 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvangelos Kanoulas
QFMTS: Generating Query-Focused Summaries over Multi-Table Inputs
May 08, 2024
Table summarization is a crucial task aimed at condensing information from tabular data into concise and comprehensible textual summaries. However, existing approaches often fall short of adequately meeting users' information and quality requirements and tend to overlook the complexities of real-world queries. In this paper, we propose a novel method to address these limitations by introducing query-focused multi-table summarization. Our approach, which comprises a table serialization module, a summarization controller, and a large language model (LLM), utilizes textual queries and multiple tables to generate query-dependent table summaries tailored to users' information needs. To facilitate research in this area, we present a comprehensive dataset specifically tailored for this task, consisting of 4909 query-summary pairs, each associated with multiple tables. Through extensive experiments using our curated dataset, we demonstrate the effectiveness of our proposed method compared to baseline approaches. Our findings offer insights into the challenges of complex table reasoning for precise summarization, contributing to the advancement of research in query-focused multi-table summarization.
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Apr 29, 2024Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10\% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Improving the Robustness of Dense Retrievers Against Typos via Multi-Positive Contrastive Learning
Mar 16, 2024Dense retrieval has become the new paradigm in passage retrieval. Despite its effectiveness on typo-free queries, it is not robust when dealing with queries that contain typos. Current works on improving the typo-robustness of dense retrievers combine (i) data augmentation to obtain the typoed queries during training time with (ii) additional robustifying subtasks that aim to align the original, typo-free queries with their typoed variants. Even though multiple typoed variants are available as positive samples per query, some methods assume a single positive sample and a set of negative ones per anchor and tackle the robustifying subtask with contrastive learning; therefore, making insufficient use of the multiple positives (typoed queries). In contrast, in this work, we argue that all available positives can be used at the same time and employ contrastive learning that supports multiple positives (multi-positive). Experimental results on two datasets show that our proposed approach of leveraging all positives simultaneously and employing multi-positive contrastive learning on the robustifying subtask yields improvements in robustness against using contrastive learning with a single positive.
Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
Mar 07, 2024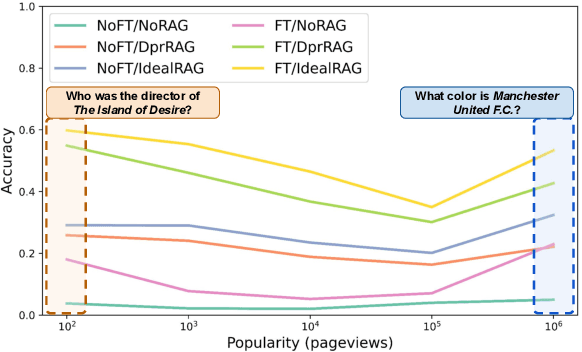
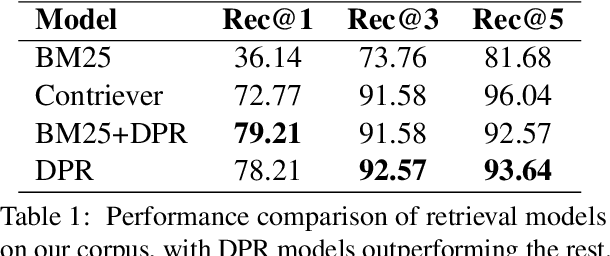
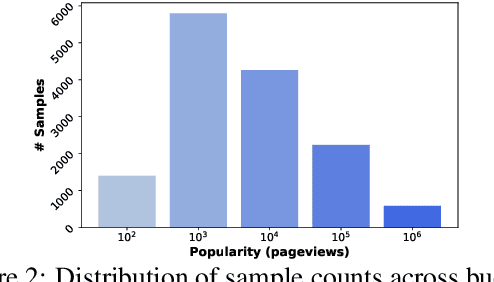
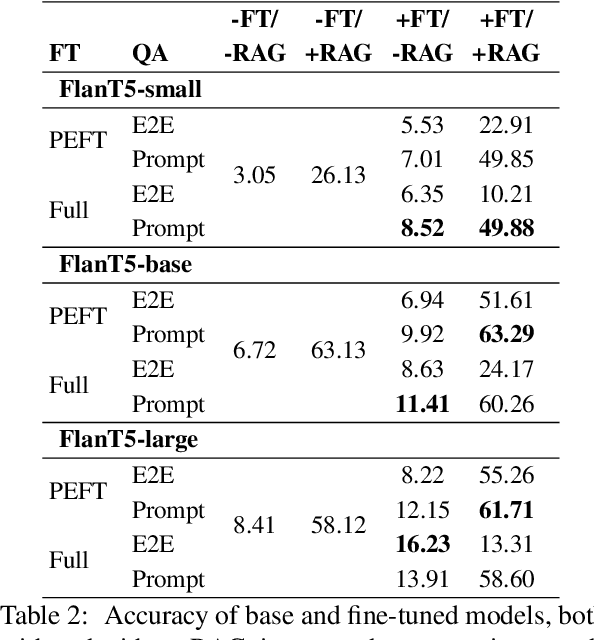
Large language models (LLMs) memorize a vast amount of factual knowledge, exhibiting strong performance across diverse tasks and domains. However, it has been observed that the performance diminishes when dealing with less-popular or low-frequency concepts and entities, for example in domain specific applications. The two prominent approaches to enhance the performance of LLMs on low-frequent topics are: Retrieval Augmented Generation (RAG) and fine-tuning (FT) over synthetic data. This paper explores and evaluates the impact of RAG and FT on customizing LLMs in handling low-frequency entities on question answering task. Our findings indicate that FT significantly boosts the performance across entities of varying popularity, especially in the most and least popular groups, while RAG surpasses other methods. Additionally, the success of both RAG and FT approaches is amplified by advancements in retrieval and data augmentation techniques. We release our data and code at https://github.com/informagi/RAGvsFT.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.
Let the LLMs Talk: Simulating Human-to-Human Conversational QA via Zero-Shot LLM-to-LLM Interactions
Dec 05, 2023Conversational question-answering (CQA) systems aim to create interactive search systems that effectively retrieve information by interacting with users. To replicate human-to-human conversations, existing work uses human annotators to play the roles of the questioner (student) and the answerer (teacher). Despite its effectiveness, challenges exist as human annotation is time-consuming, inconsistent, and not scalable. To address this issue and investigate the applicability of large language models (LLMs) in CQA simulation, we propose a simulation framework that employs zero-shot learner LLMs for simulating teacher-student interactions. Our framework involves two LLMs interacting on a specific topic, with the first LLM acting as a student, generating questions to explore a given search topic. The second LLM plays the role of a teacher by answering questions and is equipped with additional information, including a text on the given topic. We implement both the student and teacher by zero-shot prompting the GPT-4 model. To assess the effectiveness of LLMs in simulating CQA interactions and understand the disparities between LLM- and human-generated conversations, we evaluate the simulated data from various perspectives. We begin by evaluating the teacher's performance through both automatic and human assessment. Next, we evaluate the performance of the student, analyzing and comparing the disparities between questions generated by the LLM and those generated by humans. Furthermore, we conduct extensive analyses to thoroughly examine the LLM performance by benchmarking state-of-the-art reading comprehension models on both datasets. Our results reveal that the teacher LLM generates lengthier answers that tend to be more accurate and complete. The student LLM generates more diverse questions, covering more aspects of a given topic.
Data Augmentation for Conversational AI
Sep 09, 2023Advancements in conversational systems have revolutionized information access, surpassing the limitations of single queries. However, developing dialogue systems requires a large amount of training data, which is a challenge in low-resource domains and languages. Traditional data collection methods like crowd-sourcing are labor-intensive and time-consuming, making them ineffective in this context. Data augmentation (DA) is an affective approach to alleviate the data scarcity problem in conversational systems. This tutorial provides a comprehensive and up-to-date overview of DA approaches in the context of conversational systems. It highlights recent advances in conversation augmentation, open domain and task-oriented conversation generation, and different paradigms of evaluating these models. We also discuss current challenges and future directions in order to help researchers and practitioners to further advance the field in this area.
Stress Testing BERT Anaphora Resolution Models for Reaction Extraction in Chemical Patents
Jun 23, 2023
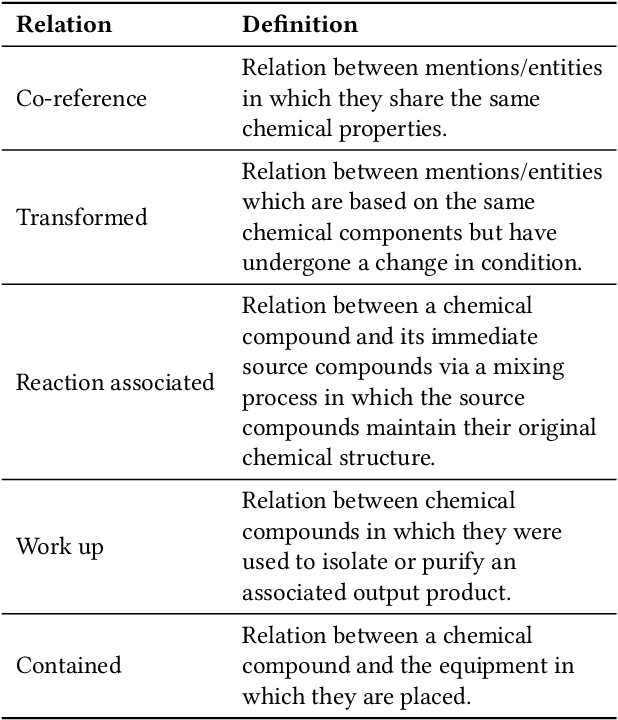
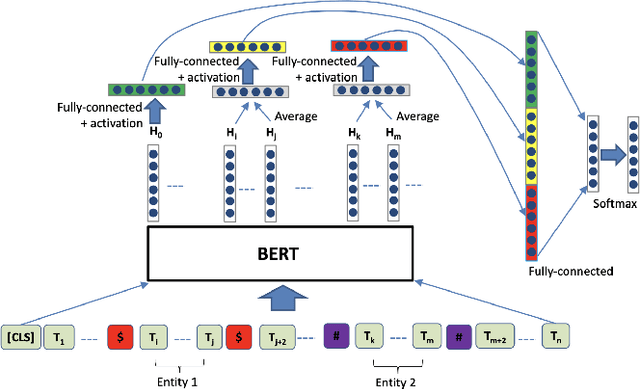

The high volume of published chemical patents and the importance of a timely acquisition of their information gives rise to automating information extraction from chemical patents. Anaphora resolution is an important component of comprehensive information extraction, and is critical for extracting reactions. In chemical patents, there are five anaphoric relations of interest: co-reference, transformed, reaction associated, work up, and contained. Our goal is to investigate how the performance of anaphora resolution models for reaction texts in chemical patents differs in a noise-free and noisy environment and to what extent we can improve the robustness against noise of the model.
MultiTabQA: Generating Tabular Answers for Multi-Table Question Answering
May 24, 2023
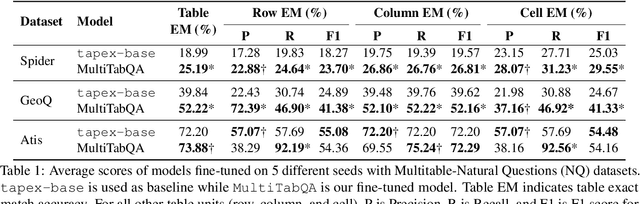
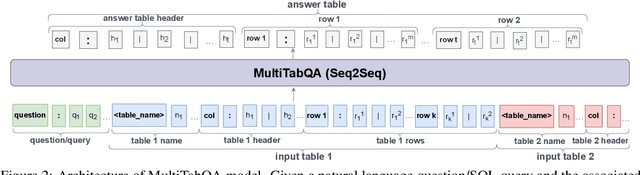
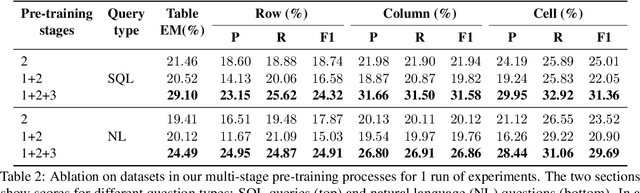
Recent advances in tabular question answering (QA) with large language models are constrained in their coverage and only answer questions over a single table. However, real-world queries are complex in nature, often over multiple tables in a relational database or web page. Single table questions do not involve common table operations such as set operations, Cartesian products (joins), or nested queries. Furthermore, multi-table operations often result in a tabular output, which necessitates table generation capabilities of tabular QA models. To fill this gap, we propose a new task of answering questions over multiple tables. Our model, MultiTabQA, not only answers questions over multiple tables, but also generalizes to generate tabular answers. To enable effective training, we build a pre-training dataset comprising of 132,645 SQL queries and tabular answers. Further, we evaluate the generated tables by introducing table-specific metrics of varying strictness assessing various levels of granularity of the table structure. MultiTabQA outperforms state-of-the-art single table QA models adapted to a multi-table QA setting by finetuning on three datasets: Spider, Atis and GeoQuery.
Generating Synthetic Documents for Cross-Encoder Re-Rankers: A Comparative Study of ChatGPT and Human Experts
May 03, 2023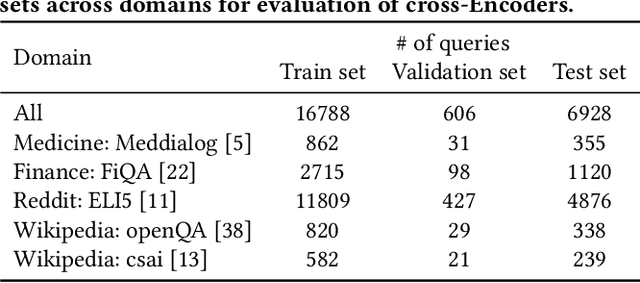


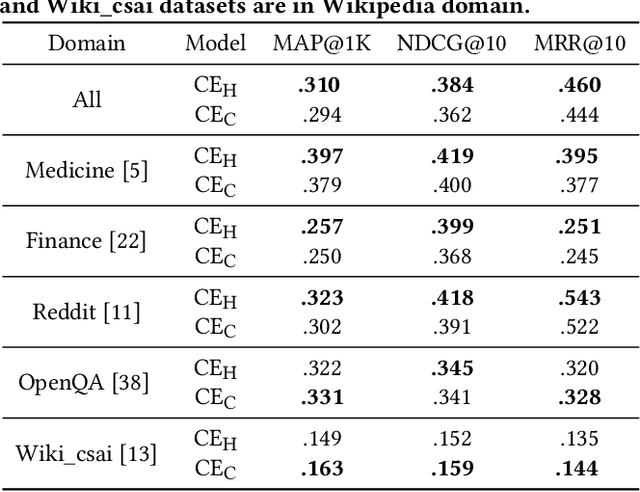
We investigate the usefulness of generative Large Language Models (LLMs) in generating training data for cross-encoder re-rankers in a novel direction: generating synthetic documents instead of synthetic queries. We introduce a new dataset, ChatGPT-RetrievalQA, and compare the effectiveness of models fine-tuned on LLM-generated and human-generated data. Data generated with generative LLMs can be used to augment training data, especially in domains with smaller amounts of labeled data. We build ChatGPT-RetrievalQA based on an existing dataset, human ChatGPT Comparison Corpus (HC3), consisting of public question collections with human responses and answers from ChatGPT. We fine-tune a range of cross-encoder re-rankers on either human-generated or ChatGPT-generated data. Our evaluation on MS MARCO DEV, TREC DL'19, and TREC DL'20 demonstrates that cross-encoder re-ranking models trained on ChatGPT responses are statistically significantly more effective zero-shot re-rankers than those trained on human responses. In a supervised setting, the human-trained re-rankers outperform the LLM-trained re-rankers. Our novel findings suggest that generative LLMs have high potential in generating training data for neural retrieval models. Further work is needed to determine the effect of factually wrong information in the generated responses and test our findings' generalizability with open-source LLMs. We release our data, code, and cross-encoders checkpoints for future work.