 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManan Tomar
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Sep 22, 2023
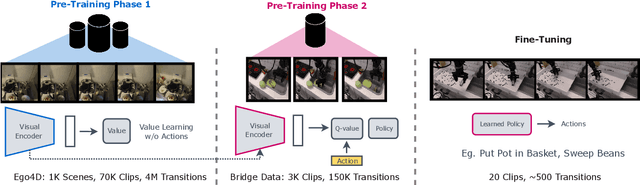
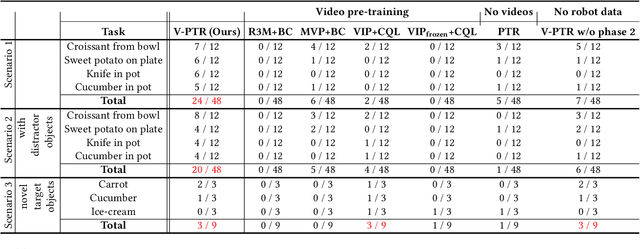
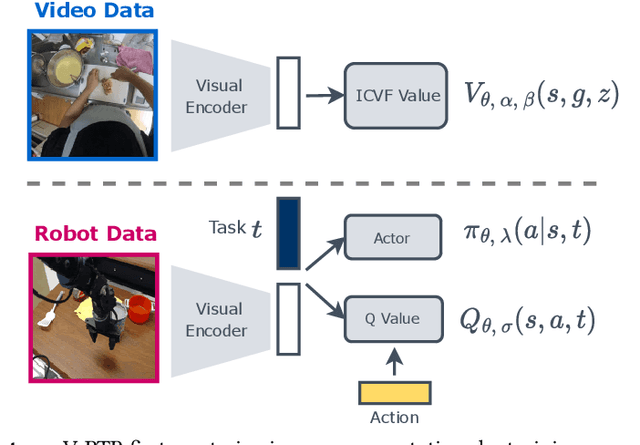

Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at https://dibyaghosh.com/vptr/
Ignorance is Bliss: Robust Control via Information Gating
Mar 10, 2023
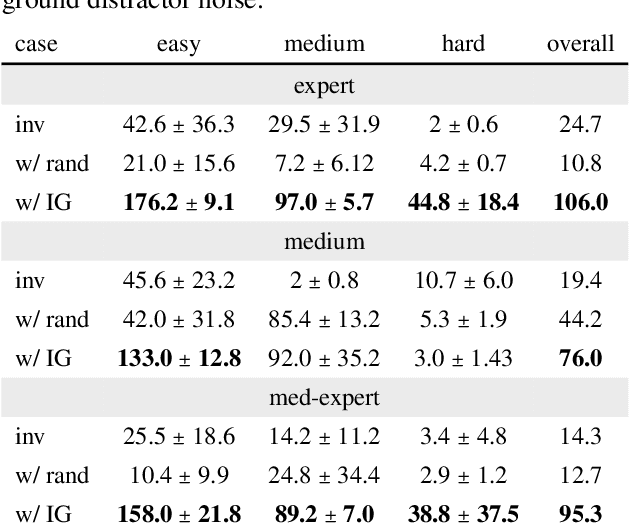
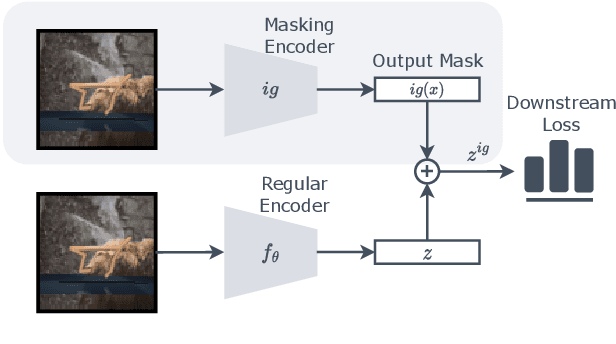
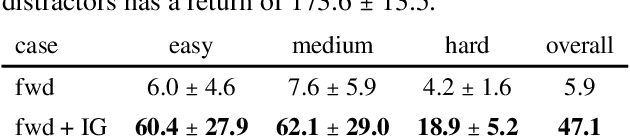
Informational parsimony -- i.e., using the minimal information required for a task, -- provides a useful inductive bias for learning representations that achieve better generalization by being robust to noise and spurious correlations. We propose information gating in the pixel space as a way to learn more parsimonious representations. Information gating works by learning masks that capture only the minimal information required to solve a given task. Intuitively, our models learn to identify which visual cues actually matter for a given task. We gate information using a differentiable parameterization of the signal-to-noise ratio, which can be applied to arbitrary values in a network, e.g.~masking out pixels at the input layer. We apply our approach, which we call InfoGating, to various objectives such as: multi-step forward and inverse dynamics, Q-learning, behavior cloning, and standard self-supervised tasks. Our experiments show that learning to identify and use minimal information can improve generalization in downstream tasks -- e.g., policies based on info-gated images are considerably more robust to distracting/irrelevant visual features.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022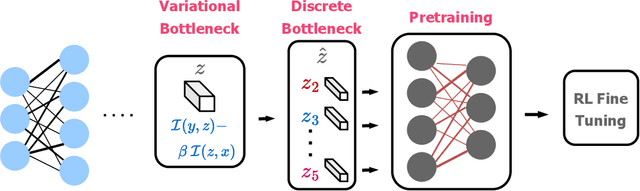

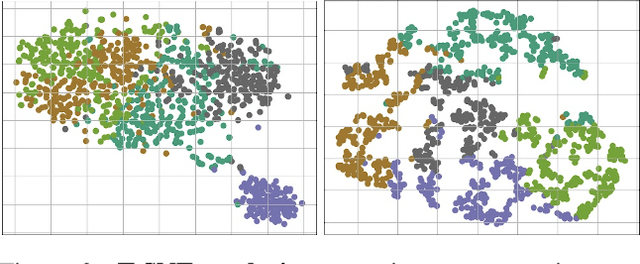
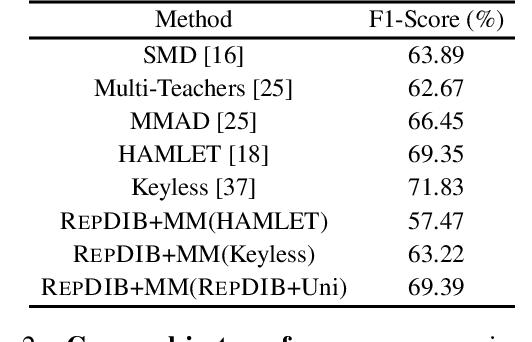
Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
Oct 31, 2022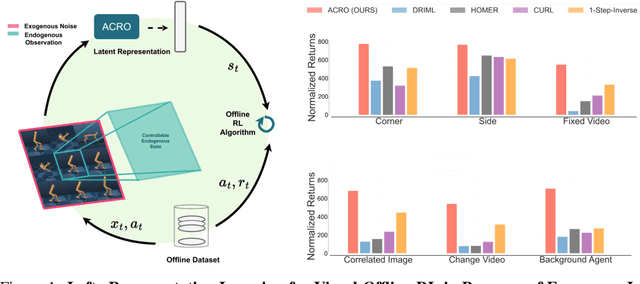

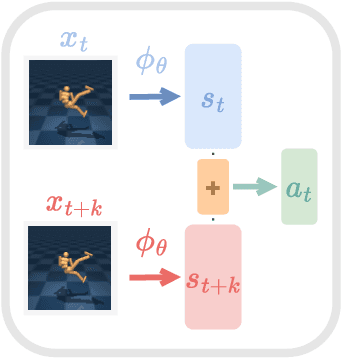
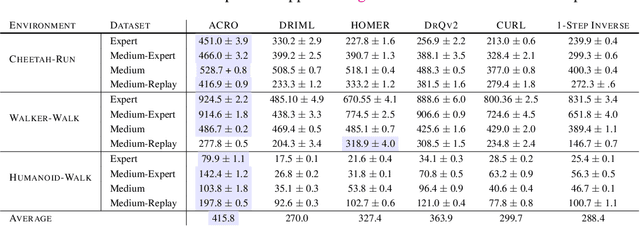
Learning to control an agent from data collected offline in a rich pixel-based visual observation space is vital for real-world applications of reinforcement learning (RL). A major challenge in this setting is the presence of input information that is hard to model and irrelevant to controlling the agent. This problem has been approached by the theoretical RL community through the lens of exogenous information, i.e, any control-irrelevant information contained in observations. For example, a robot navigating in busy streets needs to ignore irrelevant information, such as other people walking in the background, textures of objects, or birds in the sky. In this paper, we focus on the setting with visually detailed exogenous information, and introduce new offline RL benchmarks offering the ability to study this problem. We find that contemporary representation learning techniques can fail on datasets where the noise is a complex and time dependent process, which is prevalent in practical applications. To address these, we propose to use multi-step inverse models, which have seen a great deal of interest in the RL theory community, to learn Agent-Controller Representations for Offline-RL (ACRO). Despite being simple and requiring no reward, we show theoretically and empirically that the representation created by this objective greatly outperforms baselines.
Learning Representations for Pixel-based Control: What Matters and Why?
Nov 15, 2021



Learning representations for pixel-based control has garnered significant attention recently in reinforcement learning. A wide range of methods have been proposed to enable efficient learning, leading to sample complexities similar to those in the full state setting. However, moving beyond carefully curated pixel data sets (centered crop, appropriate lighting, clear background, etc.) remains challenging. In this paper, we adopt a more difficult setting, incorporating background distractors, as a first step towards addressing this challenge. We present a simple baseline approach that can learn meaningful representations with no metric-based learning, no data augmentations, no world-model learning, and no contrastive learning. We then analyze when and why previously proposed methods are likely to fail or reduce to the same performance as the baseline in this harder setting and why we should think carefully about extending such methods beyond the well curated environments. Our results show that finer categorization of benchmarks on the basis of characteristics like density of reward, planning horizon of the problem, presence of task-irrelevant components, etc., is crucial in evaluating algorithms. Based on these observations, we propose different metrics to consider when evaluating an algorithm on benchmark tasks. We hope such a data-centric view can motivate researchers to rethink representation learning when investigating how to best apply RL to real-world tasks.
Model-Invariant State Abstractions for Model-Based Reinforcement Learning
Feb 19, 2021



Accuracy and generalization of dynamics models is key to the success of model-based reinforcement learning (MBRL). As the complexity of tasks increases, learning dynamics models becomes increasingly sample inefficient for MBRL methods. However, many tasks also exhibit sparsity in the dynamics, i.e., actions have only a local effect on the system dynamics. In this paper, we exploit this property with a causal invariance perspective in the single-task setting, introducing a new type of state abstraction called \textit{model-invariance}. Unlike previous forms of state abstractions, a model-invariance state abstraction leverages causal sparsity over state variables. This allows for generalization to novel combinations of unseen values of state variables, something that non-factored forms of state abstractions cannot do. We prove that an optimal policy can be learned over this model-invariance state abstraction. Next, we propose a practical method to approximately learn a model-invariant representation for complex domains. We validate our approach by showing improved modeling performance over standard maximum likelihood approaches on challenging tasks, such as the MuJoCo-based Humanoid. Furthermore, within the MBRL setting we show strong performance gains w.r.t. sample efficiency across a host of other continuous control tasks.
Mirror Descent Policy Optimization
Jun 09, 2020



We propose deep Reinforcement Learning (RL) algorithms inspired by mirror descent, a well-known first-order trust region optimization method for solving constrained convex problems. Our approach, which we call as Mirror Descent Policy Optimization (MDPO), is based on the idea of iteratively solving a `trust-region' problem that minimizes a sum of two terms: a linearization of the objective function and a proximity term that restricts two consecutive updates to be close to each other. Following this approach we derive on-policy and off-policy variants of the MDPO algorithm and analyze their performance while emphasizing important implementation details, motivated by the existing theoretical framework. We highlight the connections between on-policy MDPO and two popular trust region RL algorithms: TRPO and PPO, and conduct a comprehensive empirical comparison of these algorithms. We then derive off-policy MDPO and compare its performance to existing approaches. Importantly, we show that the theoretical framework of MDPO can be scaled to deep RL while achieving good performance on popular benchmarks.
Multi-step Greedy Policies in Model-Free Deep Reinforcement Learning
Oct 14, 2019



Multi-step greedy policies have been extensively used in model-based Reinforcement Learning (RL) and in the case when a model of the environment is available (e.g., in the game of Go). In this work, we explore the benefits of multi-step greedy policies in model-free RL when employed in the framework of multi-step Dynamic Programming (DP): multi-step Policy and Value Iteration. These algorithms iteratively solve short-horizon decision problems and converge to the optimal solution of the original one. By using model-free algorithms as solvers of the short-horizon problems we derive fully model-free algorithms which are instances of the multi-step DP framework. As model-free algorithms are prone to instabilities w.r.t. the decision problem horizon, this simple approach can help in mitigating these instabilities and results in an improved model-free algorithms. We test this approach and show results on both discrete and continuous control problems.
MaMiC: Macro and Micro Curriculum for Robotic Reinforcement Learning
May 17, 2019



Shaping in humans and animals has been shown to be a powerful tool for learning complex tasks as compared to learning in a randomized fashion. This makes the problem less complex and enables one to solve the easier sub task at hand first. Generating a curriculum for such guided learning involves subjecting the agent to easier goals first, and then gradually increasing their difficulty. This paper takes a similar direction and proposes a dual curriculum scheme for solving robotic manipulation tasks with sparse rewards, called MaMiC. It includes a macro curriculum scheme which divides the task into multiple sub-tasks followed by a micro curriculum scheme which enables the agent to learn between such discovered sub-tasks. We show how combining macro and micro curriculum strategies help in overcoming major exploratory constraints considered in robot manipulation tasks without having to engineer any complex rewards. We also illustrate the meaning of the individual curricula and how they can be used independently based on the task. The performance of such a dual curriculum scheme is analyzed on the Fetch environments.
Successor Options: An Option Discovery Framework for Reinforcement Learning
May 14, 2019



The options framework in reinforcement learning models the notion of a skill or a temporally extended sequence of actions. The discovery of a reusable set of skills has typically entailed building options, that navigate to bottleneck states. This work adopts a complementary approach, where we attempt to discover options that navigate to landmark states. These states are prototypical representatives of well-connected regions and can hence access the associated region with relative ease. In this work, we propose Successor Options, which leverages Successor Representations to build a model of the state space. The intra-option policies are learnt using a novel pseudo-reward and the model scales to high-dimensional spaces easily. Additionally, we also propose an Incremental Successor Options model that iterates between constructing Successor Representations and building options, which is useful when robust Successor Representations cannot be built solely from primitive actions. We demonstrate the efficacy of our approach on a collection of grid-worlds, and on the high-dimensional robotic control environment of Fetch.