 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMajed El Helou
VerA: Versatile Anonymization Fit for Clinical Facial Images
Dec 04, 2023
The escalating legislative demand for data privacy in facial image dissemination has underscored the significance of image anonymization. Recent advancements in the field surpass traditional pixelation or blur methods, yet they predominantly address regular single images. This leaves clinical image anonymization -- a necessity for illustrating medical interventions -- largely unaddressed. We present VerA, a versatile facial image anonymization that is fit for clinical facial images where: (1) certain semantic areas must be preserved to show medical intervention results, and (2) anonymizing image pairs is crucial for showing before-and-after results. VerA outperforms or is on par with state-of-the-art methods in de-identification and photorealism for regular images. In addition, we validate our results on paired anonymization, and on the anonymization of both single and paired clinical images with extensive quantitative and qualitative evaluation.
Fuzzy-Conditioned Diffusion and Diffusion Projection Attention Applied to Facial Image Correction
Jul 01, 2023

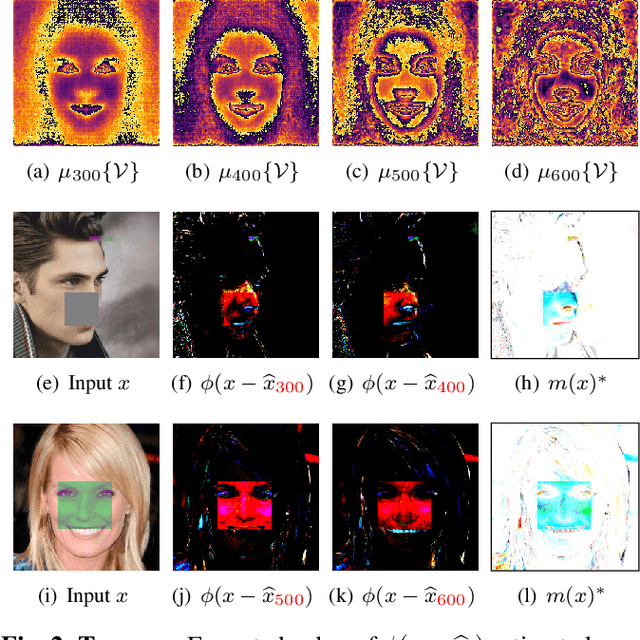
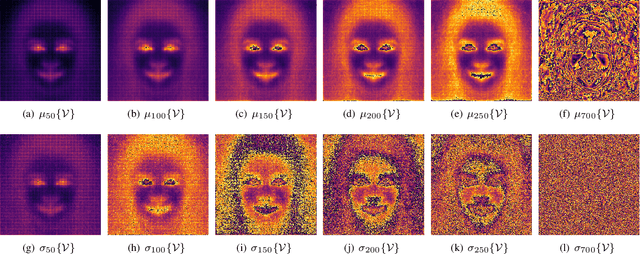
Image diffusion has recently shown remarkable performance in image synthesis and implicitly as an image prior. Such a prior has been used with conditioning to solve the inpainting problem, but only supporting binary user-based conditioning. We derive a fuzzy-conditioned diffusion, where implicit diffusion priors can be exploited with controllable strength. Our fuzzy conditioning can be applied pixel-wise, enabling the modification of different image components to varying degrees. Additionally, we propose an application to facial image correction, where we combine our fuzzy-conditioned diffusion with diffusion-derived attention maps. Our map estimates the degree of anomaly, and we obtain it by projecting on the diffusion space. We show how our approach also leads to interpretable and autonomous facial image correction.
PoGaIN: Poisson-Gaussian Image Noise Modeling from Paired Samples
Oct 10, 2022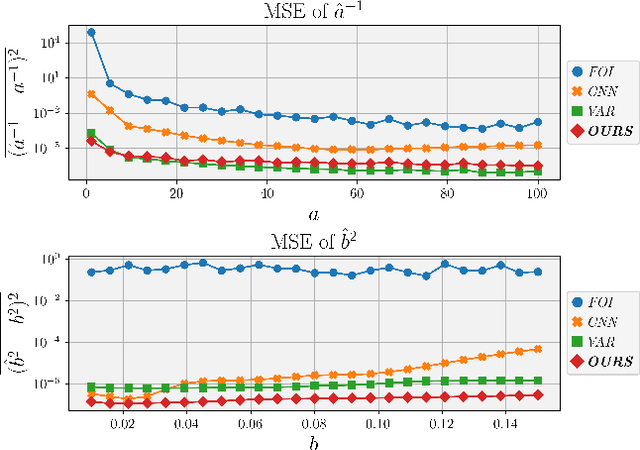
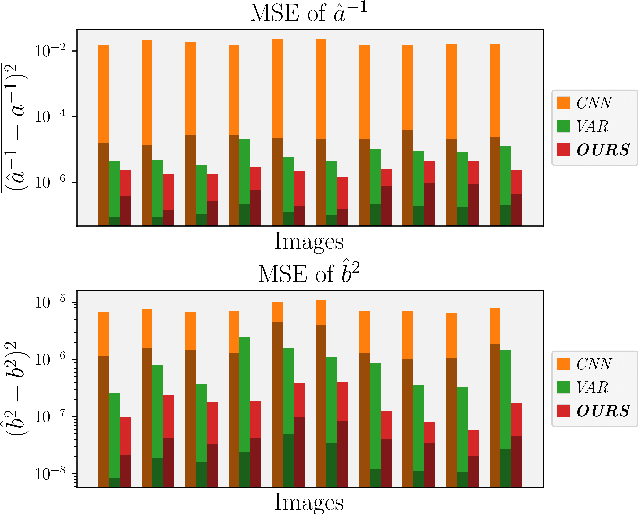
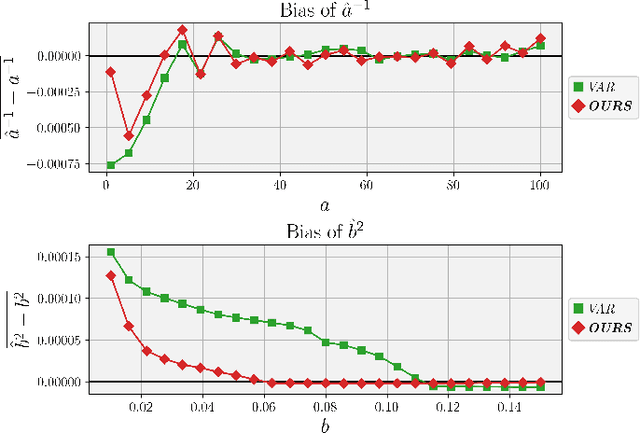

Image noise can often be accurately fitted to a Poisson-Gaussian distribution. However, estimating the distribution parameters from only a noisy image is a challenging task. Here, we study the case when paired noisy and noise-free samples are available. No method is currently available to exploit the noise-free information, which holds the promise of achieving more accurate estimates. To fill this gap, we derive a novel, cumulant-based, approach for Poisson-Gaussian noise modeling from paired image samples. We show its improved performance over different baselines with special emphasis on MSE, effect of outliers, image dependence and bias, and additionally derive the log-likelihood function for further insight and discuss real-world applicability.
DSR: Towards Drone Image Super-Resolution
Aug 25, 2022
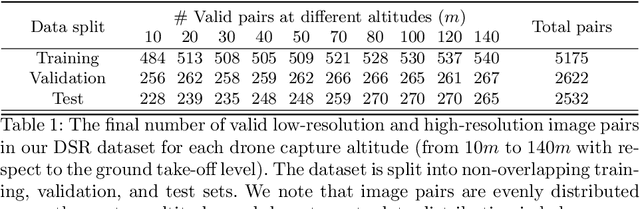

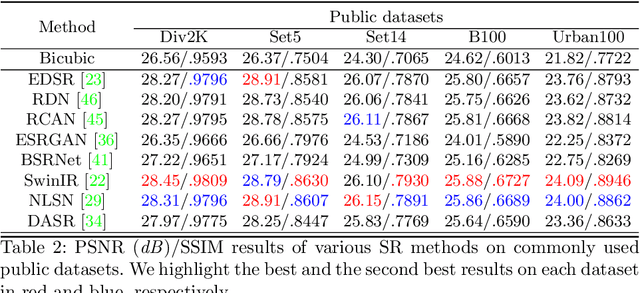
Despite achieving remarkable progress in recent years, single-image super-resolution methods are developed with several limitations. Specifically, they are trained on fixed content domains with certain degradations (whether synthetic or real). The priors they learn are prone to overfitting the training configuration. Therefore, the generalization to novel domains such as drone top view data, and across altitudes, is currently unknown. Nonetheless, pairing drones with proper image super-resolution is of great value. It would enable drones to fly higher covering larger fields of view, while maintaining a high image quality. To answer these questions and pave the way towards drone image super-resolution, we explore this application with particular focus on the single-image case. We propose a novel drone image dataset, with scenes captured at low and high resolutions, and across a span of altitudes. Our results show that off-the-shelf state-of-the-art networks witness a significant drop in performance on this different domain. We additionally show that simple fine-tuning, and incorporating altitude awareness into the network's architecture, both improve the reconstruction performance.
Image Denoising with Control over Deep Network Hallucination
Jan 02, 2022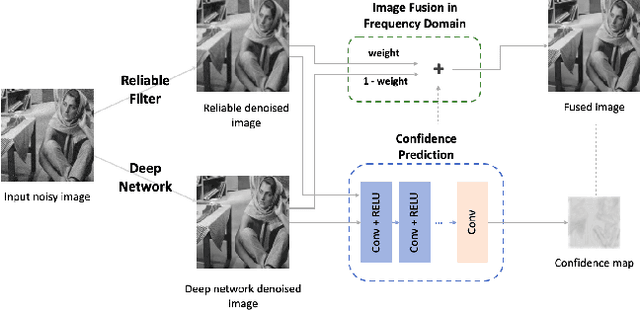
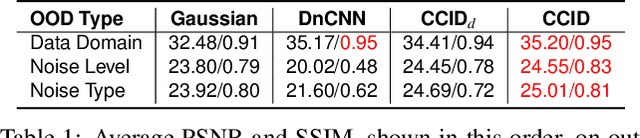

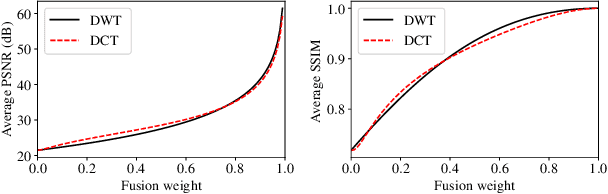
Deep image denoisers achieve state-of-the-art results but with a hidden cost. As witnessed in recent literature, these deep networks are capable of overfitting their training distributions, causing inaccurate hallucinations to be added to the output and generalizing poorly to varying data. For better control and interpretability over a deep denoiser, we propose a novel framework exploiting a denoising network. We call it controllable confidence-based image denoising (CCID). In this framework, we exploit the outputs of a deep denoising network alongside an image convolved with a reliable filter. Such a filter can be a simple convolution kernel which does not risk adding hallucinated information. We propose to fuse the two components with a frequency-domain approach that takes into account the reliability of the deep network outputs. With our framework, the user can control the fusion of the two components in the frequency domain. We also provide a user-friendly map estimating spatially the confidence in the output that potentially contains network hallucination. Results show that our CCID not only provides more interpretability and control, but can even outperform both the quantitative performance of the deep denoiser and that of the reliable filter, especially when the test data diverge from the training data.
Fidelity Estimation Improves Noisy-Image Classification with Pretrained Networks
Jun 01, 2021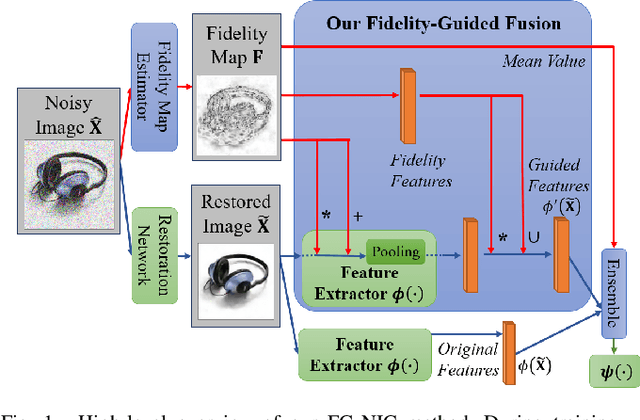

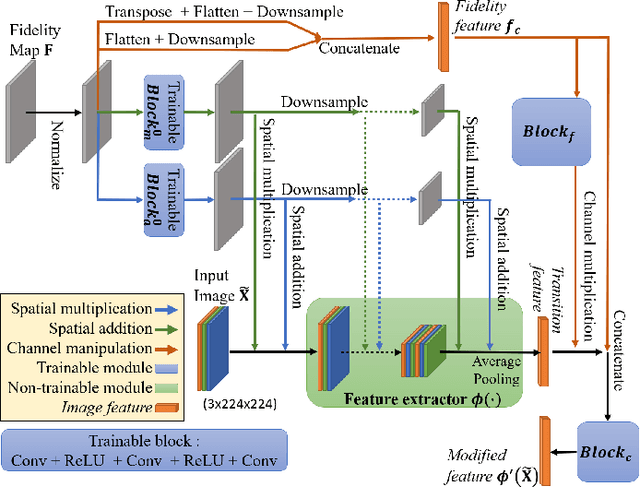

Image classification has significantly improved using deep learning. This is mainly due to convolutional neural networks (CNNs) that are capable of learning rich feature extractors from large datasets. However, most deep learning classification methods are trained on clean images and are not robust when handling noisy ones, even if a restoration preprocessing step is applied. While novel methods address this problem, they rely on modified feature extractors and thus necessitate retraining. We instead propose a method that can be applied on a pretrained classifier. Our method exploits a fidelity map estimate that is fused into the internal representations of the feature extractor, thereby guiding the attention of the network and making it more robust to noisy data. We improve the noisy-image classification (NIC) results by significantly large margins, especially at high noise levels, and come close to the fully retrained approaches. Furthermore, as proof of concept, we show that when using our oracle fidelity map we even outperform the fully retrained methods, whether trained on noisy or restored images.
NTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021

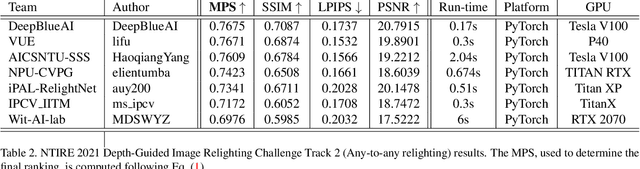

Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
Deep Gaussian Denoiser Epistemic Uncertainty and Decoupled Dual-Attention Fusion
Jan 22, 2021
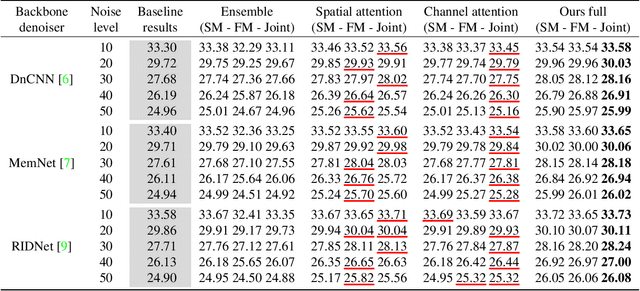


Following the performance breakthrough of denoising networks, improvements have come chiefly through novel architecture designs and increased depth. While novel denoising networks were designed for real images coming from different distributions, or for specific applications, comparatively small improvement was achieved on Gaussian denoising. The denoising solutions suffer from epistemic uncertainty that can limit further advancements. This uncertainty is traditionally mitigated through different ensemble approaches. However, such ensembles are prohibitively costly with deep networks, which are already large in size. Our work focuses on pushing the performance limits of state-of-the-art methods on Gaussian denoising. We propose a model-agnostic approach for reducing epistemic uncertainty while using only a single pretrained network. We achieve this by tapping into the epistemic uncertainty through augmented and frequency-manipulated images to obtain denoised images with varying error. We propose an ensemble method with two decoupled attention paths, over the pixel domain and over that of our different manipulations, to learn the final fusion. Our results significantly improve over the state-of-the-art baselines and across varying noise levels.
BIGPrior: Towards Decoupling Learned Prior Hallucination and Data Fidelity in Image Restoration
Nov 03, 2020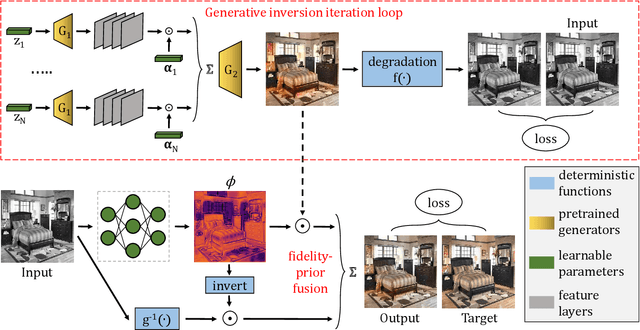



Image restoration encompasses fundamental image processing tasks that have been addressed with different algorithms and deep learning methods. Classical restoration algorithms leverage a variety of priors, either implicitly or explicitly. Their priors are hand-designed and their corresponding weights are heuristically assigned. Thus, deep learning methods often produce superior restoration quality. Deep networks are, however, capable of strong and hardly-predictable hallucinations. Networks jointly and implicitly learn to be faithful to the observed data while learning an image prior, and the separation of original and hallucinated data downstream is then not possible. This limits their wide-spread adoption in restoration applications. Furthermore, it is often the hallucinated part that is victim to degradation-model overfitting. We present an approach with decoupled network-prior hallucination and data fidelity. We refer to our framework as the Bayesian Integration of a Generative Prior (BIGPrior). Our BIGPrior method is rooted in a Bayesian restoration framework, and tightly connected to classical restoration methods. In fact, our approach can be viewed as a generalization of a large family of classical restoration algorithms. We leverage a recent network inversion method to extract image prior information from a generative network. We show on image colorization, inpainting, and denoising that our framework consistently improves the prior results through good integration of data fidelity. Our method, though partly reliant on the quality of the generative network inversion, is competitive with state-of-the-art supervised and task-specific restoration methods. It also provides an additional metric that sets forth the degree of prior reliance per pixel. Indeed, the per pixel contributions of the decoupled data fidelity and prior terms are readily available in our proposed framework.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020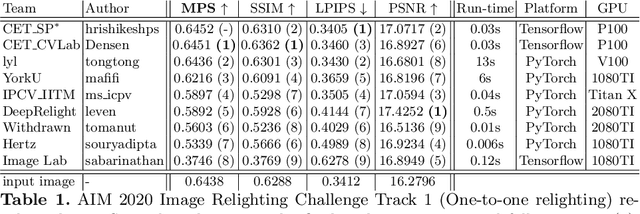

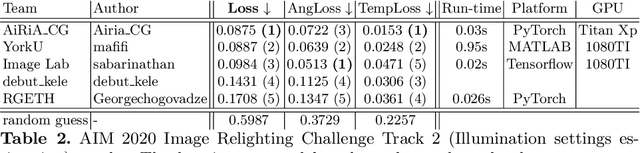

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.