 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManuel Amthor
Rethinking Depthwise Separable Convolutions: How Intra-Kernel Correlations Lead to Improved MobileNets
Mar 31, 2020

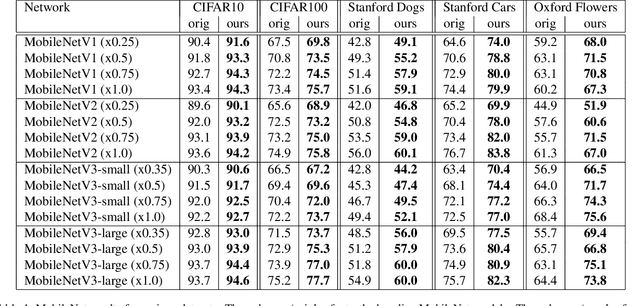


We introduce blueprint separable convolutions (BSConv) as highly efficient building blocks for CNNs. They are motivated by quantitative analyses of kernel properties from trained models, which show the dominance of correlations along the depth axis. Based on our findings, we formulate a theoretical foundation from which we derive efficient implementations using only standard layers. Moreover, our approach provides a thorough theoretical derivation, interpretation, and justification for the application of depthwise separable convolutions (DSCs) in general, which have become the basis of many modern network architectures. Ultimately, we reveal that DSC-based architectures such as MobileNets implicitly rely on cross-kernel correlations, while our BSConv formulation is based on intra-kernel correlations and thus allows for a more efficient separation of regular convolutions. Extensive experiments on large-scale and fine-grained classification datasets show that BSConvs clearly and consistently improve MobileNets and other DSC-based architectures without introducing any further complexity. For fine-grained datasets, we achieve an improvement of up to 13.7 percentage points. In addition, if used as drop-in replacement for standard architectures such as ResNets, BSConv variants also outperform their vanilla counterparts by up to 9.5 percentage points on ImageNet.
Impatient DNNs - Deep Neural Networks with Dynamic Time Budgets
Oct 10, 2016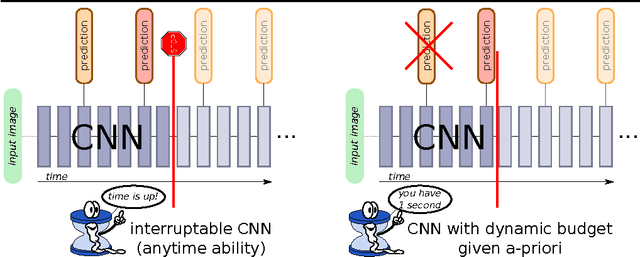
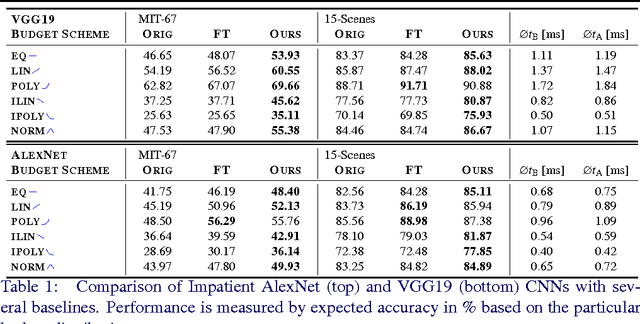
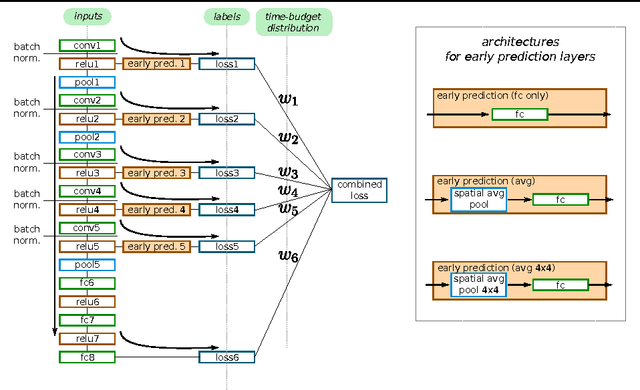

We propose Impatient Deep Neural Networks (DNNs) which deal with dynamic time budgets during application. They allow for individual budgets given a priori for each test example and for anytime prediction, i.e., a possible interruption at multiple stages during inference while still providing output estimates. Our approach can therefore tackle the computational costs and energy demands of DNNs in an adaptive manner, a property essential for real-time applications. Our Impatient DNNs are based on a new general framework of learning dynamic budget predictors using risk minimization, which can be applied to current DNN architectures by adding early prediction and additional loss layers. A key aspect of our method is that all of the intermediate predictors are learned jointly. In experiments, we evaluate our approach for different budget distributions, architectures, and datasets. Our results show a significant gain in expected accuracy compared to common baselines.