 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarco Mondelli
Average gradient outer product as a mechanism for deep neural collapse
Feb 21, 2024
Deep Neural Collapse (DNC) refers to the surprisingly rigid structure of the data representations in the final layers of Deep Neural Networks (DNNs). Though the phenomenon has been measured in a wide variety of settings, its emergence is only partially understood. In this work, we provide substantial evidence that DNC formation occurs primarily through deep feature learning with the average gradient outer product (AGOP). This takes a step further compared to efforts that explain neural collapse via feature-agnostic approaches, such as the unconstrained features model. We proceed by providing evidence that the right singular vectors and values of the weights are responsible for the majority of within-class variability collapse in DNNs. As shown in recent work, this singular structure is highly correlated with that of the AGOP. We then establish experimentally and theoretically that AGOP induces neural collapse in a randomly initialized neural network. In particular, we demonstrate that Deep Recursive Feature Machines, a method originally introduced as an abstraction for AGOP feature learning in convolutional neural networks, exhibits DNC.
Compression of Structured Data with Autoencoders: Provable Benefit of Nonlinearities and Depth
Feb 07, 2024Autoencoders are a prominent model in many empirical branches of machine learning and lossy data compression. However, basic theoretical questions remain unanswered even in a shallow two-layer setting. In particular, to what degree does a shallow autoencoder capture the structure of the underlying data distribution? For the prototypical case of the 1-bit compression of sparse Gaussian data, we prove that gradient descent converges to a solution that completely disregards the sparse structure of the input. Namely, the performance of the algorithm is the same as if it was compressing a Gaussian source - with no sparsity. For general data distributions, we give evidence of a phase transition phenomenon in the shape of the gradient descent minimizer, as a function of the data sparsity: below the critical sparsity level, the minimizer is a rotation taken uniformly at random (just like in the compression of non-sparse data); above the critical sparsity, the minimizer is the identity (up to a permutation). Finally, by exploiting a connection with approximate message passing algorithms, we show how to improve upon Gaussian performance for the compression of sparse data: adding a denoising function to a shallow architecture already reduces the loss provably, and a suitable multi-layer decoder leads to a further improvement. We validate our findings on image datasets, such as CIFAR-10 and MNIST.
Towards Understanding the Word Sensitivity of Attention Layers: A Study via Random Features
Feb 05, 2024Unveiling the reasons behind the exceptional success of transformers requires a better understanding of why attention layers are suitable for NLP tasks. In particular, such tasks require predictive models to capture contextual meaning which often depends on one or few words, even if the sentence is long. Our work studies this key property, dubbed word sensitivity (WS), in the prototypical setting of random features. We show that attention layers enjoy high WS, namely, there exists a vector in the space of embeddings that largely perturbs the random attention features map. The argument critically exploits the role of the softmax in the attention layer, highlighting its benefit compared to other activations (e.g., ReLU). In contrast, the WS of standard random features is of order $1/\sqrt{n}$, $n$ being the number of words in the textual sample, and thus it decays with the length of the context. We then translate these results on the word sensitivity into generalization bounds: due to their low WS, random features provably cannot learn to distinguish between two sentences that differ only in a single word; in contrast, due to their high WS, random attention features have higher generalization capabilities. We validate our theoretical results with experimental evidence over the BERT-Base word embeddings of the imdb review dataset.
Spectral Estimators for Structured Generalized Linear Models via Approximate Message Passing
Aug 28, 2023

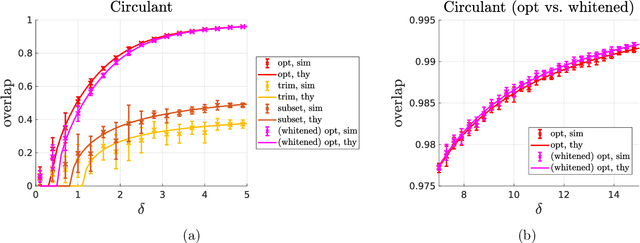
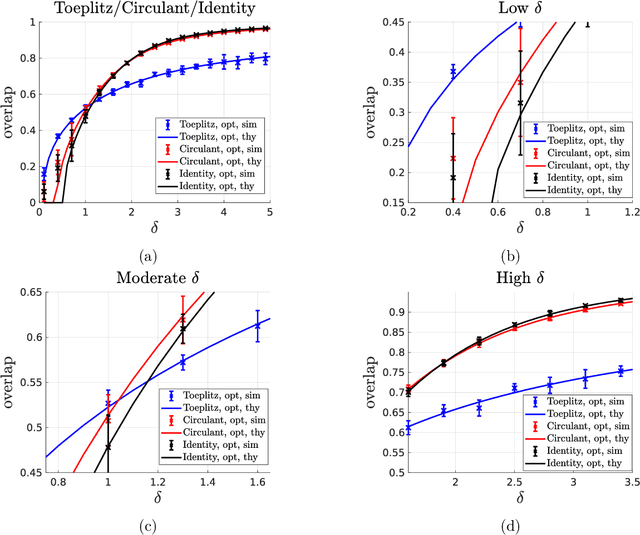
We consider the problem of parameter estimation from observations given by a generalized linear model. Spectral methods are a simple yet effective approach for estimation: they estimate the parameter via the principal eigenvector of a matrix obtained by suitably preprocessing the observations. Despite their wide use, a rigorous performance characterization of spectral estimators, as well as a principled way to preprocess the data, is available only for unstructured (i.e., i.i.d. Gaussian and Haar) designs. In contrast, real-world design matrices are highly structured and exhibit non-trivial correlations. To address this problem, we consider correlated Gaussian designs which capture the anisotropic nature of the measurements via a feature covariance matrix $\Sigma$. Our main result is a precise asymptotic characterization of the performance of spectral estimators in this setting. This then allows to identify the optimal preprocessing that minimizes the number of samples needed to meaningfully estimate the parameter. Remarkably, such an optimal spectral estimator depends on $\Sigma$ only through its normalized trace, which can be consistently estimated from the data. Numerical results demonstrate the advantage of our principled approach over previous heuristic methods. Existing analyses of spectral estimators crucially rely on the rotational invariance of the design matrix. This key assumption does not hold for correlated Gaussian designs. To circumvent this difficulty, we develop a novel strategy based on designing and analyzing an approximate message passing algorithm whose fixed point coincides with the desired spectral estimator. Our methodology is general, and opens the way to the precise characterization of spiked matrices and of the corresponding spectral methods in a variety of settings.
Improved Convergence of Score-Based Diffusion Models via Prediction-Correction
May 23, 2023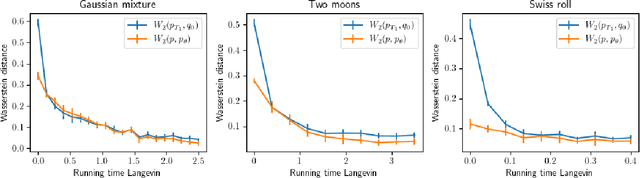
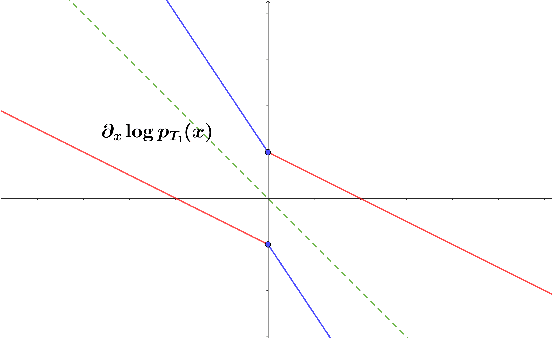
Score-based generative models (SGMs) are powerful tools to sample from complex data distributions. Their underlying idea is to (i) run a forward process for time $T_1$ by adding noise to the data, (ii) estimate its score function, and (iii) use such estimate to run a reverse process. As the reverse process is initialized with the stationary distribution of the forward one, the existing analysis paradigm requires $T_1\to\infty$. This is however problematic: from a theoretical viewpoint, for a given precision of the score approximation, the convergence guarantee fails as $T_1$ diverges; from a practical viewpoint, a large $T_1$ increases computational costs and leads to error propagation. This paper addresses the issue by considering a version of the popular predictor-corrector scheme: after running the forward process, we first estimate the final distribution via an inexact Langevin dynamics and then revert the process. Our key technical contribution is to provide convergence guarantees in Wasserstein distance which require to run the forward process only for a finite time $T_1$. Our bounds exhibit a mild logarithmic dependence on the input dimension and the subgaussian norm of the target distribution, have minimal assumptions on the data, and require only to control the $L^2$ loss on the score approximation, which is the quantity minimized in practice.
Deep Neural Collapse Is Provably Optimal for the Deep Unconstrained Features Model
May 22, 2023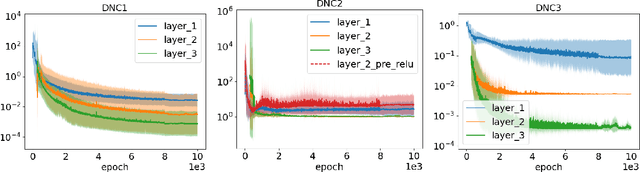

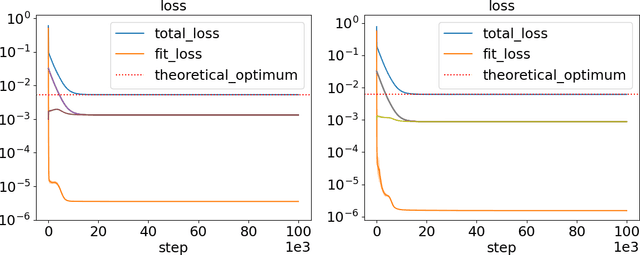
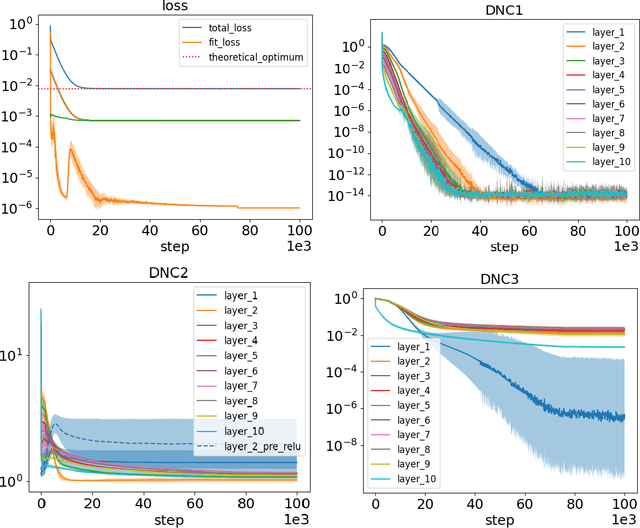
Neural collapse (NC) refers to the surprising structure of the last layer of deep neural networks in the terminal phase of gradient descent training. Recently, an increasing amount of experimental evidence has pointed to the propagation of NC to earlier layers of neural networks. However, while the NC in the last layer is well studied theoretically, much less is known about its multi-layered counterpart - deep neural collapse (DNC). In particular, existing work focuses either on linear layers or only on the last two layers at the price of an extra assumption. Our paper fills this gap by generalizing the established analytical framework for NC - the unconstrained features model - to multiple non-linear layers. Our key technical contribution is to show that, in a deep unconstrained features model, the unique global optimum for binary classification exhibits all the properties typical of DNC. This explains the existing experimental evidence of DNC. We also empirically show that (i) by optimizing deep unconstrained features models via gradient descent, the resulting solution agrees well with our theory, and (ii) trained networks recover the unconstrained features suitable for the occurrence of DNC, thus supporting the validity of this modeling principle.
Stability, Generalization and Privacy: Precise Analysis for Random and NTK Features
May 20, 2023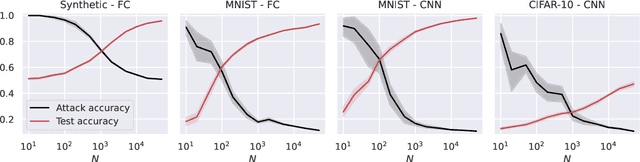

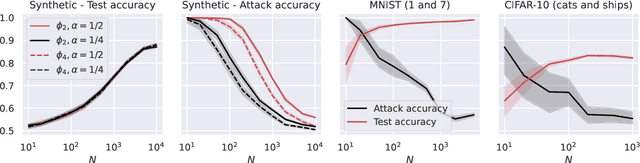
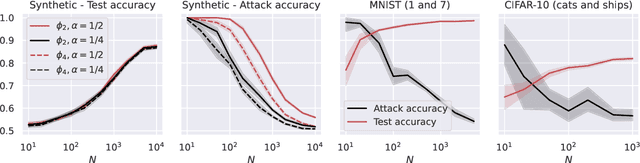
Deep learning models can be vulnerable to recovery attacks, raising privacy concerns to users, and widespread algorithms such as empirical risk minimization (ERM) often do not directly enforce safety guarantees. In this paper, we study the safety of ERM-trained models against a family of powerful black-box attacks. Our analysis quantifies this safety via two separate terms: (i) the model stability with respect to individual training samples, and (ii) the feature alignment between the attacker query and the original data. While the first term is well established in learning theory and it is connected to the generalization error in classical work, the second one is, to the best of our knowledge, novel. Our key technical result provides a precise characterization of the feature alignment for the two prototypical settings of random features (RF) and neural tangent kernel (NTK) regression. This proves that privacy strengthens with an increase in the generalization capability, unveiling also the role of the activation function. Numerical experiments show a behavior in agreement with our theory not only for the RF and NTK models, but also for deep neural networks trained on standard datasets (MNIST, CIFAR-10).
Mismatched estimation of non-symmetric rank-one matrices corrupted by structured noise
Feb 08, 2023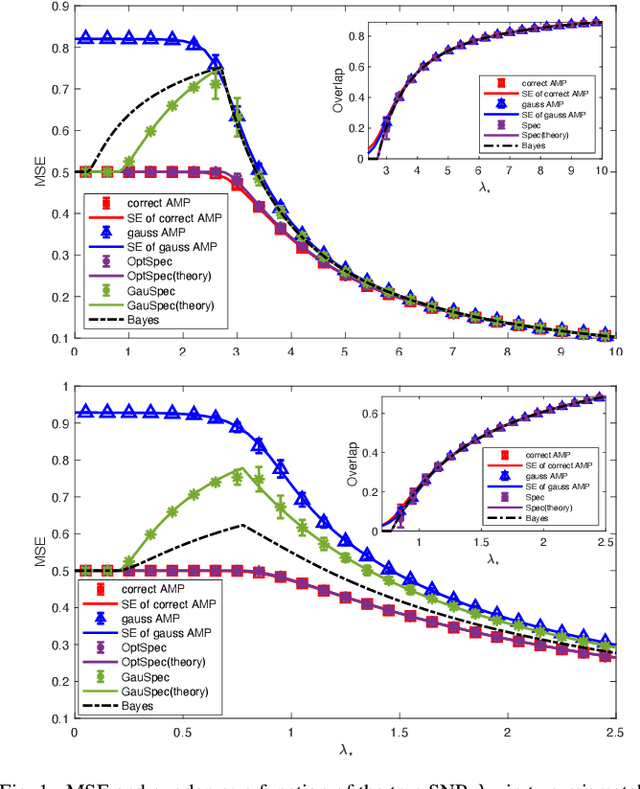
We study the performance of a Bayesian statistician who estimates a rank-one signal corrupted by non-symmetric rotationally invariant noise with a generic distribution of singular values. As the signal-to-noise ratio and the noise structure are unknown, a Gaussian setup is incorrectly assumed. We derive the exact analytic expression for the error of the mismatched Bayes estimator and also provide the analysis of an approximate message passing (AMP) algorithm. The first result exploits the asymptotic behavior of spherical integrals for rectangular matrices and of low-rank matrix perturbations; the second one relies on the design and analysis of an auxiliary AMP. The numerical experiments show that there is a performance gap between the AMP and Bayes estimators, which is due to the incorrect estimation of the signal norm.
Beyond the Universal Law of Robustness: Sharper Laws for Random Features and Neural Tangent Kernels
Feb 03, 2023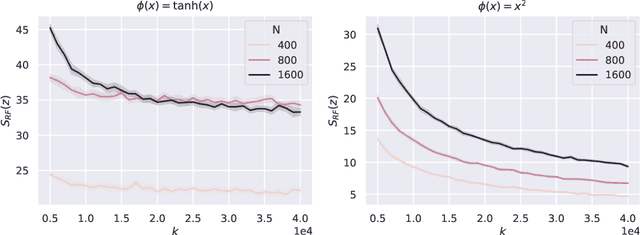


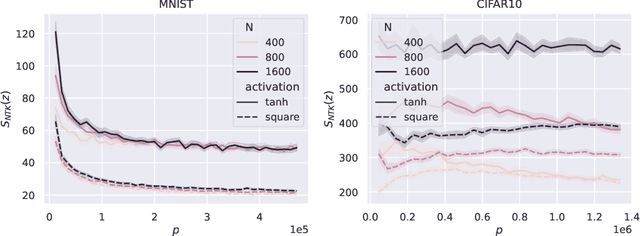
Machine learning models are vulnerable to adversarial perturbations, and a thought-provoking paper by Bubeck and Sellke has analyzed this phenomenon through the lens of over-parameterization: interpolating smoothly the data requires significantly more parameters than simply memorizing it. However, this "universal" law provides only a necessary condition for robustness, and it is unable to discriminate between models. In this paper, we address these gaps by focusing on empirical risk minimization in two prototypical settings, namely, random features and the neural tangent kernel (NTK). We prove that, for random features, the model is not robust for any degree of over-parameterization, even when the necessary condition coming from the universal law of robustness is satisfied. In contrast, for even activations, the NTK model meets the universal lower bound, and it is robust as soon as the necessary condition on over-parameterization is fulfilled. This also addresses a conjecture in prior work by Bubeck, Li and Nagaraj. Our analysis decouples the effect of the kernel of the model from an "interaction matrix", which describes the interaction with the test data and captures the effect of the activation. Our theoretical results are corroborated by numerical evidence on both synthetic and standard datasets (MNIST, CIFAR-10).
Fundamental Limits of Two-layer Autoencoders, and Achieving Them with Gradient Methods
Dec 27, 2022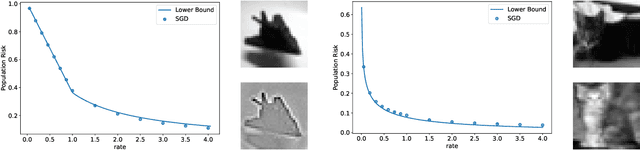
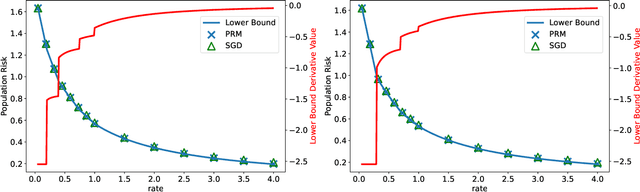
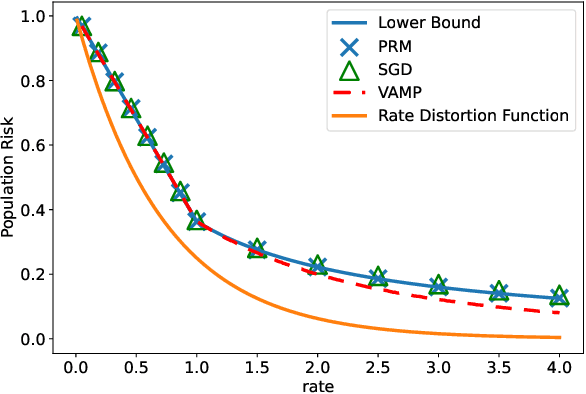
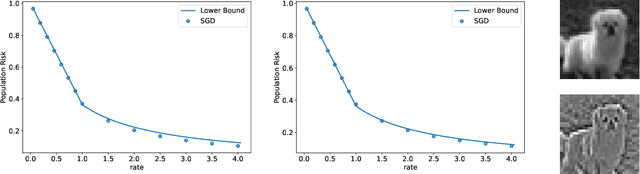
Autoencoders are a popular model in many branches of machine learning and lossy data compression. However, their fundamental limits, the performance of gradient methods and the features learnt during optimization remain poorly understood, even in the two-layer setting. In fact, earlier work has considered either linear autoencoders or specific training regimes (leading to vanishing or diverging compression rates). Our paper addresses this gap by focusing on non-linear two-layer autoencoders trained in the challenging proportional regime in which the input dimension scales linearly with the size of the representation. Our results characterize the minimizers of the population risk, and show that such minimizers are achieved by gradient methods; their structure is also unveiled, thus leading to a concise description of the features obtained via training. For the special case of a sign activation function, our analysis establishes the fundamental limits for the lossy compression of Gaussian sources via (shallow) autoencoders. Finally, while the results are proved for Gaussian data, numerical simulations on standard datasets display the universality of the theoretical predictions.