 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthew Lease
Benchmark Transparency: Measuring the Impact of Data on Evaluation
Mar 31, 2024
In this paper we present an exploratory research on quantifying the impact that data distribution has on the performance and evaluation of NLP models. We propose an automated framework that measures the data point distribution across 6 different dimensions: ambiguity, difficulty, discriminability, length, noise, and perplexity. We use disproportional stratified sampling to measure how much the data distribution affects absolute (Acc/F1) and relative (Rank) model performance. We experiment on 2 different datasets (SQUAD and MNLI) and test a total of 135 different models (125 on SQUAD and 10 on MNLI). We demonstrate that without explicit control of the data distribution, standard evaluation frameworks are inconsistent and unreliable. We find that the impact of the data is statistically significant and is often larger than the impact of changing the metric. In a second set of experiments, we demonstrate that the impact of data on evaluation is not just observable, but also predictable. We propose to use benchmark transparency as a method for comparing datasets and quantifying the similarity between them. We find that the ``dataset similarity vector'' can be used to predict how well a model generalizes out of distribution.
Diverse, but Divisive: LLMs Can Exaggerate Gender Differences in Opinion Related to Harms of Misinformation
Jan 29, 2024The pervasive spread of misinformation and disinformation poses a significant threat to society. Professional fact-checkers play a key role in addressing this threat, but the vast scale of the problem forces them to prioritize their limited resources. This prioritization may consider a range of factors, such as varying risks of harm posed to specific groups of people. In this work, we investigate potential implications of using a large language model (LLM) to facilitate such prioritization. Because fact-checking impacts a wide range of diverse segments of society, it is important that diverse views are represented in the claim prioritization process. This paper examines whether a LLM can reflect the views of various groups when assessing the harms of misinformation, focusing on gender as a primary variable. We pose two central questions: (1) To what extent do prompts with explicit gender references reflect gender differences in opinion in the United States on topics of social relevance? and (2) To what extent do gender-neutral prompts align with gendered viewpoints on those topics? To analyze these questions, we present the TopicMisinfo dataset, containing 160 fact-checked claims from diverse topics, supplemented by nearly 1600 human annotations with subjective perceptions and annotator demographics. Analyzing responses to gender-specific and neutral prompts, we find that GPT 3.5-Turbo reflects empirically observed gender differences in opinion but amplifies the extent of these differences. These findings illuminate AI's complex role in moderating online communication, with implications for fact-checkers, algorithm designers, and the use of crowd-workers as annotators. We also release the TopicMisinfo dataset to support continuing research in the community.
A General Model for Aggregating Annotations Across Simple, Complex, and Multi-Object Annotation Tasks
Dec 20, 2023Human annotations are vital to supervised learning, yet annotators often disagree on the correct label, especially as annotation tasks increase in complexity. A strategy to improve label quality is to ask multiple annotators to label the same item and aggregate their labels. Many aggregation models have been proposed for categorical or numerical annotation tasks, but far less work has considered more complex annotation tasks involving open-ended, multivariate, or structured responses. While a variety of bespoke models have been proposed for specific tasks, our work is the first to introduce aggregation methods that generalize across many diverse complex tasks, including sequence labeling, translation, syntactic parsing, ranking, bounding boxes, and keypoints. This generality is achieved by devising a task-agnostic method to model distances between labels rather than the labels themselves. This article extends our prior work with investigation of three new research questions. First, how do complex annotation properties impact aggregation accuracy? Second, how should a task owner navigate the many modeling choices to maximize aggregation accuracy? Finally, what diagnoses can verify that aggregation models are specified correctly for the given data? To understand how various factors impact accuracy and to inform model selection, we conduct simulation studies and experiments on real, complex datasets. Regarding testing, we introduce unit tests for aggregation models and present a suite of such tests to ensure that a given model is not mis-specified and exhibits expected behavior. Beyond investigating these research questions above, we discuss the foundational concept of annotation complexity, present a new aggregation model as a bridge between traditional models and our own, and contribute a new semi-supervised learning method for complex label aggregation that outperforms prior work.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023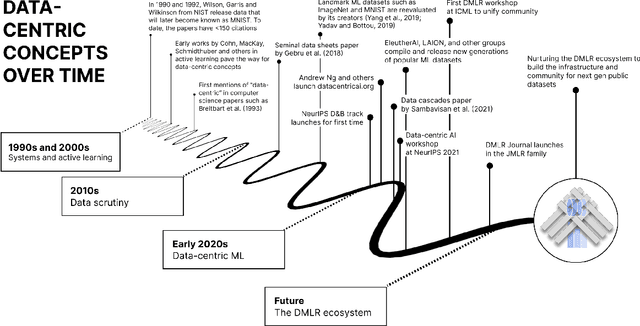
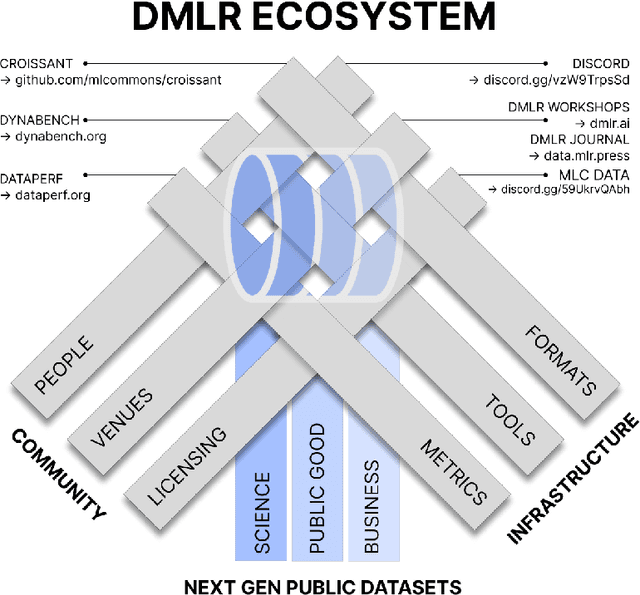
Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Interpretable by Design: Wrapper Boxes Combine Neural Performance with Faithful Explanations
Nov 15, 2023Can we preserve the accuracy of neural models while also providing faithful explanations? We present wrapper boxes, a general approach to generate faithful, example-based explanations for model predictions while maintaining predictive performance. After training a neural model as usual, its learned feature representation is input to a classic, interpretable model to perform the actual prediction. This simple strategy is surprisingly effective, with results largely comparable to those of the original neural model, as shown across three large pre-trained language models, two datasets of varying scale, four classic models, and four evaluation metrics. Moreover, because these classic models are interpretable by design, the subset of training examples that determine classic model predictions can be shown directly to users.
Human-centered NLP Fact-checking: Co-Designing with Fact-checkers using Matchmaking for AI
Aug 14, 2023A key challenge in professional fact-checking is its limited scalability in relation to the magnitude of false information. While many Natural Language Processing (NLP) tools have been proposed to enhance fact-checking efficiency and scalability, both academic research and fact-checking organizations report limited adoption of such tooling due to insufficient alignment with fact-checker practices, values, and needs. To address this gap, we investigate a co-design method, Matchmaking for AI, which facilitates fact-checkers, designers, and NLP researchers to collaboratively discover what fact-checker needs should be addressed by technology and how. Our co-design sessions with 22 professional fact-checkers yielded a set of 11 novel design ideas. They assist in information searching, processing, and writing tasks for efficient and personalized fact-checking; help fact-checkers proactively prepare for future misinformation; monitor their potential biases; and support internal organization collaboration. Our work offers implications for human-centered fact-checking research and practice and AI co-design research.
Designing Closed-Loop Models for Task Allocation
May 31, 2023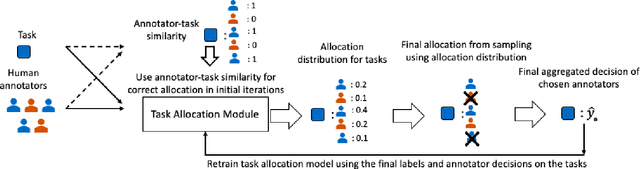
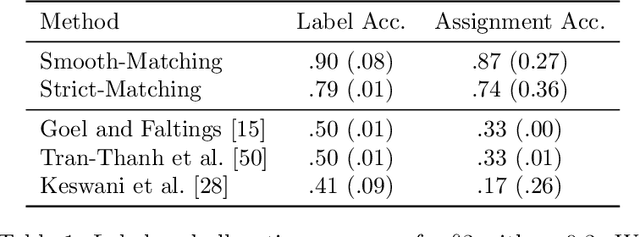
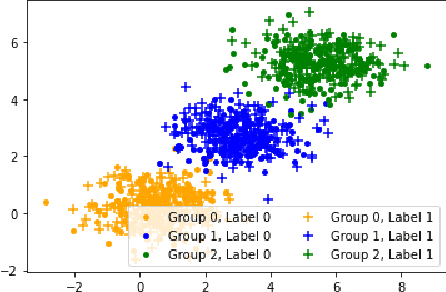

Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Same Same, But Different: Conditional Multi-Task Learning for Demographic-Specific Toxicity Detection
Feb 14, 2023



Algorithmic bias often arises as a result of differential subgroup validity, in which predictive relationships vary across groups. For example, in toxic language detection, comments targeting different demographic groups can vary markedly across groups. In such settings, trained models can be dominated by the relationships that best fit the majority group, leading to disparate performance. We propose framing toxicity detection as multi-task learning (MTL), allowing a model to specialize on the relationships that are relevant to each demographic group while also leveraging shared properties across groups. With toxicity detection, each task corresponds to identifying toxicity against a particular demographic group. However, traditional MTL requires labels for all tasks to be present for every data point. To address this, we propose Conditional MTL (CondMTL), wherein only training examples relevant to the given demographic group are considered by the loss function. This lets us learn group specific representations in each branch which are not cross contaminated by irrelevant labels. Results on synthetic and real data show that using CondMTL improves predictive recall over various baselines in general and for the minority demographic group in particular, while having similar overall accuracy.
Learning Complementary Policies for Human-AI Teams
Feb 06, 2023

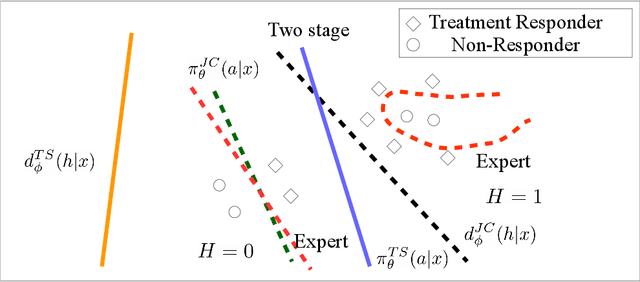
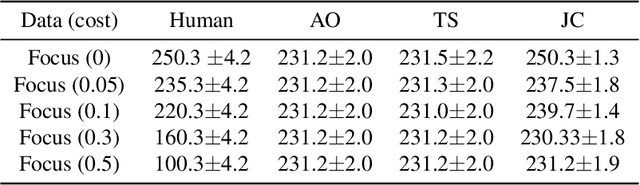
Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.
New Metrics to Encourage Innovation and Diversity in Information Retrieval Approaches
Jan 24, 2023


In evaluation campaigns, participants often explore variations of popular, state-of-the-art baselines as a low-risk strategy to achieve competitive results. While effective, this can lead to local "hill climbing" rather than more radical and innovative departure from standard methods. Moreover, if many participants build on similar baselines, the overall diversity of approaches considered may be limited. In this work, we propose a new class of IR evaluation metrics intended to promote greater diversity of approaches in evaluation campaigns. Whereas traditional IR metrics focus on user experience, our two "innovation" metrics instead reward exploration of more divergent, higher-risk strategies finding relevant documents missed by other systems. Experiments on four TREC collections show that our metrics do change system rankings by rewarding systems that find such rare, relevant documents. This result is further supported by a controlled, synthetic data experiment, and a qualitative analysis. In addition, we show that our metrics achieve higher evaluation stability and discriminative power than the standard metrics we modify. To support reproducibility, we share our source code.