 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJia-Hong Huang
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Apr 29, 2024
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10\% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Conditional Modeling Based Automatic Video Summarization
Nov 20, 2023The aim of video summarization is to shorten videos automatically while retaining the key information necessary to convey the overall story. Video summarization methods mainly rely on visual factors, such as visual consecutiveness and diversity, which may not be sufficient to fully understand the content of the video. There are other non-visual factors, such as interestingness, representativeness, and storyline consistency that should also be considered for generating high-quality video summaries. Current methods do not adequately take into account these non-visual factors, resulting in suboptimal performance. In this work, a new approach to video summarization is proposed based on insights gained from how humans create ground truth video summaries. The method utilizes a conditional modeling perspective and introduces multiple meaningful random variables and joint distributions to characterize the key components of video summarization. Helper distributions are employed to improve the training of the model. A conditional attention module is designed to mitigate potential performance degradation in the presence of multi-modal input. The proposed video summarization method incorporates the above innovative design choices that aim to narrow the gap between human-generated and machine-generated video summaries. Extensive experiments show that the proposed approach outperforms existing methods and achieves state-of-the-art performance on commonly used video summarization datasets.
Causal Video Summarizer for Video Exploration
Jul 04, 2023

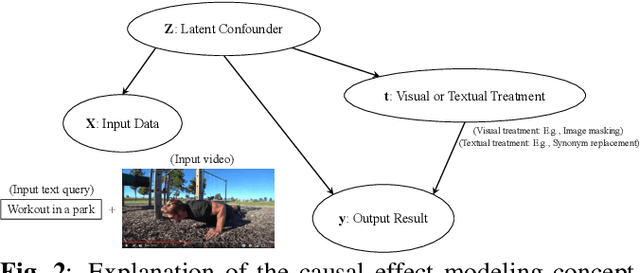

Recently, video summarization has been proposed as a method to help video exploration. However, traditional video summarization models only generate a fixed video summary which is usually independent of user-specific needs and hence limits the effectiveness of video exploration. Multi-modal video summarization is one of the approaches utilized to address this issue. Multi-modal video summarization has a video input and a text-based query input. Hence, effective modeling of the interaction between a video input and text-based query is essential to multi-modal video summarization. In this work, a new causality-based method named Causal Video Summarizer (CVS) is proposed to effectively capture the interactive information between the video and query to tackle the task of multi-modal video summarization. The proposed method consists of a probabilistic encoder and a probabilistic decoder. Based on the evaluation of the existing multi-modal video summarization dataset, experimental results show that the proposed approach is effective with the increase of +5.4% in accuracy and +4.92% increase of F 1- score, compared with the state-of-the-art method.
Query-based Video Summarization with Pseudo Label Supervision
Jul 04, 2023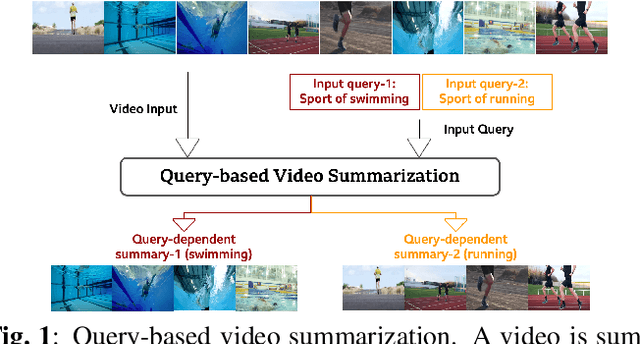
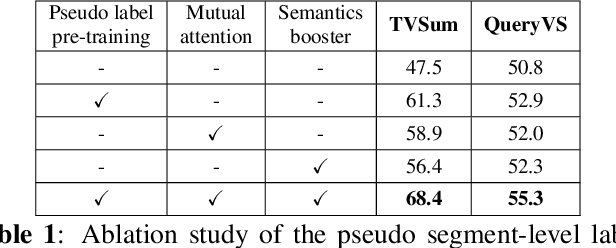
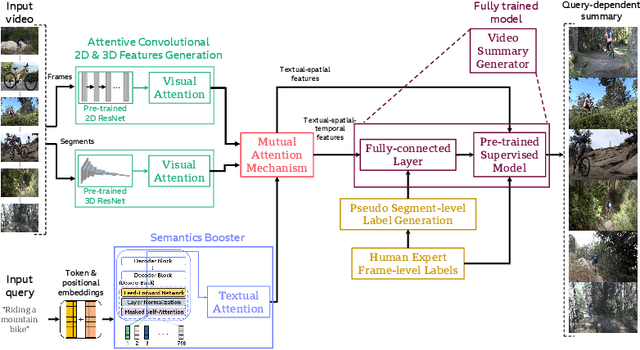
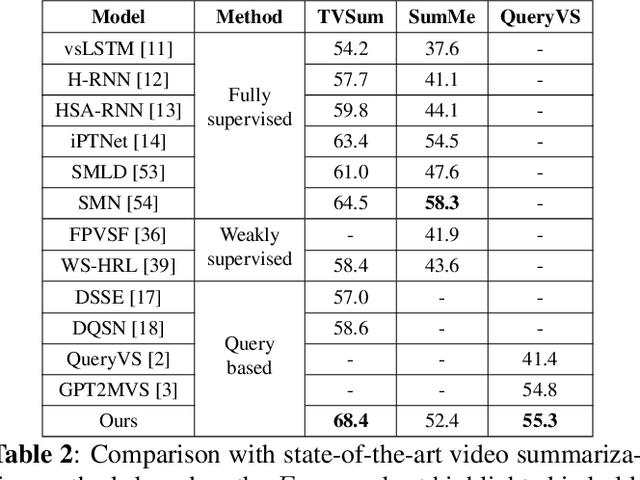
Existing datasets for manually labelled query-based video summarization are costly and thus small, limiting the performance of supervised deep video summarization models. Self-supervision can address the data sparsity challenge by using a pretext task and defining a method to acquire extra data with pseudo labels to pre-train a supervised deep model. In this work, we introduce segment-level pseudo labels from input videos to properly model both the relationship between a pretext task and a target task, and the implicit relationship between the pseudo label and the human-defined label. The pseudo labels are generated based on existing human-defined frame-level labels. To create more accurate query-dependent video summaries, a semantics booster is proposed to generate context-aware query representations. Furthermore, we propose mutual attention to help capture the interactive information between visual and textual modalities. Three commonly-used video summarization benchmarks are used to thoroughly validate the proposed approach. Experimental results show that the proposed video summarization algorithm achieves state-of-the-art performance.
Causalainer: Causal Explainer for Automatic Video Summarization
Apr 30, 2023
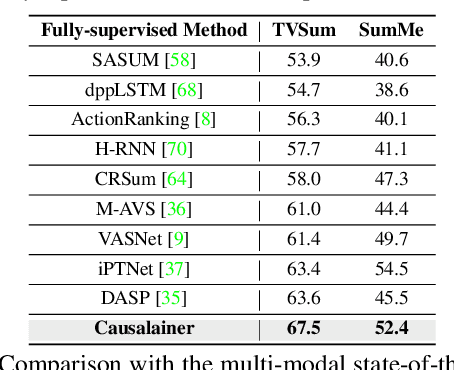
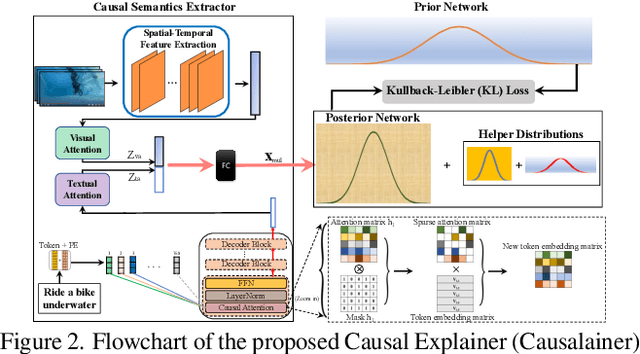
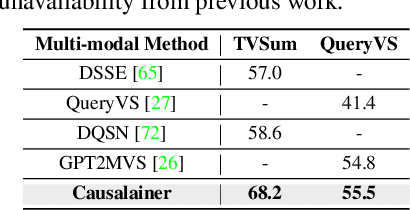
The goal of video summarization is to automatically shorten videos such that it conveys the overall story without losing relevant information. In many application scenarios, improper video summarization can have a large impact. For example in forensics, the quality of the generated video summary will affect an investigator's judgment while in journalism it might yield undesired bias. Because of this, modeling explainability is a key concern. One of the best ways to address the explainability challenge is to uncover the causal relations that steer the process and lead to the result. Current machine learning-based video summarization algorithms learn optimal parameters but do not uncover causal relationships. Hence, they suffer from a relative lack of explainability. In this work, a Causal Explainer, dubbed Causalainer, is proposed to address this issue. Multiple meaningful random variables and their joint distributions are introduced to characterize the behaviors of key components in the problem of video summarization. In addition, helper distributions are introduced to enhance the effectiveness of model training. In visual-textual input scenarios, the extra input can decrease the model performance. A causal semantics extractor is designed to tackle this issue by effectively distilling the mutual information from the visual and textual inputs. Experimental results on commonly used benchmarks demonstrate that the proposed method achieves state-of-the-art performance while being more explainable.
Improving Visual Question Answering Models through Robustness Analysis and In-Context Learning with a Chain of Basic Questions
Apr 06, 2023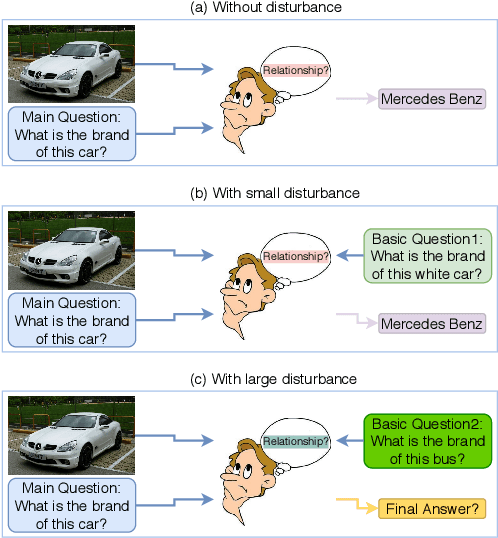

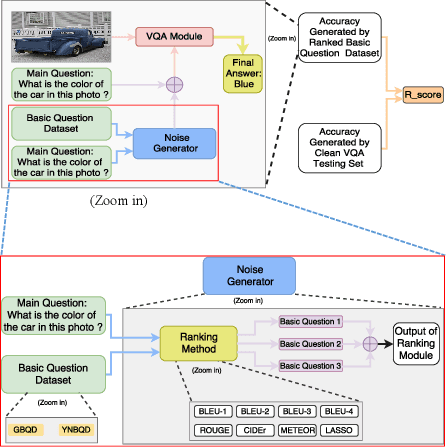

Deep neural networks have been critical in the task of Visual Question Answering (VQA), with research traditionally focused on improving model accuracy. Recently, however, there has been a trend towards evaluating the robustness of these models against adversarial attacks. This involves assessing the accuracy of VQA models under increasing levels of noise in the input, which can target either the image or the proposed query question, dubbed the main question. However, there is currently a lack of proper analysis of this aspect of VQA. This work proposes a new method that utilizes semantically related questions, referred to as basic questions, acting as noise to evaluate the robustness of VQA models. It is hypothesized that as the similarity of a basic question to the main question decreases, the level of noise increases. To generate a reasonable noise level for a given main question, a pool of basic questions is ranked based on their similarity to the main question, and this ranking problem is cast as a LASSO optimization problem. Additionally, this work proposes a novel robustness measure, R_score, and two basic question datasets to standardize the analysis of VQA model robustness. The experimental results demonstrate that the proposed evaluation method effectively analyzes the robustness of VQA models. Moreover, the experiments show that in-context learning with a chain of basic questions can enhance model accuracy.
The Dawn of Quantum Natural Language Processing
Oct 13, 2021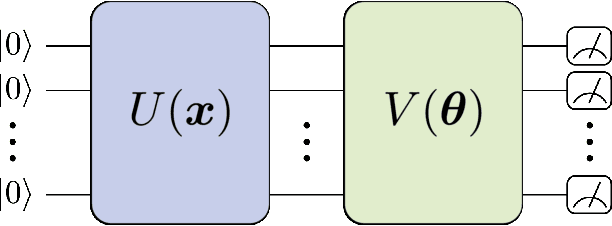
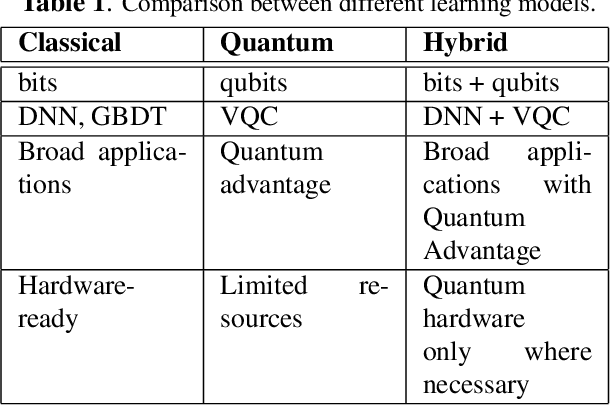
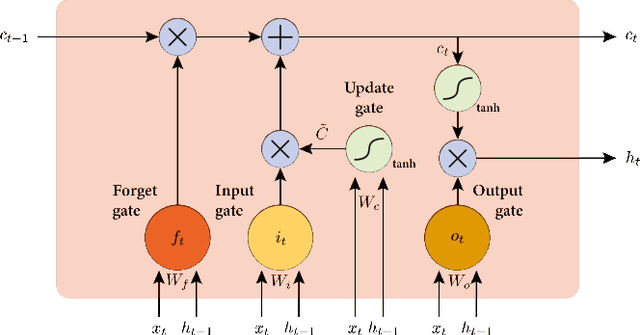
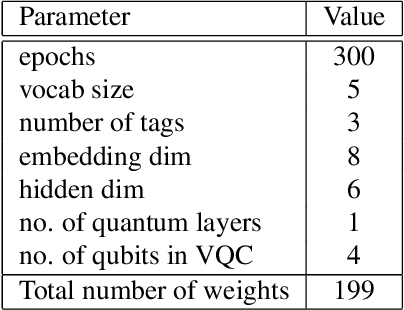
In this paper, we discuss the initial attempts at boosting understanding human language based on deep-learning models with quantum computing. We successfully train a quantum-enhanced Long Short-Term Memory network to perform the parts-of-speech tagging task via numerical simulations. Moreover, a quantum-enhanced Transformer is proposed to perform the sentiment analysis based on the existing dataset.
Longer Version for "Deep Context-Encoding Network for Retinal Image Captioning"
May 30, 2021
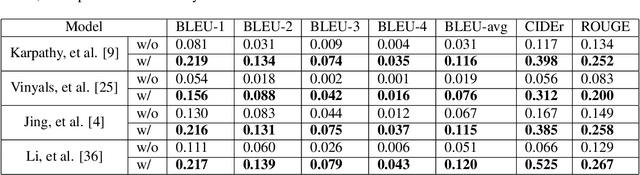
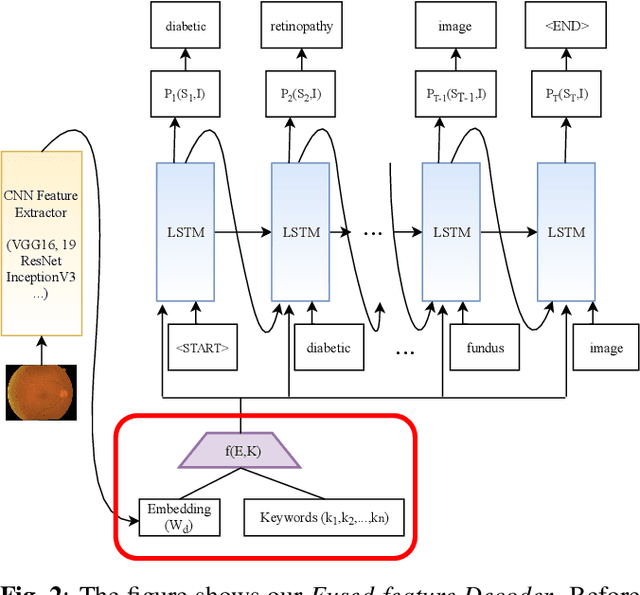

Automatically generating medical reports for retinal images is one of the promising ways to help ophthalmologists reduce their workload and improve work efficiency. In this work, we propose a new context-driven encoding network to automatically generate medical reports for retinal images. The proposed model is mainly composed of a multi-modal input encoder and a fused-feature decoder. Our experimental results show that our proposed method is capable of effectively leveraging the interactive information between the input image and context, i.e., keywords in our case. The proposed method creates more accurate and meaningful reports for retinal images than baseline models and achieves state-of-the-art performance. This performance is shown in several commonly used metrics for the medical report generation task: BLEU-avg (+16%), CIDEr (+10.2%), and ROUGE (+8.6%).
Contextualized Keyword Representations for Multi-modal Retinal Image Captioning
Apr 26, 2021

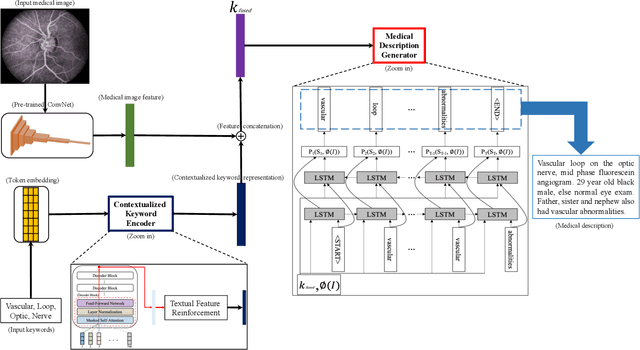
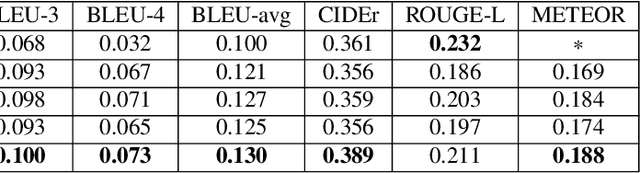
Medical image captioning automatically generates a medical description to describe the content of a given medical image. A traditional medical image captioning model creates a medical description only based on a single medical image input. Hence, an abstract medical description or concept is hard to be generated based on the traditional approach. Such a method limits the effectiveness of medical image captioning. Multi-modal medical image captioning is one of the approaches utilized to address this problem. In multi-modal medical image captioning, textual input, e.g., expert-defined keywords, is considered as one of the main drivers of medical description generation. Thus, encoding the textual input and the medical image effectively are both important for the task of multi-modal medical image captioning. In this work, a new end-to-end deep multi-modal medical image captioning model is proposed. Contextualized keyword representations, textual feature reinforcement, and masked self-attention are used to develop the proposed approach. Based on the evaluation of the existing multi-modal medical image captioning dataset, experimental results show that the proposed model is effective with the increase of +53.2% in BLEU-avg and +18.6% in CIDEr, compared with the state-of-the-art method.
GPT2MVS: Generative Pre-trained Transformer-2 for Multi-modal Video Summarization
Apr 26, 2021
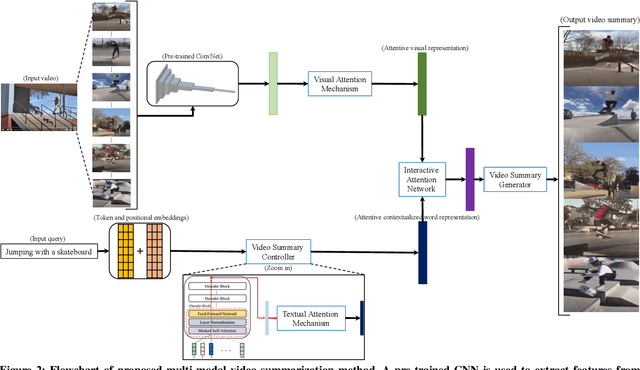
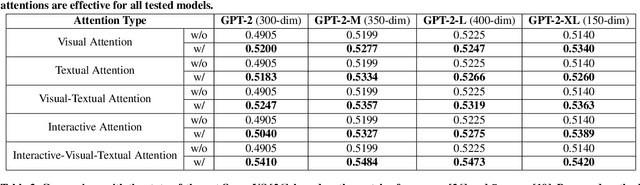
Traditional video summarization methods generate fixed video representations regardless of user interest. Therefore such methods limit users' expectations in content search and exploration scenarios. Multi-modal video summarization is one of the methods utilized to address this problem. When multi-modal video summarization is used to help video exploration, a text-based query is considered as one of the main drivers of video summary generation, as it is user-defined. Thus, encoding the text-based query and the video effectively are both important for the task of multi-modal video summarization. In this work, a new method is proposed that uses a specialized attention network and contextualized word representations to tackle this task. The proposed model consists of a contextualized video summary controller, multi-modal attention mechanisms, an interactive attention network, and a video summary generator. Based on the evaluation of the existing multi-modal video summarization benchmark, experimental results show that the proposed model is effective with the increase of +5.88% in accuracy and +4.06% increase of F1-score, compared with the state-of-the-art method.