learning. Our AdvMIL framework could promote the research of time-to-event modeling in computational pathology with its novel paradigm of adversarial MIL.
Dual-Stream Transformer with Cross-Attention on Whole-Slide Image Pyramids for Cancer Prognosis
Jun 22, 2022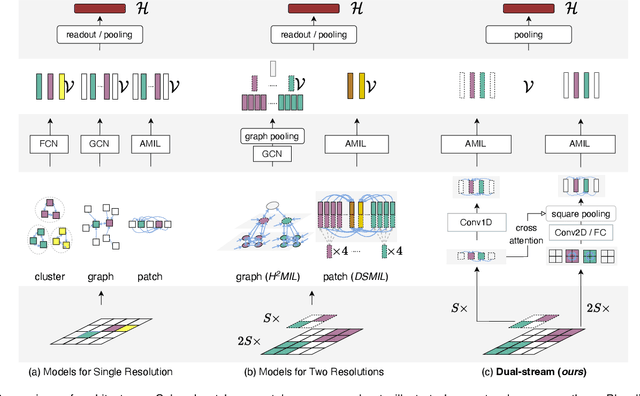
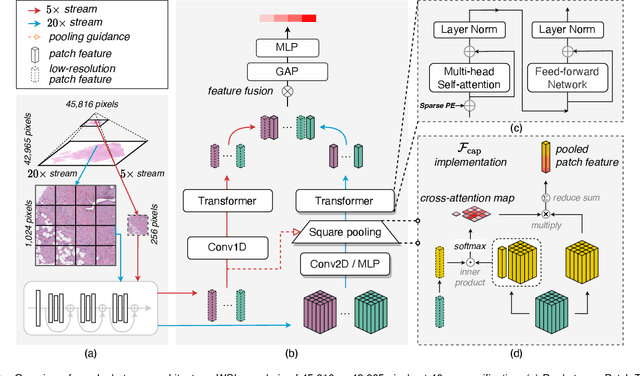
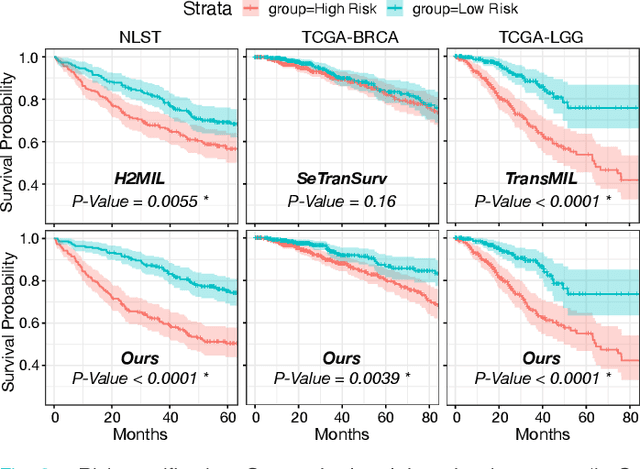
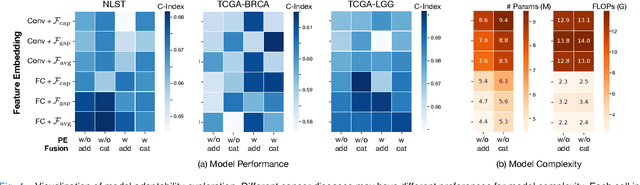
The cancer prognosis on gigapixel Whole-Slide Images (WSIs) has always been a challenging task. Most existing approaches focus solely on single-resolution images. The multi-resolution schemes, utilizing image pyramids to enhance WSI visual representations, have not yet been paid enough attention to. In order to explore a multi-resolution solution for improving cancer prognosis accuracy, this paper proposes a dual-stream architecture to model WSIs by an image pyramid strategy. This architecture consists of two sub-streams: one for low-resolution WSIs, and the other especially for high-resolution ones. Compared to other approaches, our scheme has three highlights: (i) there exists a one-to-one relation between stream and resolution; (ii) a square pooling layer is added to align the patches from two resolution streams, largely reducing computation cost and enabling a natural stream feature fusion; (iii) a cross-attention-based method is proposed to pool high-resolution patches spatially under the guidance of low-resolution ones. We validate our scheme on three publicly-available datasets with a total number of 3,101 WSIs from 1,911 patients. Experimental results verify that (i) hierarchical dual-stream representation is more effective than single-stream ones for cancer prognosis, gaining an average C-Index rise of 5.0% and 1.8% on a single low-resolution and high-resolution stream, respectively; (ii) our dual-stream scheme could outperform current state-of-the-art ones, by an average C-Index improvement of 5.1%; (iii) the cancer diseases with observable survival differences could have different preferences for model complexity. Our scheme could serve as an alternative tool for further facilitating WSI prognosis research.
Geometry Attention Transformer with Position-aware LSTMs for Image Captioning
Oct 01, 2021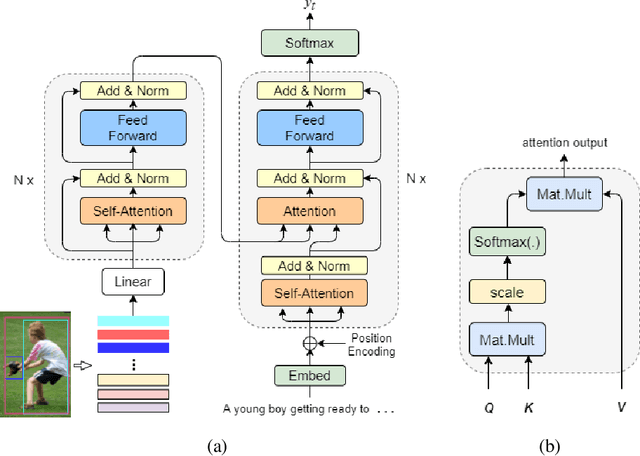
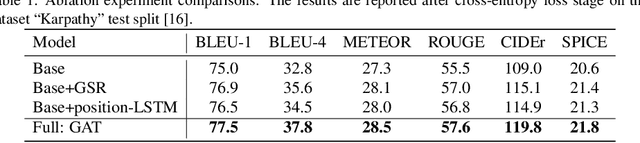
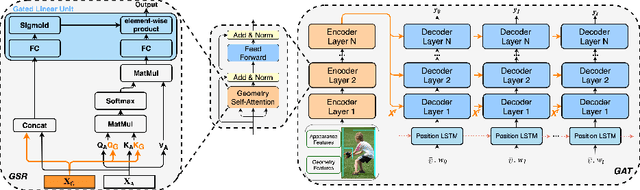
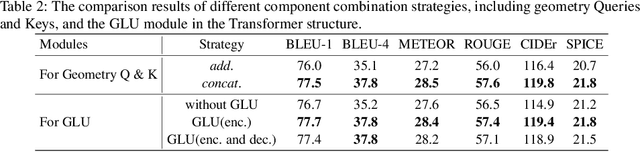
In recent years, transformer structures have been widely applied in image captioning with impressive performance. For good captioning results, the geometry and position relations of different visual objects are often thought of as crucial information. Aiming to further promote image captioning by transformers, this paper proposes an improved Geometry Attention Transformer (GAT) model. In order to further leverage geometric information, two novel geometry-aware architectures are designed respectively for the encoder and decoder in our GAT. Besides, this model includes the two work modules: 1) a geometry gate-controlled self-attention refiner, for explicitly incorporating relative spatial information into image region representations in encoding steps, and 2) a group of position-LSTMs, for precisely informing the decoder of relative word position in generating caption texts. The experiment comparisons on the datasets MS COCO and Flickr30K show that our GAT is efficient, and it could often outperform current state-of-the-art image captioning models.
Multi-view Subspace Clustering via Partition Fusion
Dec 03, 2019
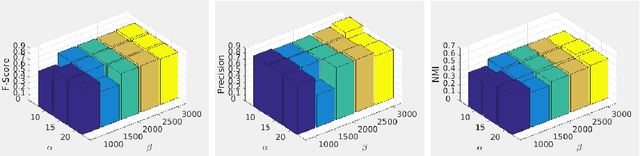
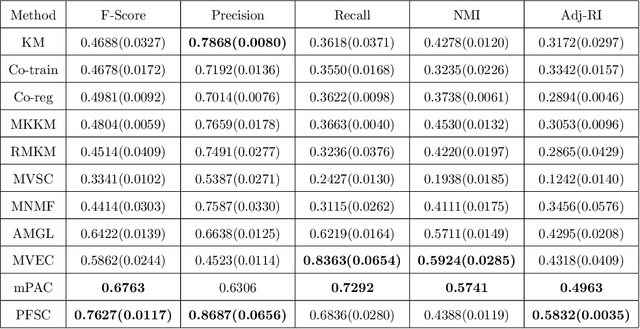

Multi-view clustering is an important approach to analyze multi-view data in an unsupervised way. Among various methods, the multi-view subspace clustering approach has gained increasing attention due to its encouraging performance. Basically, it integrates multi-view information into graphs, which are then fed into spectral clustering algorithm for final result. However, its performance may degrade due to noises existing in each individual view or inconsistency between heterogeneous features. Orthogonal to current work, we propose to fuse multi-view information in a partition space, which enhances the robustness of Multi-view clustering. Specifically, we generate multiple partitions and integrate them to find the shared partition. The proposed model unifies graph learning, generation of basic partitions, and view weight learning. These three components co-evolve towards better quality outputs. We have conducted comprehensive experiments on benchmark datasets and our empirical results verify the effectiveness and robustness of our approach.