 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuzan Verberne
Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study
Apr 05, 2024
For a viewpoint-diverse news recommender, identifying whether two news articles express the same viewpoint is essential. One way to determine "same or different" viewpoint is stance detection. In this paper, we investigate the robustness of operationalization choices for few-shot stance detection, with special attention to modelling stance across different topics. Our experiments test pre-registered hypotheses on stance detection. Specifically, we compare two stance task definitions (Pro/Con versus Same Side Stance), two LLM architectures (bi-encoding versus cross-encoding), and adding Natural Language Inference knowledge, with pre-trained RoBERTa models trained with shots of 100 examples from 7 different stance detection datasets. Some of our hypotheses and claims from earlier work can be confirmed, while others give more inconsistent results. The effect of the Same Side Stance definition on performance differs per dataset and is influenced by other modelling choices. We found no relationship between the number of training topics in the training shots and performance. In general, cross-encoding out-performs bi-encoding, and adding NLI training to our models gives considerable improvement, but these results are not consistent across all datasets. Our results indicate that it is essential to include multiple datasets and systematic modelling experiments when aiming to find robust modelling choices for the concept `stance'.
High Recall, Small Data: The Challenges of Within-System Evaluation in a Live Legal Search System
Mar 27, 2024



This paper illustrates some challenges of common ranking evaluation methods for legal information retrieval (IR). We show these challenges with log data from a live legal search system and two user studies. We provide an overview of aspects of legal IR, and the implications of these aspects for the expected challenges of common evaluation methods: test collections based on explicit and implicit feedback, user surveys, and A/B testing. Next, we illustrate the challenges of common evaluation methods using data from a live, commercial, legal search engine. We specifically focus on methods for monitoring the effectiveness of (continuous) changes to document ranking by a single IR system over time. We show how the combination of characteristics in legal IR systems and limited user data can lead to challenges that cause the common evaluation methods discussed to be sub-optimal. In our future work we will therefore focus on less common evaluation methods, such as cost-based evaluation models.
CAUSE: Counterfactual Assessment of User Satisfaction Estimation in Task-Oriented Dialogue Systems
Mar 27, 2024
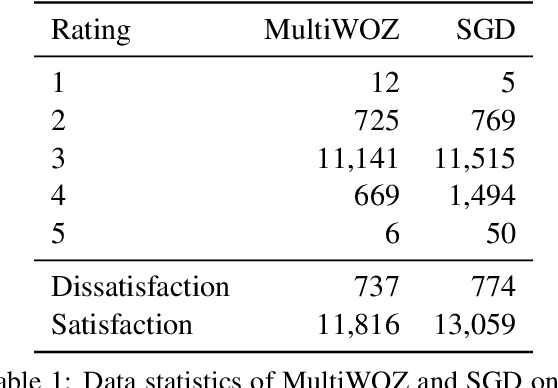

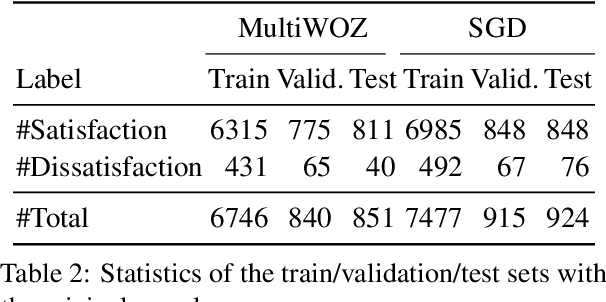
An important unexplored aspect in previous work on user satisfaction estimation for Task-Oriented Dialogue (TOD) systems is their evaluation in terms of robustness for the identification of user dissatisfaction: current benchmarks for user satisfaction estimation in TOD systems are highly skewed towards dialogues for which the user is satisfied. The effect of having a more balanced set of satisfaction labels on performance is unknown. However, balancing the data with more dissatisfactory dialogue samples requires further data collection and human annotation, which is costly and time-consuming. In this work, we leverage large language models (LLMs) and unlock their ability to generate satisfaction-aware counterfactual dialogues to augment the set of original dialogues of a test collection. We gather human annotations to ensure the reliability of the generated samples. We evaluate two open-source LLMs as user satisfaction estimators on our augmented collection against state-of-the-art fine-tuned models. Our experiments show that when used as few-shot user satisfaction estimators, open-source LLMs show higher robustness to the increase in the number of dissatisfaction labels in the test collection than the fine-tuned state-of-the-art models. Our results shed light on the need for data augmentation approaches for user satisfaction estimation in TOD systems. We release our aligned counterfactual dialogues, which are curated by human annotation, to facilitate further research on this topic.
Measuring Bias in a Ranked List using Term-based Representations
Mar 09, 2024In most recent studies, gender bias in document ranking is evaluated with the NFaiRR metric, which measures bias in a ranked list based on an aggregation over the unbiasedness scores of each ranked document. This perspective in measuring the bias of a ranked list has a key limitation: individual documents of a ranked list might be biased while the ranked list as a whole balances the groups' representations. To address this issue, we propose a novel metric called TExFAIR (term exposure-based fairness), which is based on two new extensions to a generic fairness evaluation framework, attention-weighted ranking fairness (AWRF). TExFAIR assesses fairness based on the term-based representation of groups in a ranked list: (i) an explicit definition of associating documents to groups based on probabilistic term-level associations, and (ii) a rank-biased discounting factor (RBDF) for counting non-representative documents towards the measurement of the fairness of a ranked list. We assess TExFAIR on the task of measuring gender bias in passage ranking, and study the relationship between TExFAIR and NFaiRR. Our experiments show that there is no strong correlation between TExFAIR and NFaiRR, which indicates that TExFAIR measures a different dimension of fairness than NFaiRR. With TExFAIR, we extend the AWRF framework to allow for the evaluation of fairness in settings with term-based representations of groups in documents in a ranked list.
Learning to Use Tools via Cooperative and Interactive Agents
Mar 05, 2024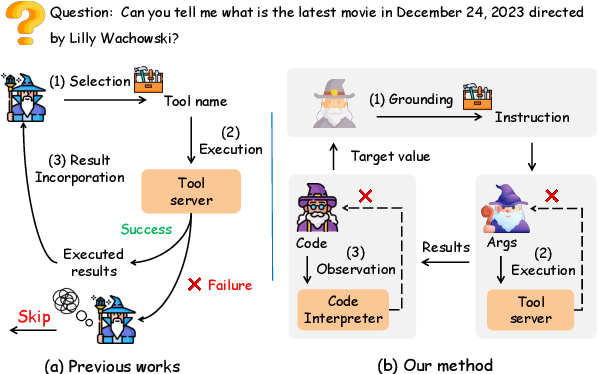
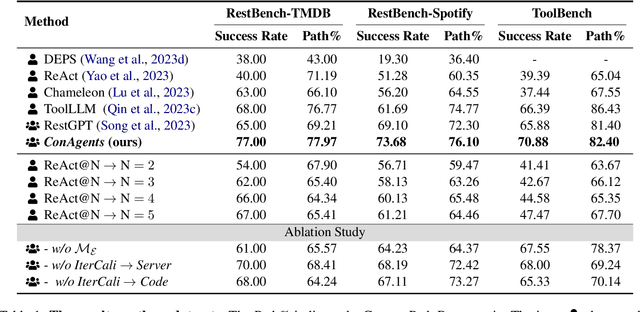
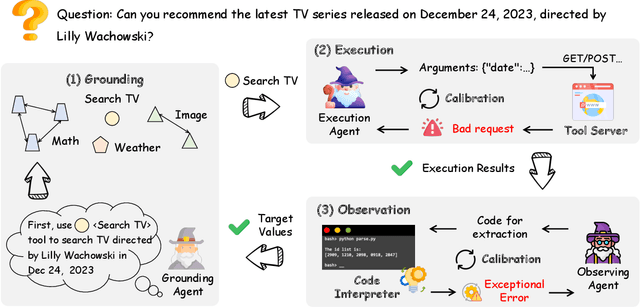
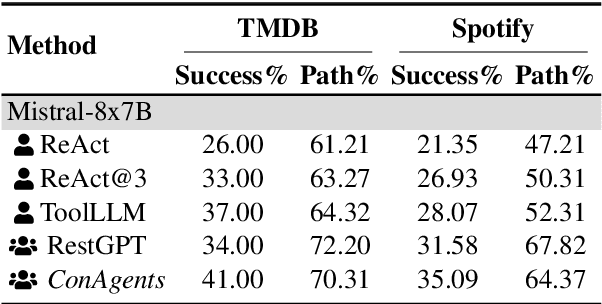
Tool learning empowers large language models (LLMs) as agents to use external tools to extend their capability. Existing methods employ one single LLM-based agent to iteratively select and execute tools, thereafter incorporating the result into the next action prediction. However, they still suffer from potential performance degradation when addressing complex tasks due to: (1) the limitation of the inherent capability of a single LLM to perform diverse actions, and (2) the struggle to adaptively correct mistakes when the task fails. To mitigate these problems, we propose the ConAgents, a Cooperative and interactive Agents framework, which modularizes the workflow of tool learning into Grounding, Execution, and Observing agents. We also introduce an iterative calibration (IterCali) method, enabling the agents to adapt themselves based on the feedback from the tool environment. Experiments conducted on three datasets demonstrate the superiority of our ConAgents (e.g., 6 point improvement over the SOTA baseline). We further provide fine-granularity analysis for the efficiency and consistency of our framework.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.
A Multi-Agent Conversational Recommender System
Feb 02, 2024Due to strong capabilities in conducting fluent, multi-turn conversations with users, Large Language Models (LLMs) have the potential to further improve the performance of Conversational Recommender System (CRS). Unlike the aimless chit-chat that LLM excels at, CRS has a clear target. So it is imperative to control the dialogue flow in the LLM to successfully recommend appropriate items to the users. Furthermore, user feedback in CRS can assist the system in better modeling user preferences, which has been ignored by existing studies. However, simply prompting LLM to conduct conversational recommendation cannot address the above two key challenges. In this paper, we propose Multi-Agent Conversational Recommender System (MACRS) which contains two essential modules. First, we design a multi-agent act planning framework, which can control the dialogue flow based on four LLM-based agents. This cooperative multi-agent framework will generate various candidate responses based on different dialogue acts and then choose the most appropriate response as the system response, which can help MACRS plan suitable dialogue acts. Second, we propose a user feedback-aware reflection mechanism which leverages user feedback to reason errors made in previous turns to adjust the dialogue act planning, and higher-level user information from implicit semantics. We conduct extensive experiments based on user simulator to demonstrate the effectiveness of MACRS in recommendation and user preferences collection. Experimental results illustrate that MACRS demonstrates an improvement in user interaction experience compared to directly using LLMs.
Answer Retrieval in Legal Community Question Answering
Jan 09, 2024The task of answer retrieval in the legal domain aims to help users to seek relevant legal advice from massive amounts of professional responses. Two main challenges hinder applying existing answer retrieval approaches in other domains to the legal domain: (1) a huge knowledge gap between lawyers and non-professionals; and (2) a mix of informal and formal content on legal QA websites. To tackle these challenges, we propose CE_FS, a novel cross-encoder (CE) re-ranker based on the fine-grained structured inputs. CE_FS uses additional structured information in the CQA data to improve the effectiveness of cross-encoder re-rankers. Furthermore, we propose LegalQA: a real-world benchmark dataset for evaluating answer retrieval in the legal domain. Experiments conducted on LegalQA show that our proposed method significantly outperforms strong cross-encoder re-rankers fine-tuned on MS MARCO. Our novel finding is that adding the question tags of each question besides the question description and title into the input of cross-encoder re-rankers structurally boosts the rankers' effectiveness. While we study our proposed method in the legal domain, we believe that our method can be applied in similar applications in other domains.
ChatGPT as a commenter to the news: can LLMs generate human-like opinions?
Dec 21, 2023ChatGPT, GPT-3.5, and other large language models (LLMs) have drawn significant attention since their release, and the abilities of these models have been investigated for a wide variety of tasks. In this research we investigate to what extent GPT-3.5 can generate human-like comments on Dutch news articles. We define human likeness as `not distinguishable from human comments', approximated by the difficulty of automatic classification between human and GPT comments. We analyze human likeness across multiple prompting techniques. In particular, we utilize zero-shot, few-shot and context prompts, for two generated personas. We found that our fine-tuned BERT models can easily distinguish human-written comments from GPT-3.5 generated comments, with none of the used prompting methods performing noticeably better. We further analyzed that human comments consistently showed higher lexical diversity than GPT-generated comments. This indicates that although generative LLMs can generate fluent text, their capability to create human-like opinionated comments is still limited.
ChiSCor: A Corpus of Freely Told Fantasy Stories by Dutch Children for Computational Linguistics and Cognitive Science
Oct 31, 2023In this resource paper we release ChiSCor, a new corpus containing 619 fantasy stories, told freely by 442 Dutch children aged 4-12. ChiSCor was compiled for studying how children render character perspectives, and unravelling language and cognition in development, with computational tools. Unlike existing resources, ChiSCor's stories were produced in natural contexts, in line with recent calls for more ecologically valid datasets. ChiSCor hosts text, audio, and annotations for character complexity and linguistic complexity. Additional metadata (e.g. education of caregivers) is available for one third of the Dutch children. ChiSCor also includes a small set of 62 English stories. This paper details how ChiSCor was compiled and shows its potential for future work with three brief case studies: i) we show that the syntactic complexity of stories is strikingly stable across children's ages; ii) we extend work on Zipfian distributions in free speech and show that ChiSCor obeys Zipf's law closely, reflecting its social context; iii) we show that even though ChiSCor is relatively small, the corpus is rich enough to train informative lemma vectors that allow us to analyse children's language use. We end with a reflection on the value of narrative datasets in computational linguistics.