 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManabu Okumura
Community-Invariant Graph Contrastive Learning
May 02, 2024




Graph augmentation has received great attention in recent years for graph contrastive learning (GCL) to learn well-generalized node/graph representations. However, mainstream GCL methods often favor randomly disrupting graphs for augmentation, which shows limited generalization and inevitably leads to the corruption of high-level graph information, i.e., the graph community. Moreover, current knowledge-based graph augmentation methods can only focus on either topology or node features, causing the model to lack robustness against various types of noise. To address these limitations, this research investigated the role of the graph community in graph augmentation and figured out its crucial advantage for learnable graph augmentation. Based on our observations, we propose a community-invariant GCL framework to maintain graph community structure during learnable graph augmentation. By maximizing the spectral changes, this framework unifies the constraints of both topology and feature augmentation, enhancing the model's robustness. Empirical evidence on 21 benchmark datasets demonstrates the exclusive merits of our framework. Code is released on Github (https://github.com/ShiyinTan/CI-GCL.git).
Active Learning with Task Adaptation Pre-training for Speech Emotion Recognition
May 01, 2024Speech emotion recognition (SER) has garnered increasing attention due to its wide range of applications in various fields, including human-machine interaction, virtual assistants, and mental health assistance. However, existing SER methods often overlook the information gap between the pre-training speech recognition task and the downstream SER task, resulting in sub-optimal performance. Moreover, current methods require much time for fine-tuning on each specific speech dataset, such as IEMOCAP, which limits their effectiveness in real-world scenarios with large-scale noisy data. To address these issues, we propose an active learning (AL)-based fine-tuning framework for SER, called \textsc{After}, that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training speech recognition task and the downstream speech emotion recognition task. Then, AL methods are employed to iteratively select a subset of the most informative and diverse samples for fine-tuning, thereby reducing time consumption. Experiments demonstrate that our proposed method \textsc{After}, using only 20\% of samples, improves accuracy by 8.45\% and reduces time consumption by 79\%. The additional extension of \textsc{After} and ablation studies further confirm its effectiveness and applicability to various real-world scenarios. Our source code is available on Github for reproducibility. (https://github.com/Clearloveyuan/AFTER).
A Survey on Deep Active Learning: Recent Advances and New Frontiers
May 01, 2024Active learning seeks to achieve strong performance with fewer training samples. It does this by iteratively asking an oracle to label new selected samples in a human-in-the-loop manner. This technique has gained increasing popularity due to its broad applicability, yet its survey papers, especially for deep learning-based active learning (DAL), remain scarce. Therefore, we conduct an advanced and comprehensive survey on DAL. We first introduce reviewed paper collection and filtering. Second, we formally define the DAL task and summarize the most influential baselines and widely used datasets. Third, we systematically provide a taxonomy of DAL methods from five perspectives, including annotation types, query strategies, deep model architectures, learning paradigms, and training processes, and objectively analyze their strengths and weaknesses. Then, we comprehensively summarize main applications of DAL in Natural Language Processing (NLP), Computer Vision (CV), and Data Mining (DM), etc. Finally, we discuss challenges and perspectives after a detailed analysis of current studies. This work aims to serve as a useful and quick guide for researchers in overcoming difficulties in DAL. We hope that this survey will spur further progress in this burgeoning field.
DiLM: Distilling Dataset into Language Model for Text-level Dataset Distillation
Mar 30, 2024Dataset distillation aims to compress a training dataset by creating a small number of informative synthetic samples such that neural networks trained on them perform as well as those trained on the original training dataset. Current text dataset distillation methods create each synthetic sample as a sequence of word embeddings instead of a text to apply gradient-based optimization; however, such embedding-level distilled datasets cannot be used for training other models whose word embedding weights are different from the model used for distillation. To address this issue, we propose a novel text dataset distillation approach, called Distilling dataset into Language Model (DiLM), which trains a language model to generate informative synthetic training samples as text data, instead of directly optimizing synthetic samples. We evaluated DiLM on various text classification datasets and showed that distilled synthetic datasets from DiLM outperform those from current coreset selection methods. DiLM achieved remarkable generalization performance in training different types of models and in-context learning of large language models. Our code will be available at https://github.com/arumaekawa/DiLM.
Can we obtain significant success in RST discourse parsing by using Large Language Models?
Mar 08, 2024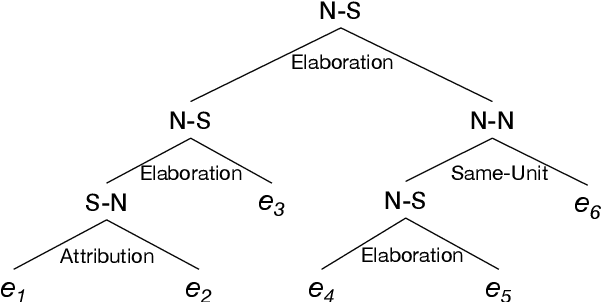
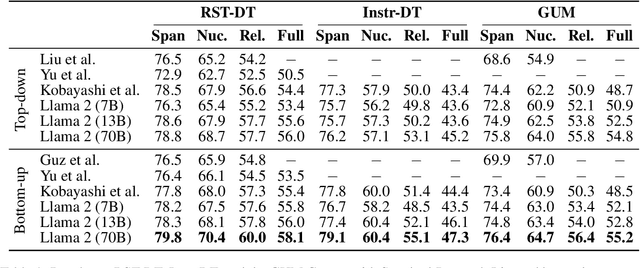
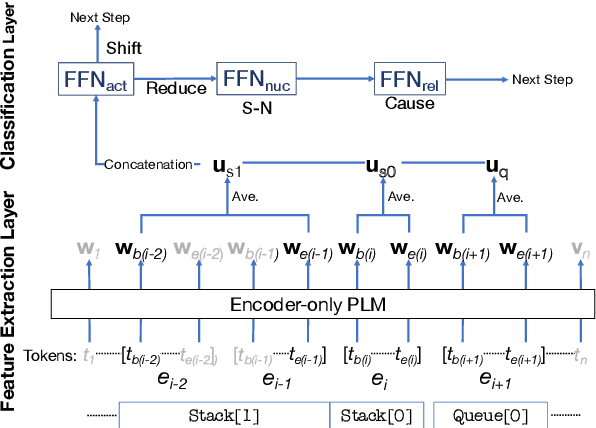
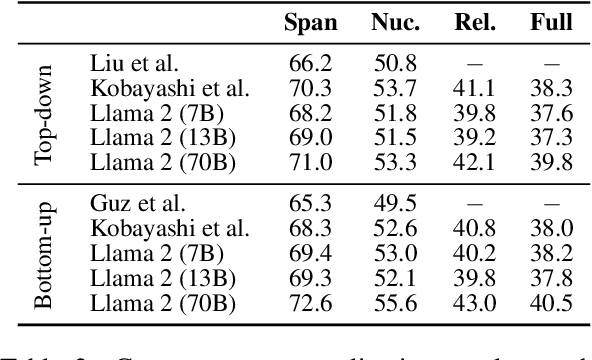
Recently, decoder-only pre-trained large language models (LLMs), with several tens of billion parameters, have significantly impacted a wide range of natural language processing (NLP) tasks. While encoder-only or encoder-decoder pre-trained language models have already proved to be effective in discourse parsing, the extent to which LLMs can perform this task remains an open research question. Therefore, this paper explores how beneficial such LLMs are for Rhetorical Structure Theory (RST) discourse parsing. Here, the parsing process for both fundamental top-down and bottom-up strategies is converted into prompts, which LLMs can work with. We employ Llama 2 and fine-tune it with QLoRA, which has fewer parameters that can be tuned. Experimental results on three benchmark datasets, RST-DT, Instr-DT, and the GUM corpus, demonstrate that Llama 2 with 70 billion parameters in the bottom-up strategy obtained state-of-the-art (SOTA) results with significant differences. Furthermore, our parsers demonstrated generalizability when evaluated on RST-DT, showing that, in spite of being trained with the GUM corpus, it obtained similar performances to those of existing parsers trained with RST-DT.
MRKE: The Multi-hop Reasoning Evaluation of LLMs by Knowledge Edition
Feb 19, 2024Although Large Language Models (LLMs) have shown strong performance in Multi-hop Question Answering (MHQA) tasks, their real reasoning ability remains exploration. Current LLM QA evaluation benchmarks have shown limitations, including 1) data contamination, the evaluation data are potentially exposed to LLMs during the pretraining stage; and 2) ignoration of the reasoning chain evaluation. Thus we introduce an LLM MHQA evaluation benchmark, the first QA benchmark based on the new, unprecedented knowledge by editing the off-the-shelf HotpotQA dataset; Besides, we also annotate and evaluate the reasoning chain in the form of sub-questions and intermediate answers corresponding to the multi-hop questions. Specifically, based on the observation, 1) LLMs show a performance gap between the original HotpotQA and our edited data, deeming that current MHQA benchmarks have the potential risk of data contamination that hard to evaluate LLMs' performance objectively and scientifically; 2) LLMs only get a small percentage of the right reasoning chain, e.g. GPT-4 only gets 36.3\% right reasoning chain. We believe this new Multi-hop QA evaluation benchmark and novel evaluation methods will facilitate the development of trustworthy LLM evaluation on the MHQA task.
GenDec: A robust generative Question-decomposition method for Multi-hop reasoning
Feb 17, 2024Multi-hop QA (MHQA) involves step-by-step reasoning to answer complex questions and find multiple relevant supporting facts. However, Existing large language models'(LLMs) reasoning ability in multi-hop question answering remains exploration, which is inadequate in answering multi-hop questions. Moreover, it is unclear whether LLMs follow a desired reasoning chain to reach the right final answer. In this paper, we propose a \textbf{gen}erative question \textbf{dec}omposition method (GenDec) from the perspective of explainable QA by generating independent and complete sub-questions based on incorporating additional extracted evidence for enhancing LLMs' reasoning ability in RAG. To demonstrate the impact, generalization, and robustness of Gendec, we conduct two experiments, the first is combining GenDec with small QA systems on paragraph retrieval and QA tasks. We secondly examine the reasoning capabilities of various state-of-the-art LLMs including GPT-4 and GPT-3.5 combined with GenDec. We experiment on the HotpotQA, 2WikihopMultiHopQA, MuSiQue, and PokeMQA datasets.
Joyful: Joint Modality Fusion and Graph Contrastive Learning for Multimodal Emotion Recognition
Nov 18, 2023



Multimodal emotion recognition aims to recognize emotions for each utterance of multiple modalities, which has received increasing attention for its application in human-machine interaction. Current graph-based methods fail to simultaneously depict global contextual features and local diverse uni-modal features in a dialogue. Furthermore, with the number of graph layers increasing, they easily fall into over-smoothing. In this paper, we propose a method for joint modality fusion and graph contrastive learning for multimodal emotion recognition (Joyful), where multimodality fusion, contrastive learning, and emotion recognition are jointly optimized. Specifically, we first design a new multimodal fusion mechanism that can provide deep interaction and fusion between the global contextual and uni-modal specific features. Then, we introduce a graph contrastive learning framework with inter-view and intra-view contrastive losses to learn more distinguishable representations for samples with different sentiments. Extensive experiments on three benchmark datasets indicate that Joyful achieved state-of-the-art (SOTA) performance compared to all baselines.
Unlocking Science: Novel Dataset and Benchmark for Cross-Modality Scientific Information Extraction
Nov 15, 2023Extracting key information from scientific papers has the potential to help researchers work more efficiently and accelerate the pace of scientific progress. Over the last few years, research on Scientific Information Extraction (SciIE) witnessed the release of several new systems and benchmarks. However, existing paper-focused datasets mostly focus only on specific parts of a manuscript (e.g., abstracts) and are single-modality (i.e., text- or table-only), due to complex processing and expensive annotations. Moreover, core information can be present in either text or tables or across both. To close this gap in data availability and enable cross-modality IE, while alleviating labeling costs, we propose a semi-supervised pipeline for annotating entities in text, as well as entities and relations in tables, in an iterative procedure. Based on this pipeline, we release novel resources for the scientific community, including a high-quality benchmark, a large-scale corpus, and a semi-supervised annotation pipeline. We further report the performance of state-of-the-art IE models on the proposed benchmark dataset, as a baseline. Lastly, we explore the potential capability of large language models such as ChatGPT for the current task. Our new dataset, results, and analysis validate the effectiveness and efficiency of our semi-supervised pipeline, and we discuss its remaining limitations.
Active Learning Based Fine-Tuning Framework for Speech Emotion Recognition
Sep 30, 2023Speech emotion recognition (SER) has drawn increasing attention for its applications in human-machine interaction. However, existing SER methods ignore the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance. Moreover, they require much time to fine-tune on each specific speech dataset, restricting their effectiveness in real-world scenes with large-scale noisy data. To address these issues, we propose an active learning (AL) based Fine-Tuning framework for SER that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training and the downstream task. Then, AL methods are used to iteratively select a subset of the most informative and diverse samples for fine-tuning, reducing time consumption. Experiments demonstrate that using only 20\%pt. samples improves 8.45\%pt. accuracy and reduces 79\%pt. time consumption.