 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthia Sabatelli
VDSC: Enhancing Exploration Timing with Value Discrepancy and State Counts
Mar 26, 2024
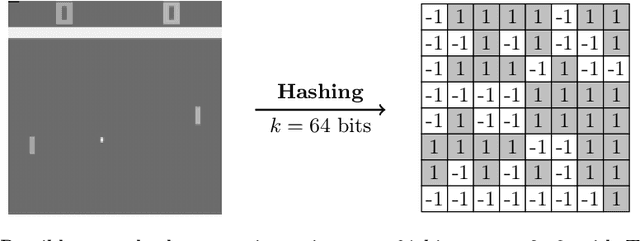
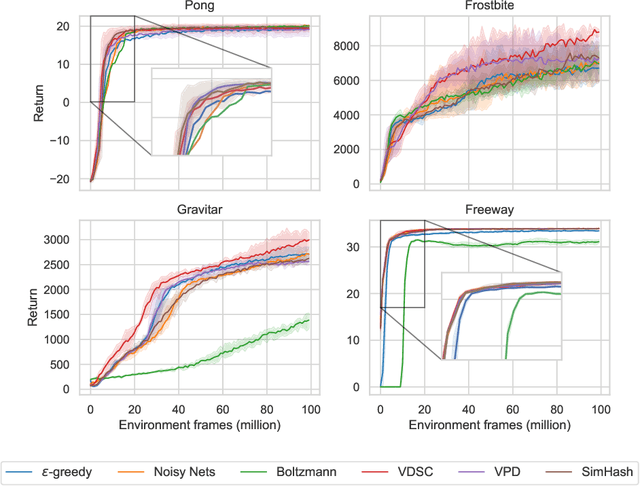
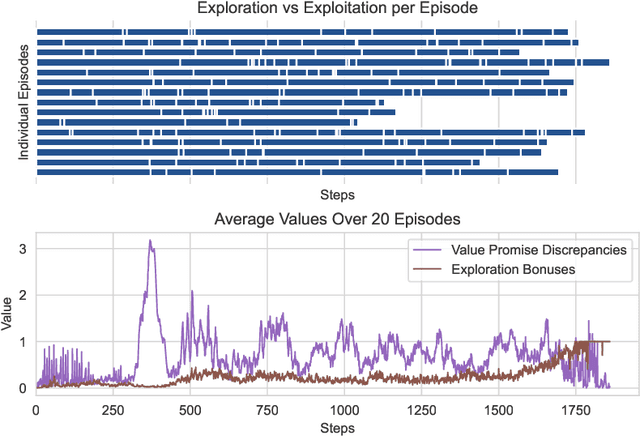
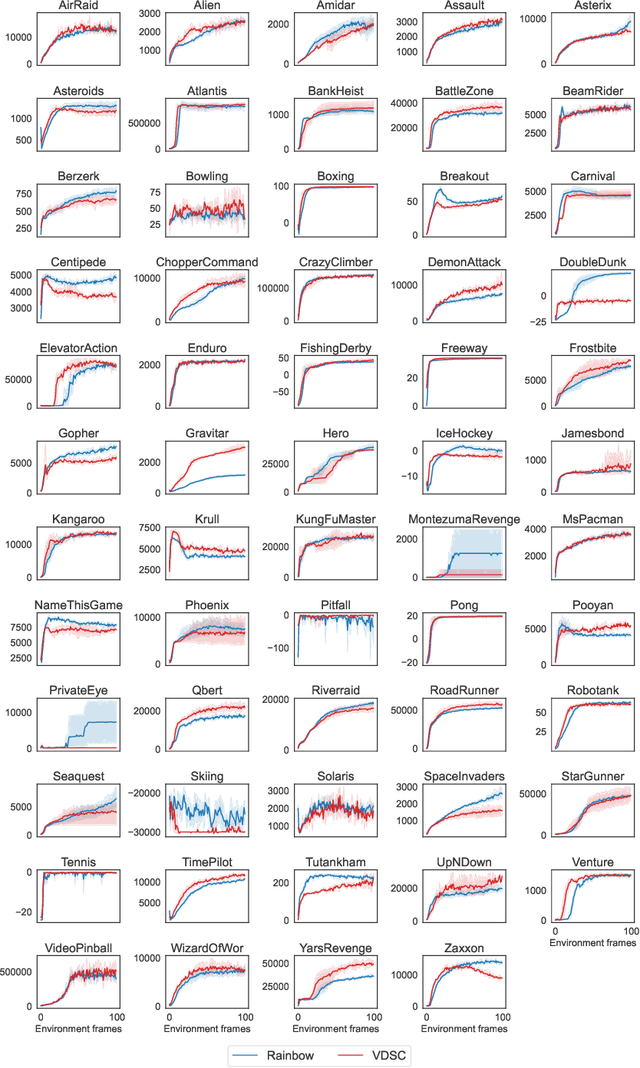
Despite the considerable attention given to the questions of \textit{how much} and \textit{how to} explore in deep reinforcement learning, the investigation into \textit{when} to explore remains relatively less researched. While more sophisticated exploration strategies can excel in specific, often sparse reward environments, existing simpler approaches, such as $\epsilon$-greedy, persist in outperforming them across a broader spectrum of domains. The appeal of these simpler strategies lies in their ease of implementation and generality across a wide range of domains. The downside is that these methods are essentially a blind switching mechanism, which completely disregards the agent's internal state. In this paper, we propose to leverage the agent's internal state to decide \textit{when} to explore, addressing the shortcomings of blind switching mechanisms. We present Value Discrepancy and State Counts through homeostasis (VDSC), a novel approach for efficient exploration timing. Experimental results on the Atari suite demonstrate the superiority of our strategy over traditional methods such as $\epsilon$-greedy and Boltzmann, as well as more sophisticated techniques like Noisy Nets.
Mapping Transformer Leveraged Embeddings for Cross-Lingual Document Representation
Jan 12, 2024
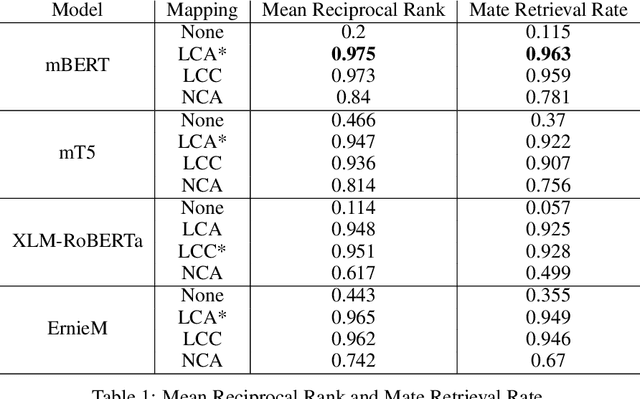
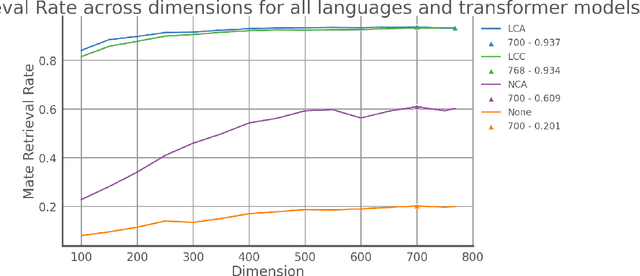
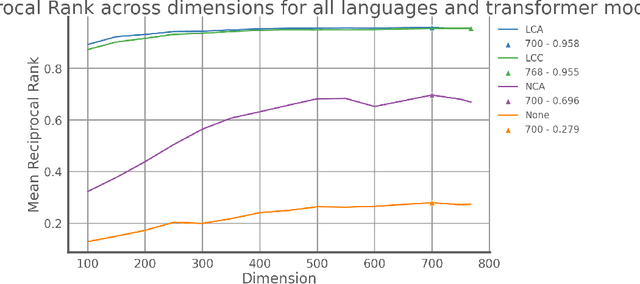
Recommendation systems, for documents, have become tools to find relevant content on the Web. However, these systems have limitations when it comes to recommending documents in languages different from the query language, which means they might overlook resources in non-native languages. This research focuses on representing documents across languages by using Transformer Leveraged Document Representations (TLDRs) that are mapped to a cross-lingual domain. Four multilingual pre-trained transformer models (mBERT, mT5 XLM RoBERTa, ErnieM) were evaluated using three mapping methods across 20 language pairs representing combinations of five selected languages of the European Union. Metrics like Mate Retrieval Rate and Reciprocal Rank were used to measure the effectiveness of mapped TLDRs compared to non-mapped ones. The results highlight the power of cross-lingual representations achieved through pre-trained transformers and mapping approaches suggesting a promising direction for expanding beyond language connections, between two specific languages.
Bridging the Reality Gap of Reinforcement Learning based Traffic Signal Control using Domain Randomization and Meta Learning
Jul 21, 2023

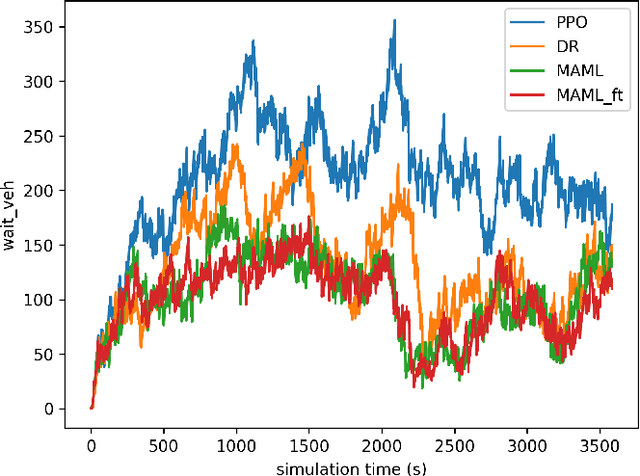

Reinforcement Learning (RL) has been widely explored in Traffic Signal Control (TSC) applications, however, still no such system has been deployed in practice. A key barrier to progress in this area is the reality gap, the discrepancy that results from differences between simulation models and their real-world equivalents. In this paper, we address this challenge by first presenting a comprehensive analysis of potential simulation parameters that contribute to this reality gap. We then also examine two promising strategies that can bridge this gap: Domain Randomization (DR) and Model-Agnostic Meta-Learning (MAML). Both strategies were trained with a traffic simulation model of an intersection. In addition, the model was embedded in LemgoRL, a framework that integrates realistic, safety-critical requirements into the control system. Subsequently, we evaluated the performance of the two methods on a separate model of the same intersection that was developed with a different traffic simulator. In this way, we mimic the reality gap. Our experimental results show that both DR and MAML outperform a state-of-the-art RL algorithm, therefore highlighting their potential to mitigate the reality gap in RLbased TSC systems.
Learning Perceptive Bipedal Locomotion over Irregular Terrain
Apr 14, 2023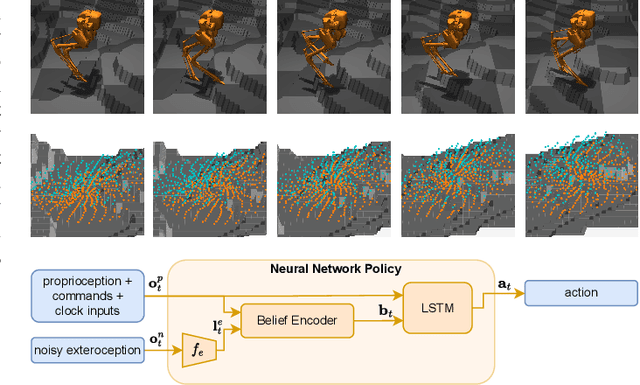

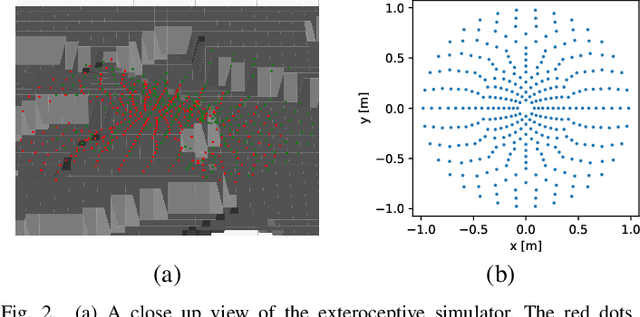
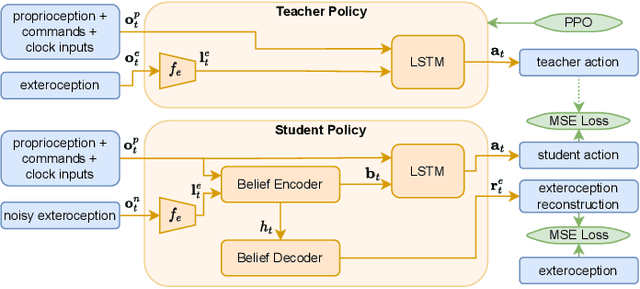
In this paper we propose a novel bipedal locomotion controller that uses noisy exteroception to traverse a wide variety of terrains. Building on the cutting-edge advancements in attention based belief encoding for quadrupedal locomotion, our work extends these methods to the bipedal domain, resulting in a robust and reliable internal belief of the terrain ahead despite noisy sensor inputs. Additionally, we present a reward function that allows the controller to successfully traverse irregular terrain. We compare our method with a proprioceptive baseline and show that our method is able to traverse a wide variety of terrains and greatly outperforms the state-of-the-art in terms of robustness, speed and efficiency.
Factors of Influence of the Overestimation Bias of Q-Learning
Oct 11, 2022

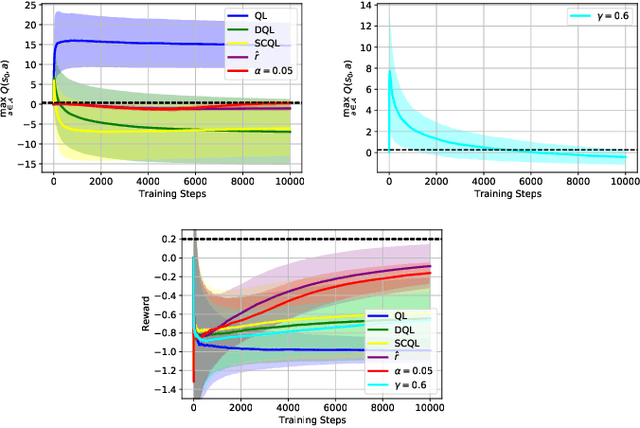
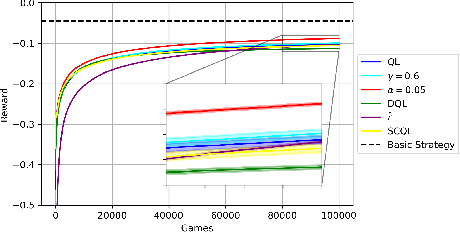
We study whether the learning rate $\alpha$, the discount factor $\gamma$ and the reward signal $r$ have an influence on the overestimation bias of the Q-Learning algorithm. Our preliminary results in environments which are stochastic and that require the use of neural networks as function approximators, show that all three parameters influence overestimation significantly. By carefully tuning $\alpha$ and $\gamma$, and by using an exponential moving average of $r$ in Q-Learning's temporal difference target, we show that the algorithm can learn value estimates that are more accurate than the ones of several other popular model-free methods that have addressed its overestimation bias in the past.
Machine Learning Students Overfit to Overfitting
Sep 07, 2022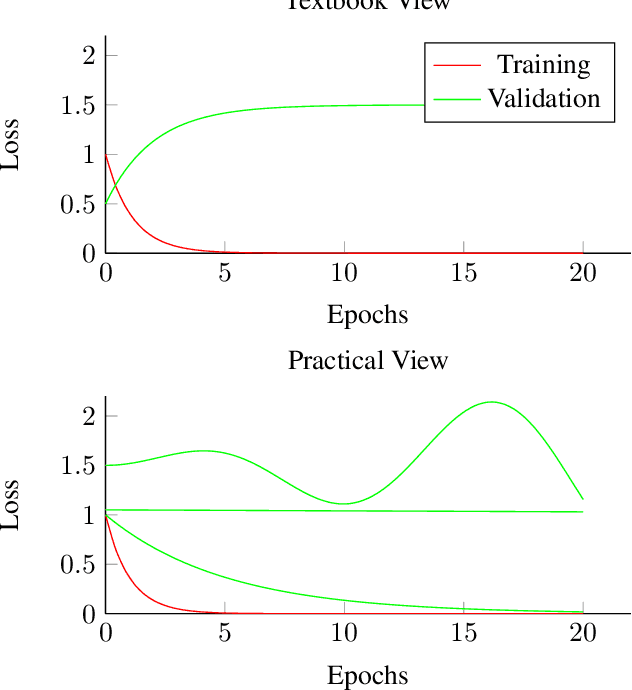


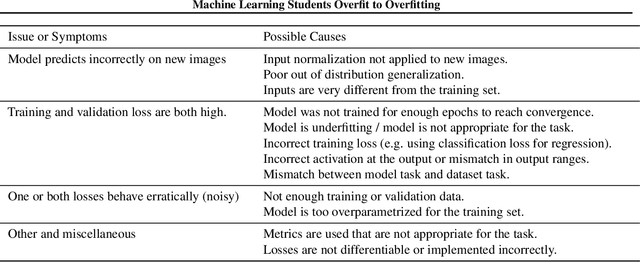
Overfitting and generalization is an important concept in Machine Learning as only models that generalize are interesting for general applications. Yet some students have trouble learning this important concept through lectures and exercises. In this paper we describe common examples of students misunderstanding overfitting, and provide recommendations for possible solutions. We cover student misconceptions about overfitting, about solutions to overfitting, and implementation mistakes that are commonly confused with overfitting issues. We expect that our paper can contribute to improving student understanding and lectures about this important topic.
How Well Do Vision Transformers (VTs) Transfer To The Non-Natural Image Domain? An Empirical Study Involving Art Classification
Aug 09, 2022
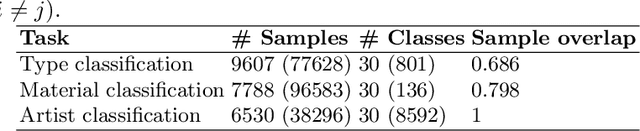
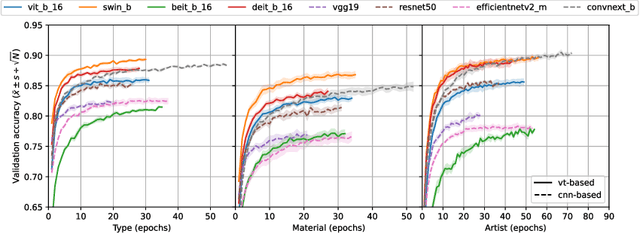
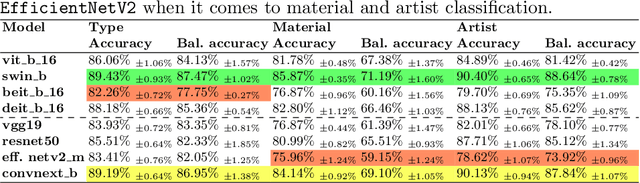
Vision Transformers (VTs) are becoming a valuable alternative to Convolutional Neural Networks (CNNs) when it comes to problems involving high-dimensional and spatially organized inputs such as images. However, their Transfer Learning (TL) properties are not yet well studied, and it is not fully known whether these neural architectures can transfer across different domains as well as CNNs. In this paper we study whether VTs that are pre-trained on the popular ImageNet dataset learn representations that are transferable to the non-natural image domain. To do so we consider three well-studied art classification problems and use them as a surrogate for studying the TL potential of four popular VTs. Their performance is extensively compared against that of four common CNNs across several TL experiments. Our results show that VTs exhibit strong generalization properties and that these networks are more powerful feature extractors than CNNs.
Safe and Psychologically Pleasant Traffic Signal Control with Reinforcement Learning using Action Masking
Jun 21, 2022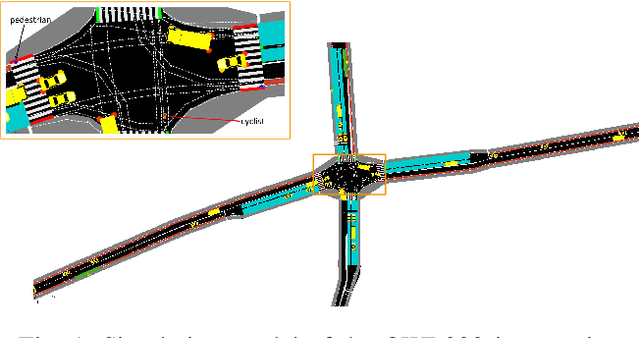
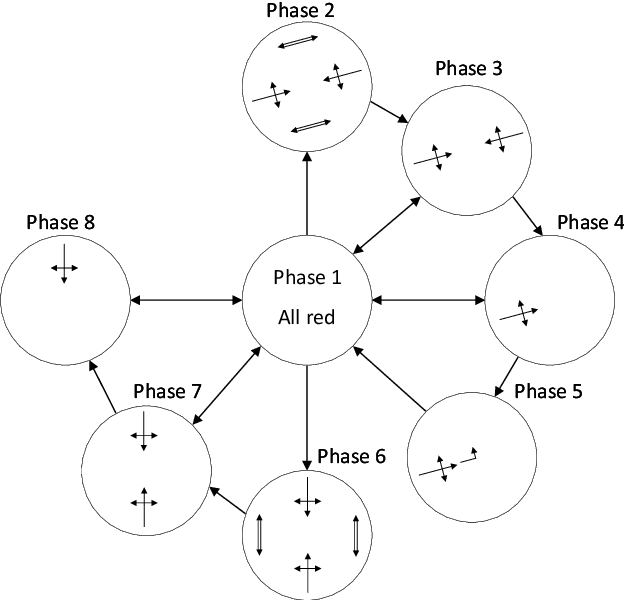
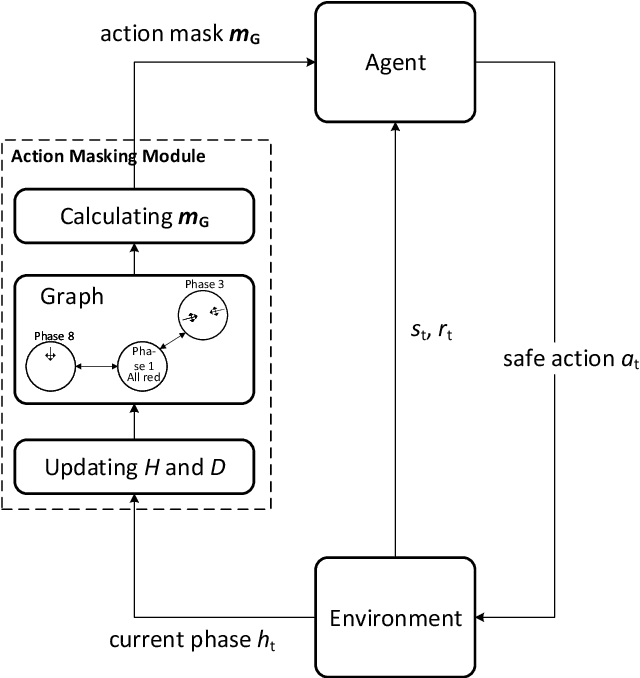
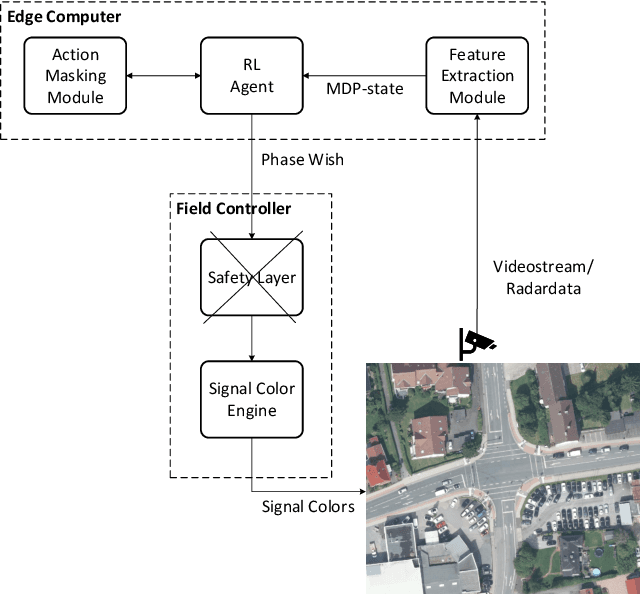
Reinforcement learning (RL) for traffic signal control (TSC) has shown better performance in simulation for controlling the traffic flow of intersections than conventional approaches. However, due to several challenges, no RL-based TSC has been deployed in the field yet. One major challenge for real-world deployment is to ensure that all safety requirements are met at all times during operation. We present an approach to ensure safety in a real-world intersection by using an action space that is safe by design. The action space encompasses traffic phases, which represent the combination of non-conflicting signal colors of the intersection. Additionally, an action masking mechanism makes sure that only appropriate phase transitions are carried out. Another challenge for real-world deployment is to ensure a control behavior that avoids stress for road users. We demonstrate how to achieve this by incorporating domain knowledge through extending the action masking mechanism. We test and verify our approach in a realistic simulation scenario. By ensuring safety and psychologically pleasant control behavior, our approach drives development towards real-world deployment of RL for TSC.
Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning
May 28, 2022
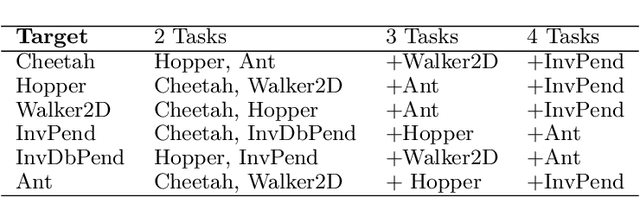
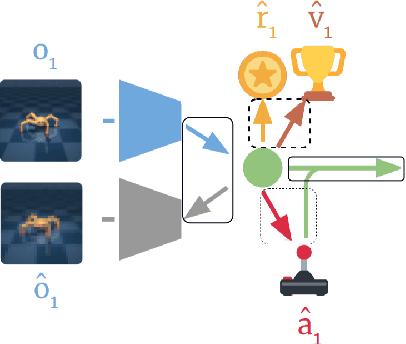
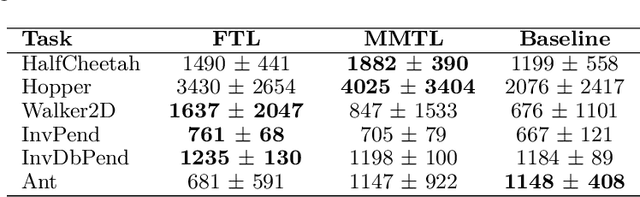
Recent progress in deep model-based reinforcement learning allows agents to be significantly more sample efficient by constructing world models of high-dimensional environments from visual observations, which enables agents to learn complex behaviours in summarized lower-dimensional spaces. Reusing knowledge from relevant previous tasks is another approach for achieving better data-efficiency, which becomes especially more likely when information of multiple previously learned tasks is accessible. We show that the simplified representations of environments resulting from world models provide for promising transfer learning opportunities, by introducing several methods that facilitate world model agents to benefit from multi-source transfer learning. Methods are proposed for autonomously extracting relevant knowledge from both multi-task and multi-agent settings as multi-source origins, resulting in substantial performance improvements compared to learning from scratch. We introduce two additional novel techniques that enable and enhance the proposed approaches respectively: fractional transfer learning and universal feature spaces from a universal autoencoder. We demonstrate that our methods enable transfer learning from different domains with different state, reward, and action spaces by performing extensive and challenging multi-domain experiments on Dreamer, the state-of-the-art world model based algorithm for visual continuous control tasks.
On The Transferability of Deep-Q Networks
Oct 06, 2021
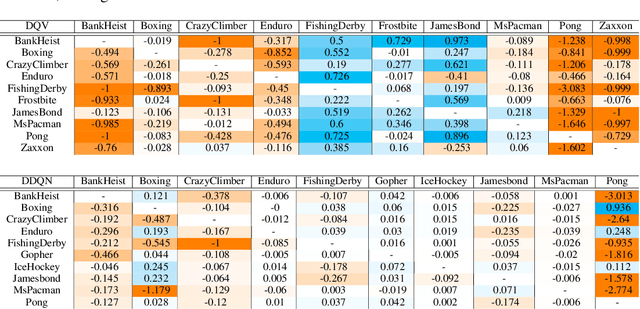

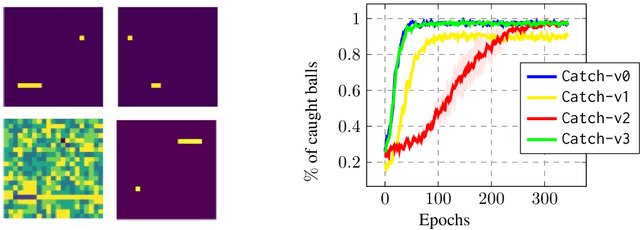
Transfer Learning (TL) is an efficient machine learning paradigm that allows overcoming some of the hurdles that characterize the successful training of deep neural networks, ranging from long training times to the needs of large datasets. While exploiting TL is a well established and successful training practice in Supervised Learning (SL), its applicability in Deep Reinforcement Learning (DRL) is rarer. In this paper, we study the level of transferability of three different variants of Deep-Q Networks on popular DRL benchmarks as well as on a set of novel, carefully designed control tasks. Our results show that transferring neural networks in a DRL context can be particularly challenging and is a process which in most cases results in negative transfer. In the attempt of understanding why Deep-Q Networks transfer so poorly, we gain novel insights into the training dynamics that characterizes this family of algorithms.