 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarcel Worring
GO4Align: Group Optimization for Multi-Task Alignment
Apr 09, 2024
This paper proposes \textit{GO4Align}, a multi-task optimization approach that tackles task imbalance by explicitly aligning the optimization across tasks. To achieve this, we design an adaptive group risk minimization strategy, compromising two crucial techniques in implementation: (i) dynamical group assignment, which clusters similar tasks based on task interactions; (ii) risk-guided group indicators, which exploit consistent task correlations with risk information from previous iterations. Comprehensive experimental results on diverse typical benchmarks demonstrate our method's performance superiority with even lower computational costs.
Conditional Modeling Based Automatic Video Summarization
Nov 20, 2023The aim of video summarization is to shorten videos automatically while retaining the key information necessary to convey the overall story. Video summarization methods mainly rely on visual factors, such as visual consecutiveness and diversity, which may not be sufficient to fully understand the content of the video. There are other non-visual factors, such as interestingness, representativeness, and storyline consistency that should also be considered for generating high-quality video summaries. Current methods do not adequately take into account these non-visual factors, resulting in suboptimal performance. In this work, a new approach to video summarization is proposed based on insights gained from how humans create ground truth video summaries. The method utilizes a conditional modeling perspective and introduces multiple meaningful random variables and joint distributions to characterize the key components of video summarization. Helper distributions are employed to improve the training of the model. A conditional attention module is designed to mitigate potential performance degradation in the presence of multi-modal input. The proposed video summarization method incorporates the above innovative design choices that aim to narrow the gap between human-generated and machine-generated video summaries. Extensive experiments show that the proposed approach outperforms existing methods and achieves state-of-the-art performance on commonly used video summarization datasets.
Episodic Multi-Task Learning with Heterogeneous Neural Processes
Oct 28, 2023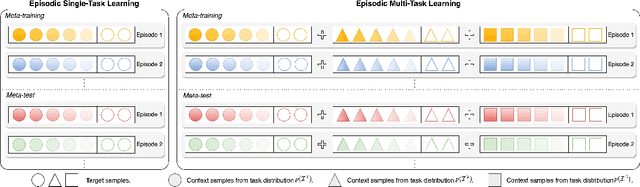
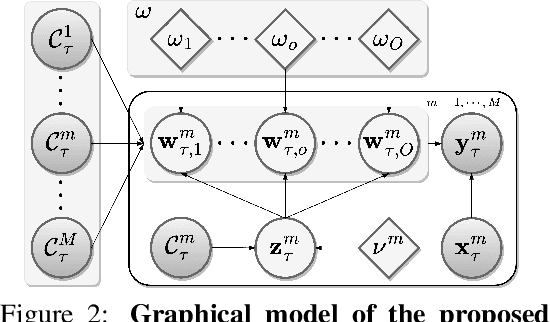
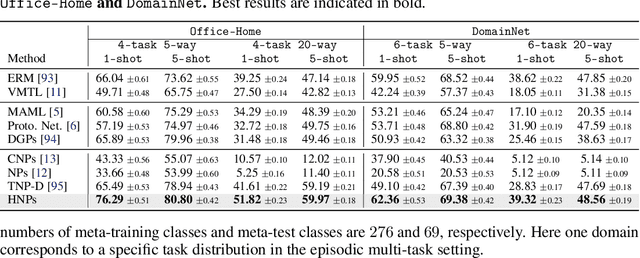
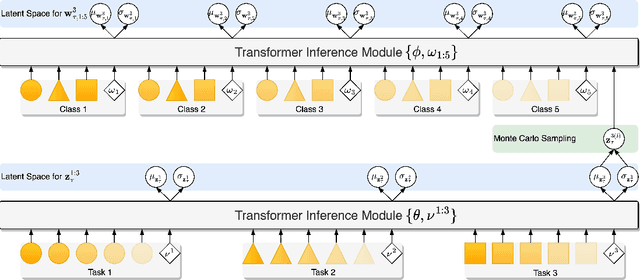
This paper focuses on the data-insufficiency problem in multi-task learning within an episodic training setup. Specifically, we explore the potential of heterogeneous information across tasks and meta-knowledge among episodes to effectively tackle each task with limited data. Existing meta-learning methods often fail to take advantage of crucial heterogeneous information in a single episode, while multi-task learning models neglect reusing experience from earlier episodes. To address the problem of insufficient data, we develop Heterogeneous Neural Processes (HNPs) for the episodic multi-task setup. Within the framework of hierarchical Bayes, HNPs effectively capitalize on prior experiences as meta-knowledge and capture task-relatedness among heterogeneous tasks, mitigating data-insufficiency. Meanwhile, transformer-structured inference modules are designed to enable efficient inferences toward meta-knowledge and task-relatedness. In this way, HNPs can learn more powerful functional priors for adapting to novel heterogeneous tasks in each meta-test episode. Experimental results show the superior performance of the proposed HNPs over typical baselines, and ablation studies verify the effectiveness of the designed inference modules.
Small Visual Language Models can also be Open-Ended Few-Shot Learners
Sep 30, 2023



We present Self-Context Adaptation (SeCAt), a self-supervised approach that unlocks open-ended few-shot abilities of small visual language models. Our proposed adaptation algorithm explicitly learns from symbolic, yet self-supervised training tasks. Specifically, our approach imitates image captions in a self-supervised way based on clustering a large pool of images followed by assigning semantically-unrelated names to clusters. By doing so, we construct the `self-context', a training signal consisting of interleaved sequences of image and pseudo-caption pairs and a query image for which the model is trained to produce the right pseudo-caption. We demonstrate the performance and flexibility of SeCAt on several multimodal few-shot datasets, spanning various granularities. By using models with approximately 1B parameters we outperform the few-shot abilities of much larger models, such as Frozen and FROMAGe. SeCAt opens new possibilities for research in open-ended few-shot learning that otherwise requires access to large or proprietary models.
Prototype-Enhanced Hypergraph Learning for Heterogeneous Information Networks
Sep 22, 2023The variety and complexity of relations in multimedia data lead to Heterogeneous Information Networks (HINs). Capturing the semantics from such networks requires approaches capable of utilizing the full richness of the HINs. Existing methods for modeling HINs employ techniques originally designed for graph neural networks, and HINs decomposition analysis, like using manually predefined metapaths. In this paper, we introduce a novel prototype-enhanced hypergraph learning approach for node classification in HINs. Using hypergraphs instead of graphs, our method captures higher-order relationships among nodes and extracts semantic information without relying on metapaths. Our method leverages the power of prototypes to improve the robustness of the hypergraph learning process and creates the potential to provide human-interpretable insights into the underlying network structure. Extensive experiments on three real-world HINs demonstrate the effectiveness of our method.
ProtoExplorer: Interpretable Forensic Analysis of Deepfake Videos using Prototype Exploration and Refinement
Sep 20, 2023



In high-stakes settings, Machine Learning models that can provide predictions that are interpretable for humans are crucial. This is even more true with the advent of complex deep learning based models with a huge number of tunable parameters. Recently, prototype-based methods have emerged as a promising approach to make deep learning interpretable. We particularly focus on the analysis of deepfake videos in a forensics context. Although prototype-based methods have been introduced for the detection of deepfake videos, their use in real-world scenarios still presents major challenges, in that prototypes tend to be overly similar and interpretability varies between prototypes. This paper proposes a Visual Analytics process model for prototype learning, and, based on this, presents ProtoExplorer, a Visual Analytics system for the exploration and refinement of prototype-based deepfake detection models. ProtoExplorer offers tools for visualizing and temporally filtering prototype-based predictions when working with video data. It disentangles the complexity of working with spatio-temporal prototypes, facilitating their visualization. It further enables the refinement of models by interactively deleting and replacing prototypes with the aim to achieve more interpretable and less biased predictions while preserving detection accuracy. The system was designed with forensic experts and evaluated in a number of rounds based on both open-ended think aloud evaluation and interviews. These sessions have confirmed the strength of our prototype based exploration of deepfake videos while they provided the feedback needed to continuously improve the system.
Knowledge Graph Embeddings for Multi-Lingual Structured Representations of Radiology Reports
Sep 14, 2023



The way we analyse clinical texts has undergone major changes over the last years. The introduction of language models such as BERT led to adaptations for the (bio)medical domain like PubMedBERT and ClinicalBERT. These models rely on large databases of archived medical documents. While performing well in terms of accuracy, both the lack of interpretability and limitations to transfer across languages limit their use in clinical setting. We introduce a novel light-weight graph-based embedding method specifically catering radiology reports. It takes into account the structure and composition of the report, while also connecting medical terms in the report through the multi-lingual SNOMED Clinical Terms knowledge base. The resulting graph embedding uncovers the underlying relationships among clinical terms, achieving a representation that is better understandable for clinicians and clinically more accurate, without reliance on large pre-training datasets. We show the use of this embedding on two tasks namely disease classification of X-ray reports and image classification. For disease classification our model is competitive with its BERT-based counterparts, while being magnitudes smaller in size and training data requirements. For image classification, we show the effectiveness of the graph embedding leveraging cross-modal knowledge transfer and show how this method is usable across different languages.
Multimodal Temporal Fusion Transformers Are Good Product Demand Forecasters
Jul 05, 2023



Multimodal demand forecasting aims at predicting product demand utilizing visual, textual, and contextual information. This paper proposes a method for multimodal product demand forecasting using convolutional, graph-based, and transformer-based architectures. Traditional approaches to demand forecasting rely on historical demand, product categories, and additional contextual information such as seasonality and events. However, these approaches have several shortcomings, such as the cold start problem making it difficult to predict product demand until sufficient historical data is available for a particular product, and their inability to properly deal with category dynamics. By incorporating multimodal information, such as product images and textual descriptions, our architecture aims to address the shortcomings of traditional approaches and outperform them. The experiments conducted on a large real-world dataset show that the proposed approach effectively predicts demand for a wide range of products. The multimodal pipeline presented in this work enhances the accuracy and reliability of the predictions, demonstrating the potential of leveraging multimodal information in product demand forecasting.
Causal Video Summarizer for Video Exploration
Jul 04, 2023

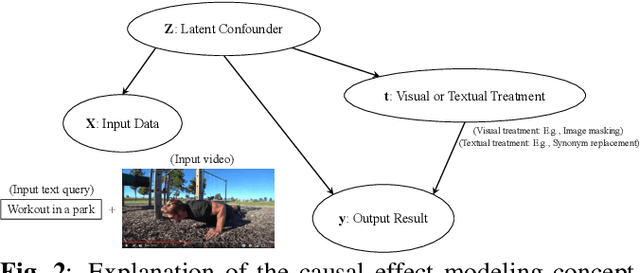

Recently, video summarization has been proposed as a method to help video exploration. However, traditional video summarization models only generate a fixed video summary which is usually independent of user-specific needs and hence limits the effectiveness of video exploration. Multi-modal video summarization is one of the approaches utilized to address this issue. Multi-modal video summarization has a video input and a text-based query input. Hence, effective modeling of the interaction between a video input and text-based query is essential to multi-modal video summarization. In this work, a new causality-based method named Causal Video Summarizer (CVS) is proposed to effectively capture the interactive information between the video and query to tackle the task of multi-modal video summarization. The proposed method consists of a probabilistic encoder and a probabilistic decoder. Based on the evaluation of the existing multi-modal video summarization dataset, experimental results show that the proposed approach is effective with the increase of +5.4% in accuracy and +4.92% increase of F 1- score, compared with the state-of-the-art method.
Query-based Video Summarization with Pseudo Label Supervision
Jul 04, 2023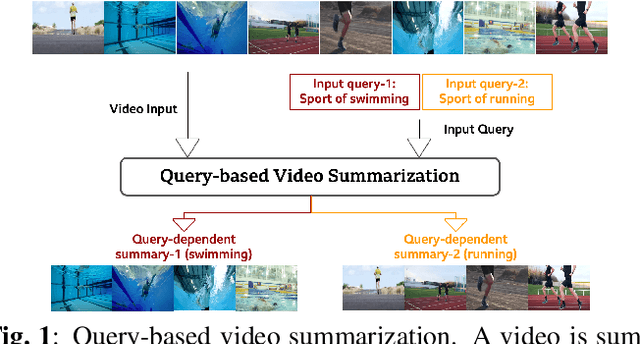
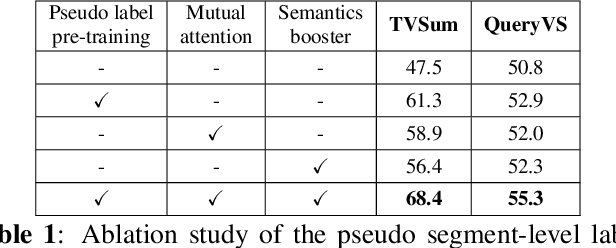
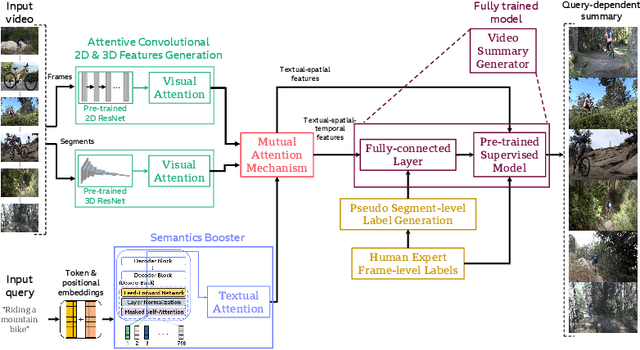
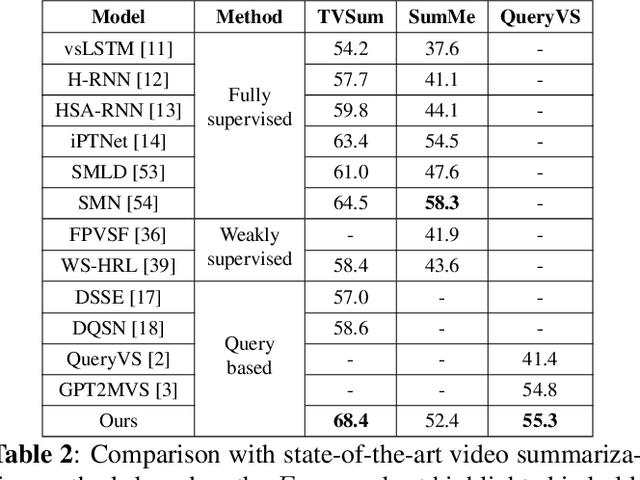
Existing datasets for manually labelled query-based video summarization are costly and thus small, limiting the performance of supervised deep video summarization models. Self-supervision can address the data sparsity challenge by using a pretext task and defining a method to acquire extra data with pseudo labels to pre-train a supervised deep model. In this work, we introduce segment-level pseudo labels from input videos to properly model both the relationship between a pretext task and a target task, and the implicit relationship between the pseudo label and the human-defined label. The pseudo labels are generated based on existing human-defined frame-level labels. To create more accurate query-dependent video summaries, a semantics booster is proposed to generate context-aware query representations. Furthermore, we propose mutual attention to help capture the interactive information between visual and textual modalities. Three commonly-used video summarization benchmarks are used to thoroughly validate the proposed approach. Experimental results show that the proposed video summarization algorithm achieves state-of-the-art performance.