 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamidreza Kasaei
Harnessing the Synergy between Pushing, Grasping, and Throwing to Enhance Object Manipulation in Cluttered Scenarios
Feb 25, 2024




In this work, we delve into the intricate synergy among non-prehensile actions like pushing, and prehensile actions such as grasping and throwing, within the domain of robotic manipulation. We introduce an innovative approach to learning these synergies by leveraging model-free deep reinforcement learning. The robot's workflow involves detecting the pose of the target object and the basket at each time step, predicting the optimal push configuration to isolate the target object, determining the appropriate grasp configuration, and inferring the necessary parameters for an accurate throw into the basket. This empowers robots to skillfully reconfigure cluttered scenarios through pushing, creating space for collision-free grasping actions. Simultaneously, we integrate throwing behavior, showcasing how this action significantly extends the robot's operational reach. Ensuring safety, we developed a simulation environment in Gazebo for robot training, applying the learned policy directly to our real robot. Notably, this work represents a pioneering effort to learn the synergy between pushing, grasping, and throwing actions. Extensive experimentation in both simulated and real-robot scenarios substantiates the effectiveness of our approach across diverse settings. Our approach achieves a success rate exceeding 80\% in both simulated and real-world scenarios. A video showcasing our experiments is available online at: https://youtu.be/q1l4BJVDbRw
Language-guided Robot Grasping: CLIP-based Referring Grasp Synthesis in Clutter
Nov 09, 2023
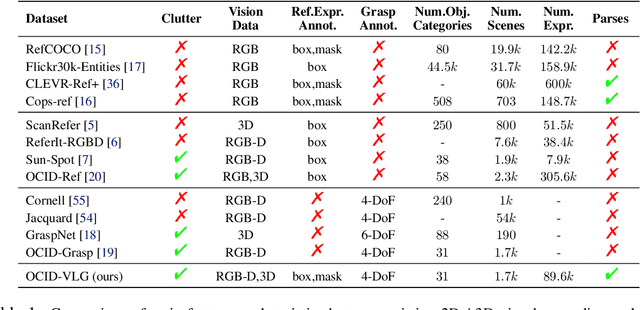
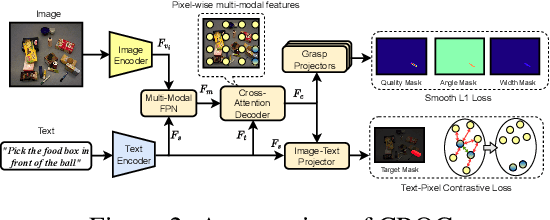
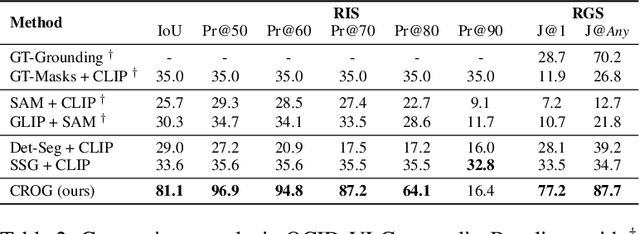
Robots operating in human-centric environments require the integration of visual grounding and grasping capabilities to effectively manipulate objects based on user instructions. This work focuses on the task of referring grasp synthesis, which predicts a grasp pose for an object referred through natural language in cluttered scenes. Existing approaches often employ multi-stage pipelines that first segment the referred object and then propose a suitable grasp, and are evaluated in private datasets or simulators that do not capture the complexity of natural indoor scenes. To address these limitations, we develop a challenging benchmark based on cluttered indoor scenes from OCID dataset, for which we generate referring expressions and connect them with 4-DoF grasp poses. Further, we propose a novel end-to-end model (CROG) that leverages the visual grounding capabilities of CLIP to learn grasp synthesis directly from image-text pairs. Our results show that vanilla integration of CLIP with pretrained models transfers poorly in our challenging benchmark, while CROG achieves significant improvements both in terms of grounding and grasping. Extensive robot experiments in both simulation and hardware demonstrate the effectiveness of our approach in challenging interactive object grasping scenarios that include clutter.
Co-NavGPT: Multi-Robot Cooperative Visual Semantic Navigation using Large Language Models
Oct 11, 2023



In advanced human-robot interaction tasks, visual target navigation is crucial for autonomous robots navigating unknown environments. While numerous approaches have been developed in the past, most are designed for single-robot operations, which often suffer from reduced efficiency and robustness due to environmental complexities. Furthermore, learning policies for multi-robot collaboration are resource-intensive. To address these challenges, we propose Co-NavGPT, an innovative framework that integrates Large Language Models (LLMs) as a global planner for multi-robot cooperative visual target navigation. Co-NavGPT encodes the explored environment data into prompts, enhancing LLMs' scene comprehension. It then assigns exploration frontiers to each robot for efficient target search. Experimental results on Habitat-Matterport 3D (HM3D) demonstrate that Co-NavGPT surpasses existing models in success rates and efficiency without any learning process, demonstrating the vast potential of LLMs in multi-robot collaboration domains. The supplementary video, prompts, and code can be accessed via the following link: \href{https://sites.google.com/view/co-navgpt}{https://sites.google.com/view/co-navgpt}.
Fine-grained 3D object recognition: an approach and experiments
Jun 28, 2023



Three-dimensional (3D) object recognition technology is being used as a core technology in advanced technologies such as autonomous driving of automobiles. There are two sets of approaches for 3D object recognition: (i) hand-crafted approaches like Global Orthographic Object Descriptor (GOOD), and (ii) deep learning-based approaches such as MobileNet and VGG. However, it is needed to know which of these approaches works better in an open-ended domain where the number of known categories increases over time, and the system should learn about new object categories using few training examples. In this paper, we first implemented an offline 3D object recognition system that takes an object view as input and generates category labels as output. In the offline stage, instance-based learning (IBL) is used to form a new category and we use K-fold cross-validation to evaluate the obtained object recognition performance. We then test the proposed approach in an online fashion by integrating the code into a simulated teacher test. As a result, we concluded that the approach using deep learning features is more suitable for open-ended fashion. Moreover, we observed that concatenating the hand-crafted and deep learning features increases the classification accuracy.
Learning Perceptive Bipedal Locomotion over Irregular Terrain
Apr 14, 2023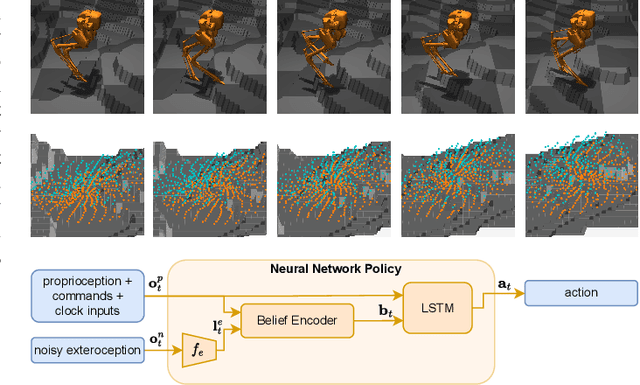

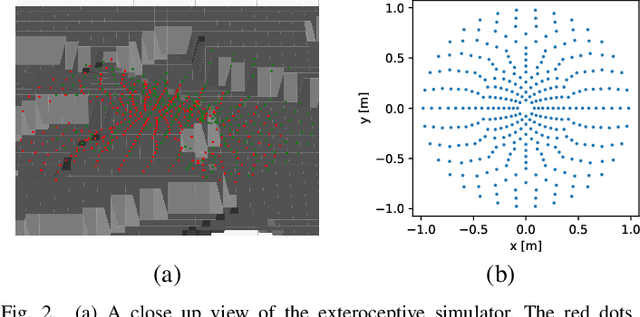
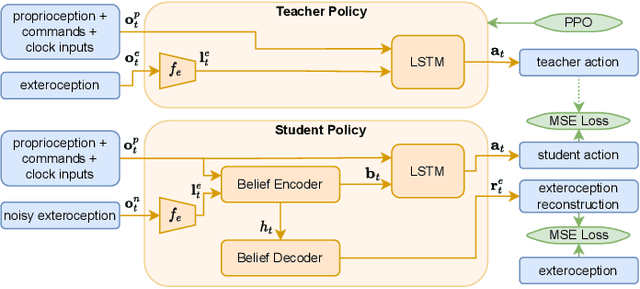
In this paper we propose a novel bipedal locomotion controller that uses noisy exteroception to traverse a wide variety of terrains. Building on the cutting-edge advancements in attention based belief encoding for quadrupedal locomotion, our work extends these methods to the bipedal domain, resulting in a robust and reliable internal belief of the terrain ahead despite noisy sensor inputs. Additionally, we present a reward function that allows the controller to successfully traverse irregular terrain. We compare our method with a proprioceptive baseline and show that our method is able to traverse a wide variety of terrains and greatly outperforms the state-of-the-art in terms of robustness, speed and efficiency.
L3MVN: Leveraging Large Language Models for Visual Target Navigation
Apr 11, 2023



Visual target navigation in unknown environments is a crucial problem in robotics. Despite extensive investigation of classical and learning-based approaches in the past, robots lack common-sense knowledge about household objects and layouts. Prior state-of-the-art approaches to this task rely on learning the priors during the training and typically require significant expensive resources and time for learning. To address this, we propose a new framework for visual target navigation that leverages Large Language Models (LLM) to impart common sense for object searching. Specifically, we introduce two paradigms: (i) zero-shot and (ii) feed-forward approaches that use language to find the relevant frontier from the semantic map as a long-term goal and explore the environment efficiently. Our analysis demonstrates the notable zero-shot generalization and transfer capabilities from the use of language. Experiments on Gibson and Habitat-Matterport 3D (HM3D) demonstrate that the proposed framework significantly outperforms existing map-based methods in terms of success rate and generalization. Ablation analysis also indicates that the common-sense knowledge from the language model leads to more efficient semantic exploration. Finally, we provide a real robot experiment to verify the applicability of our framework in real-world scenarios. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/l3mvn.
Frontier Semantic Exploration for Visual Target Navigation
Apr 11, 2023



This work focuses on the problem of visual target navigation, which is very important for autonomous robots as it is closely related to high-level tasks. To find a special object in unknown environments, classical and learning-based approaches are fundamental components of navigation that have been investigated thoroughly in the past. However, due to the difficulty in the representation of complicated scenes and the learning of the navigation policy, previous methods are still not adequate, especially for large unknown scenes. Hence, we propose a novel framework for visual target navigation using the frontier semantic policy. In this proposed framework, the semantic map and the frontier map are built from the current observation of the environment. Using the features of the maps and object category, deep reinforcement learning enables to learn a frontier semantic policy which can be used to select a frontier cell as a long-term goal to explore the environment efficiently. Experiments on Gibson and Habitat-Matterport 3D (HM3D) demonstrate that the proposed framework significantly outperforms existing map-based methods in terms of success rate and efficiency. Ablation analysis also indicates that the proposed approach learns a more efficient exploration policy based on the frontiers. A demonstration is provided to verify the applicability of applying our model to real-world transfer. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/fsevn.
Controllable Video Generation by Learning the Underlying Dynamical System with Neural ODE
Mar 09, 2023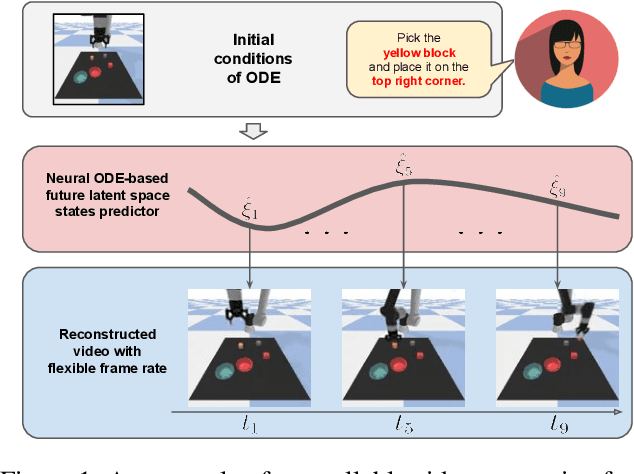
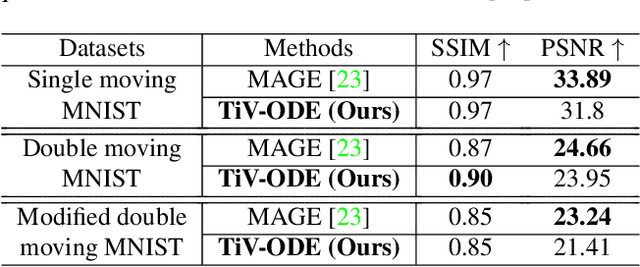
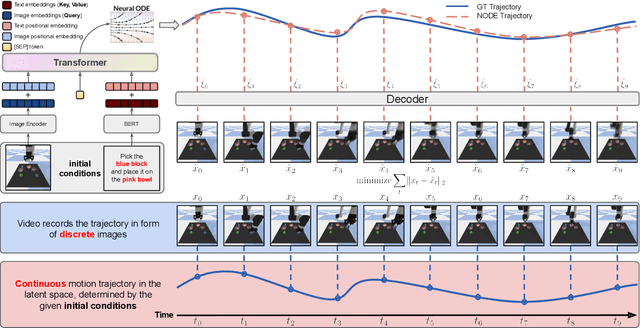
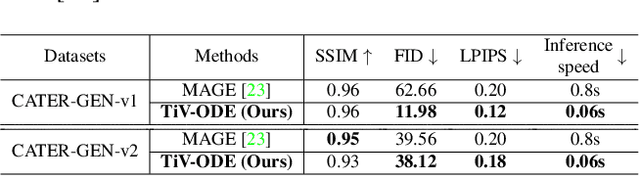
Videos depict the change of complex dynamical systems over time in the form of discrete image sequences. Generating controllable videos by learning the dynamical system is an important yet underexplored topic in the computer vision community. This paper presents a novel framework, TiV-ODE, to generate highly controllable videos from a static image and a text caption. Specifically, our framework leverages the ability of Neural Ordinary Differential Equations~(Neural ODEs) to represent complex dynamical systems as a set of nonlinear ordinary differential equations. The resulting framework is capable of generating videos with both desired dynamics and content. Experiments demonstrate the ability of the proposed method in generating highly controllable and visually consistent videos, and its capability of modeling dynamical systems. Overall, this work is a significant step towards developing advanced controllable video generation models that can handle complex and dynamic scenes.
Instance-wise Grasp Synthesis for Robotic Grasping
Feb 15, 2023



Generating high-quality instance-wise grasp configurations provides critical information of how to grasp specific objects in a multi-object environment and is of high importance for robot manipulation tasks. This work proposed a novel \textbf{S}ingle-\textbf{S}tage \textbf{G}rasp (SSG) synthesis network, which performs high-quality instance-wise grasp synthesis in a single stage: instance mask and grasp configurations are generated for each object simultaneously. Our method outperforms state-of-the-art on robotic grasp prediction based on the OCID-Grasp dataset, and performs competitively on the JACQUARD dataset. The benchmarking results showed significant improvements compared to the baseline on the accuracy of generated grasp configurations. The performance of the proposed method has been validated through both extensive simulations and real robot experiments for three tasks including single object pick-and-place, grasp synthesis in cluttered environments and table cleaning task.
GraspCaps: Capsule Networks Are All You Need for Grasping Familiar Objects
Oct 07, 2022



As robots become more accessible outside of industrial settings, the need for reliable object grasping and manipulation grows significantly. In such dynamic environments it is expected that the robot is capable of reliably grasping and manipulating novel objects in different situations. In this work we present GraspCaps: a novel architecture based on Capsule Networks for generating per-point grasp configurations for familiar objects. In our work, the activation vector of each capsule in the deepest capsule layer corresponds to one specific class of object. This way, the network is able to extract a rich feature vector of the objects present in the point cloud input, which is then used for generating per-point grasp vectors. This approach should allow the network to learn specific grasping strategies for each of the different object categories. Along with GraspCaps we present a method for generating a large object grasping dataset using simulated annealing. The obtained dataset is then used to train the GraspCaps network. We performed an extensive set of experiments to assess the performance of the proposed approach regarding familiar object recognition accuracy and grasp success rate on challenging real and simulated scenarios.