 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMark A. Kon
Coupled VAE: Improved Accuracy and Robustness of a Variational Autoencoder
Jun 05, 2019
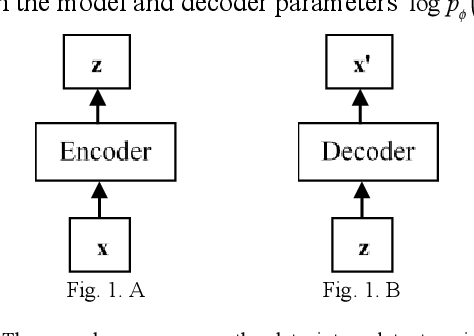
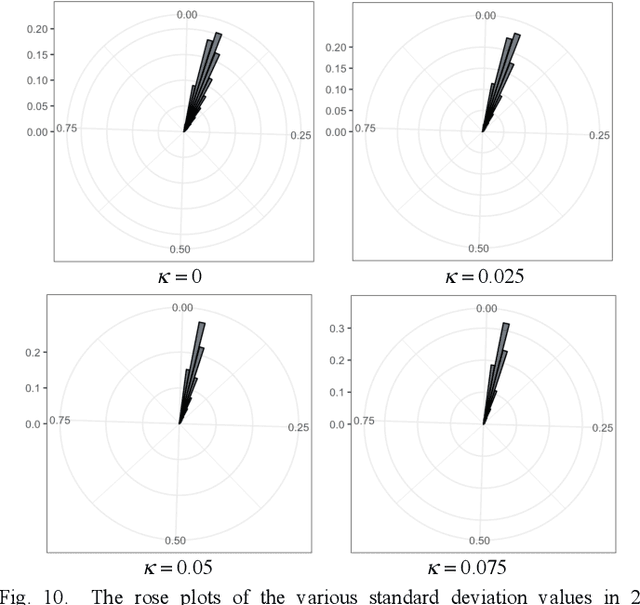
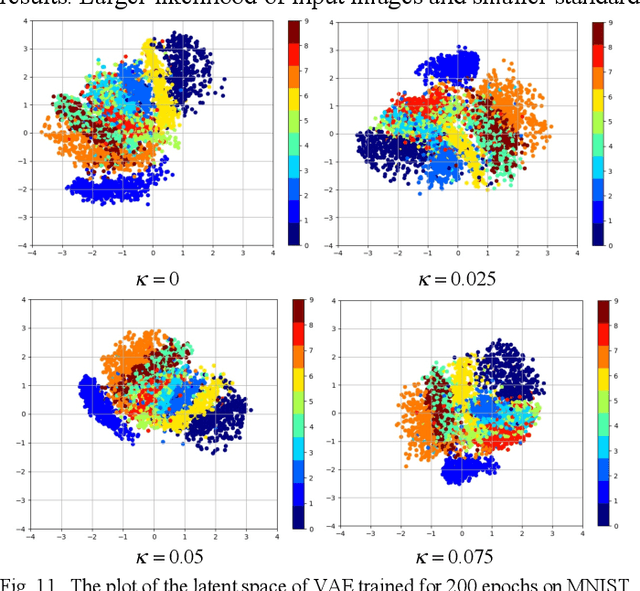
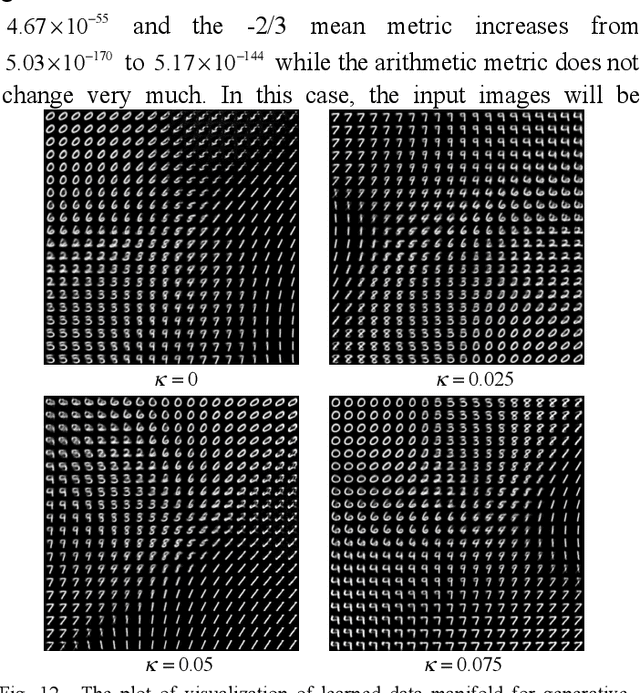
We present a coupled Variational Auto-Encoder (VAE) method that improves the accuracy and robustness of the probabilistic inferences on represented data. The new method models the dependency between input feature vectors (images) and weighs the outliers with a higher penalty by generalizing the original loss function to the coupled entropy function, using the principles of nonlinear statistical coupling. We evaluate the performance of the coupled VAE model using the MNIST dataset. Compared with the traditional VAE algorithm, the output images generated by the coupled VAE method are clearer and less blurry. The visualization of the input images embedded in 2D latent variable space provides a deeper insight into the structure of new model with coupled loss function: the latent variable has a smaller deviation and the output values are generated by a more compact latent space. We analyze the histogram of the likelihoods of the input images using the generalized mean, which measures the model's accuracy as a function of the relative risk. The neutral accuracy, which is the geometric mean and is consistent with a measure of the Shannon cross-entropy, is improved. The robust accuracy, measured by the -2/3 generalized mean, is also improved. And the decisive accuracy, measured by the arithmetic mean, is unchanged.
A complexity analysis of statistical learning algorithms
Dec 19, 2012We apply information-based complexity analysis to support vector machine (SVM) algorithms, with the goal of a comprehensive continuous algorithmic analysis of such algorithms. This involves complexity measures in which some higher order operations (e.g., certain optimizations) are considered primitive for the purposes of measuring complexity. We consider classes of information operators and algorithms made up of scaled families, and investigate the utility of scaling the complexities to minimize error. We look at the division of statistical learning into information and algorithmic components, at the complexities of each, and at applications to support vector machine (SVM) and more general machine learning algorithms. We give applications to SVM algorithms graded into linear and higher order components, and give an example in biomedical informatics.
On the probabilistic continuous complexity conjecture
Dec 06, 2012In this paper we prove the probabilistic continuous complexity conjecture. In continuous complexity theory, this states that the complexity of solving a continuous problem with probability approaching 1 converges (in this limit) to the complexity of solving the same problem in its worst case. We prove the conjecture holds if and only if space of problem elements is uniformly convex. The non-uniformly convex case has a striking counterexample in the problem of identifying a Brownian path in Wiener space, where it is shown that probabilistic complexity converges to only half of the worst case complexity in this limit.
On Some Integrated Approaches to Inference
Dec 05, 2012We present arguments for the formulation of unified approach to different standard continuous inference methods from partial information. It is claimed that an explicit partition of information into a priori (prior knowledge) and a posteriori information (data) is an important way of standardizing inference approaches so that they can be compared on a normative scale, and so that notions of optimal algorithms become farther-reaching. The inference methods considered include neural network approaches, information-based complexity, and Monte Carlo, spline, and regularization methods. The model is an extension of currently used continuous complexity models, with a class of algorithms in the form of optimization methods, in which an optimization functional (involving the data) is minimized. This extends the family of current approaches in continuous complexity theory, which include the use of interpolatory algorithms in worst and average case settings.
Empirical Normalization for Quadratic Discriminant Analysis and Classifying Cancer Subtypes
Oct 29, 2012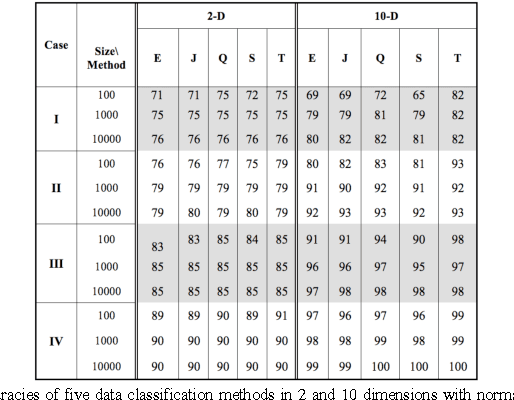
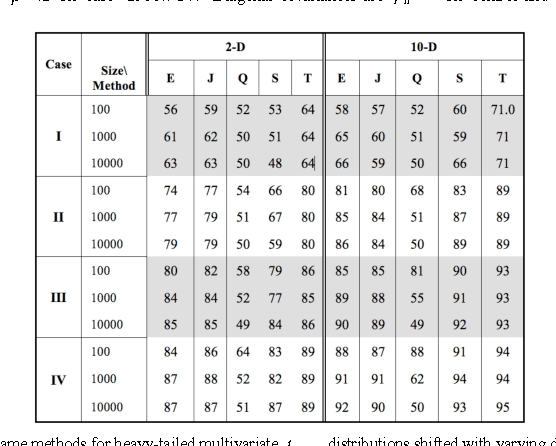
We introduce a new discriminant analysis method (Empirical Discriminant Analysis or EDA) for binary classification in machine learning. Given a dataset of feature vectors, this method defines an empirical feature map transforming the training and test data into new data with components having Gaussian empirical distributions. This map is an empirical version of the Gaussian copula used in probability and mathematical finance. The purpose is to form a feature mapped dataset as close as possible to Gaussian, after which standard quadratic discriminants can be used for classification. We discuss this method in general, and apply it to some datasets in computational biology.