 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMario Frank
Role Mining with Probabilistic Models
Jan 04, 2013
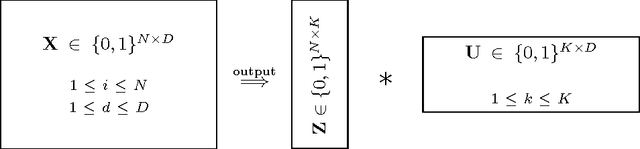
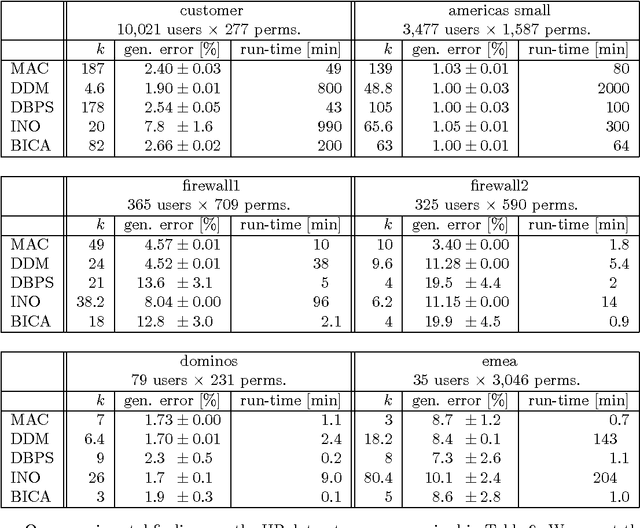

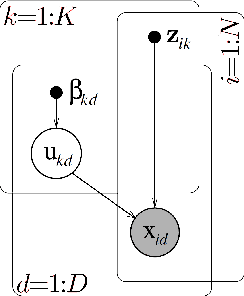
Role mining tackles the problem of finding a role-based access control (RBAC) configuration, given an access-control matrix assigning users to access permissions as input. Most role mining approaches work by constructing a large set of candidate roles and use a greedy selection strategy to iteratively pick a small subset such that the differences between the resulting RBAC configuration and the access control matrix are minimized. In this paper, we advocate an alternative approach that recasts role mining as an inference problem rather than a lossy compression problem. Instead of using combinatorial algorithms to minimize the number of roles needed to represent the access-control matrix, we derive probabilistic models to learn the RBAC configuration that most likely underlies the given matrix. Our models are generative in that they reflect the way that permissions are assigned to users in a given RBAC configuration. We additionally model how user-permission assignments that conflict with an RBAC configuration emerge and we investigate the influence of constraints on role hierarchies and on the number of assignments. In experiments with access-control matrices from real-world enterprises, we compare our proposed models with other role mining methods. Our results show that our probabilistic models infer roles that generalize well to new system users for a wide variety of data, while other models' generalization abilities depend on the dataset given.
Mining Permission Request Patterns from Android and Facebook Applications (extended author version)
Oct 08, 2012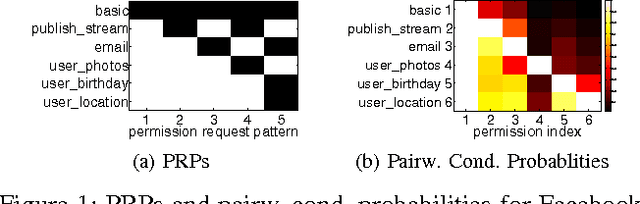
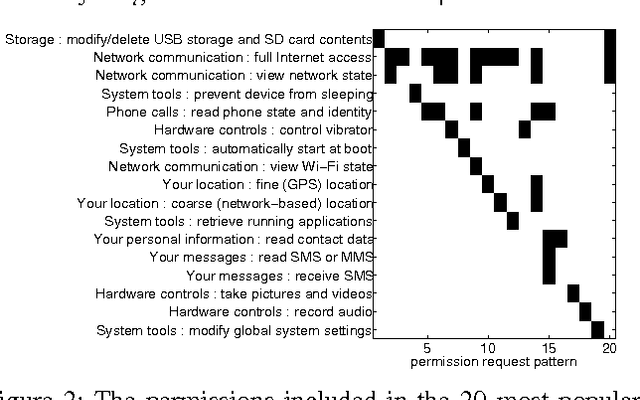
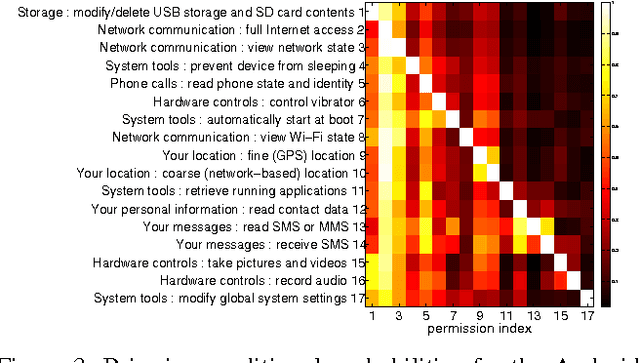
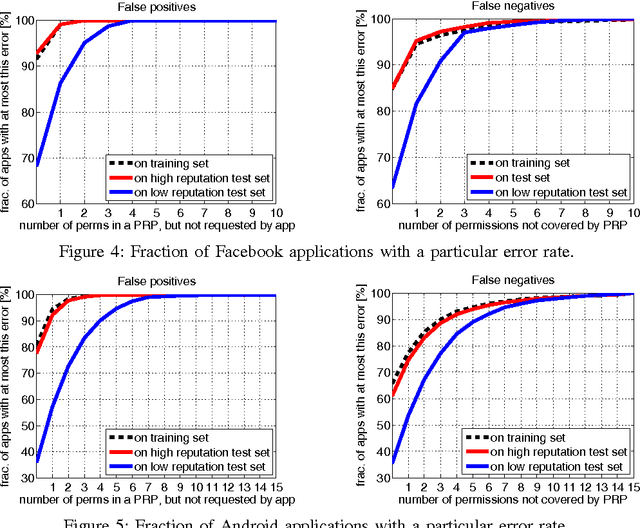
Android and Facebook provide third-party applications with access to users' private data and the ability to perform potentially sensitive operations (e.g., post to a user's wall or place phone calls). As a security measure, these platforms restrict applications' privileges with permission systems: users must approve the permissions requested by applications before the applications can make privacy- or security-relevant API calls. However, recent studies have shown that users often do not understand permission requests and lack a notion of typicality of requests. As a first step towards simplifying permission systems, we cluster a corpus of 188,389 Android applications and 27,029 Facebook applications to find patterns in permission requests. Using a method for Boolean matrix factorization for finding overlapping clusters, we find that Facebook permission requests follow a clear structure that exhibits high stability when fitted with only five clusters, whereas Android applications demonstrate more complex permission requests. We also find that low-reputation applications often deviate from the permission request patterns that we identified for high-reputation applications suggesting that permission request patterns are indicative for user satisfaction or application quality.
Touchalytics: On the Applicability of Touchscreen Input as a Behavioral Biometric for Continuous Authentication
Oct 08, 2012

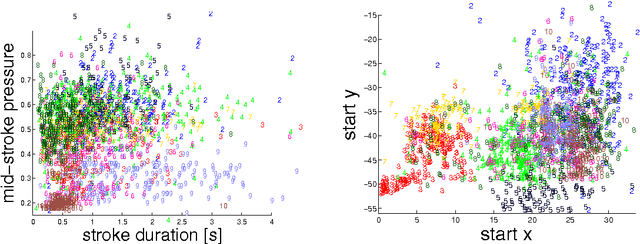
We investigate whether a classifier can continuously authenticate users based on the way they interact with the touchscreen of a smart phone. We propose a set of 30 behavioral touch features that can be extracted from raw touchscreen logs and demonstrate that different users populate distinct subspaces of this feature space. In a systematic experiment designed to test how this behavioral pattern exhibits consistency over time, we collected touch data from users interacting with a smart phone using basic navigation maneuvers, i.e., up-down and left-right scrolling. We propose a classification framework that learns the touch behavior of a user during an enrollment phase and is able to accept or reject the current user by monitoring interaction with the touch screen. The classifier achieves a median equal error rate of 0% for intra-session authentication, 2%-3% for inter-session authentication and below 4% when the authentication test was carried out one week after the enrollment phase. While our experimental findings disqualify this method as a standalone authentication mechanism for long-term authentication, it could be implemented as a means to extend screen-lock time or as a part of a multi-modal biometric authentication system.
* to appear at IEEE Transactions on Information Forensics & Security; Download data from http://www.mariofrank.net/touchalytics/
Selecting the rank of truncated SVD by Maximum Approximation Capacity
Jun 08, 2011

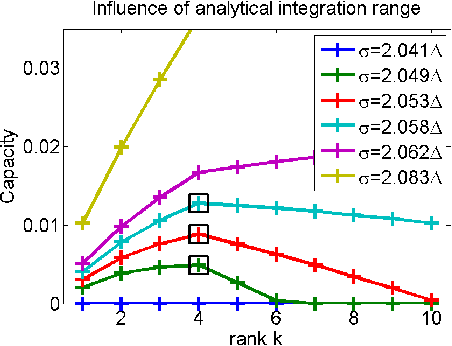

Truncated Singular Value Decomposition (SVD) calculates the closest rank-$k$ approximation of a given input matrix. Selecting the appropriate rank $k$ defines a critical model order choice in most applications of SVD. To obtain a principled cut-off criterion for the spectrum, we convert the underlying optimization problem into a noisy channel coding problem. The optimal approximation capacity of this channel controls the appropriate strength of regularization to suppress noise. In simulation experiments, this information theoretic method to determine the optimal rank competes with state-of-the art model selection techniques.
* 7 pages, 5 figures; Will be presented at the IEEE International Symposium on Information Theory (ISIT) 2011. The conference version has only 5 pages. This version has an extended appendix