 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax Vladymyrov
Linear Transformers are Versatile In-Context Learners
Feb 21, 2024
Recent research has demonstrated that transformers, particularly linear attention models, implicitly execute gradient-descent-like algorithms on data provided in-context during their forward inference step. However, their capability in handling more complex problems remains unexplored. In this paper, we prove that any linear transformer maintains an implicit linear model and can be interpreted as performing a variant of preconditioned gradient descent. We also investigate the use of linear transformers in a challenging scenario where the training data is corrupted with different levels of noise. Remarkably, we demonstrate that for this problem linear transformers discover an intricate and highly effective optimization algorithm, surpassing or matching in performance many reasonable baselines. We reverse-engineer this algorithm and show that it is a novel approach incorporating momentum and adaptive rescaling based on noise levels. Our findings show that even linear transformers possess the surprising ability to discover sophisticated optimization strategies.
Uncovering mesa-optimization algorithms in Transformers
Sep 11, 2023Transformers have become the dominant model in deep learning, but the reason for their superior performance is poorly understood. Here, we hypothesize that the strong performance of Transformers stems from an architectural bias towards mesa-optimization, a learned process running within the forward pass of a model consisting of the following two steps: (i) the construction of an internal learning objective, and (ii) its corresponding solution found through optimization. To test this hypothesis, we reverse-engineer a series of autoregressive Transformers trained on simple sequence modeling tasks, uncovering underlying gradient-based mesa-optimization algorithms driving the generation of predictions. Moreover, we show that the learned forward-pass optimization algorithm can be immediately repurposed to solve supervised few-shot tasks, suggesting that mesa-optimization might underlie the in-context learning capabilities of large language models. Finally, we propose a novel self-attention layer, the mesa-layer, that explicitly and efficiently solves optimization problems specified in context. We find that this layer can lead to improved performance in synthetic and preliminary language modeling experiments, adding weight to our hypothesis that mesa-optimization is an important operation hidden within the weights of trained Transformers.
Continual Few-Shot Learning Using HyperTransformers
Jan 12, 2023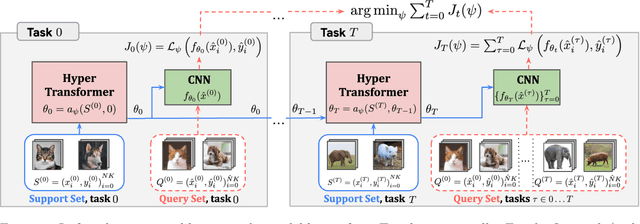
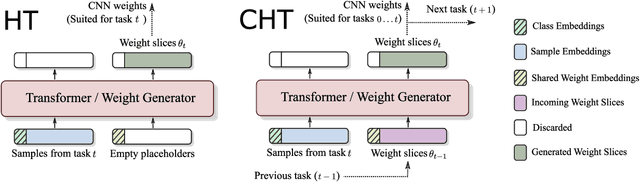
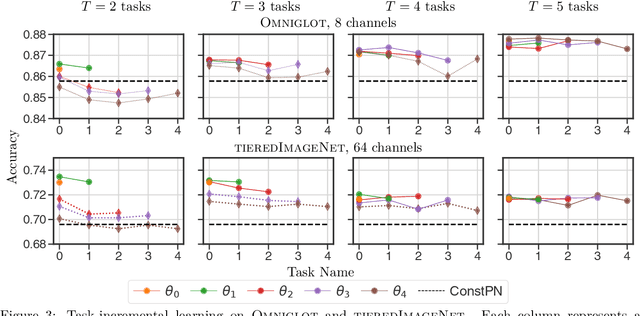
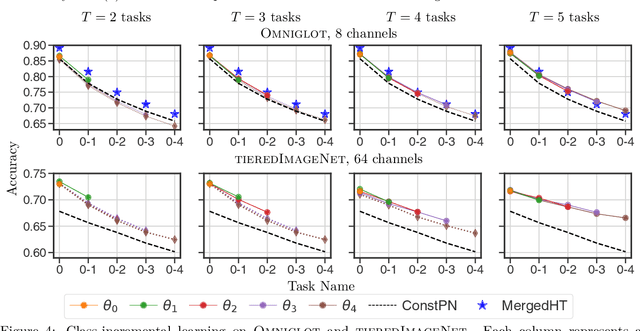
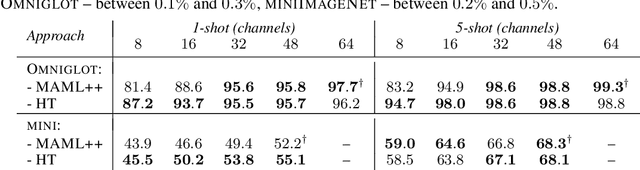
We focus on the problem of learning without forgetting from multiple tasks arriving sequentially, where each task is defined using a few-shot episode of novel or already seen classes. We approach this problem using the recently published HyperTransformer (HT), a Transformer-based hypernetwork that generates specialized task-specific CNN weights directly from the support set. In order to learn from a continual sequence of tasks, we propose to recursively re-use the generated weights as input to the HT for the next task. This way, the generated CNN weights themselves act as a representation of previously learned tasks, and the HT is trained to update these weights so that the new task can be learned without forgetting past tasks. This approach is different from most continual learning algorithms that typically rely on using replay buffers, weight regularization or task-dependent architectural changes. We demonstrate that our proposed Continual HyperTransformer method equipped with a prototypical loss is capable of learning and retaining knowledge about past tasks for a variety of scenarios, including learning from mini-batches, and task-incremental and class-incremental learning scenarios.
Training trajectories, mini-batch losses and the curious role of the learning rate
Jan 05, 2023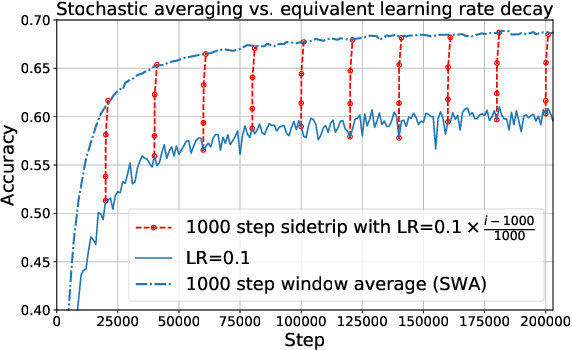

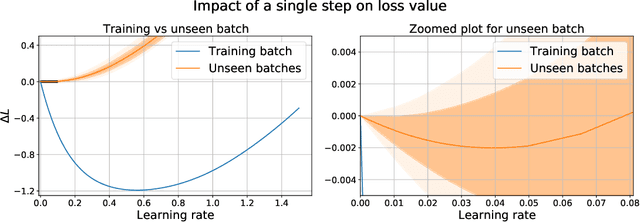
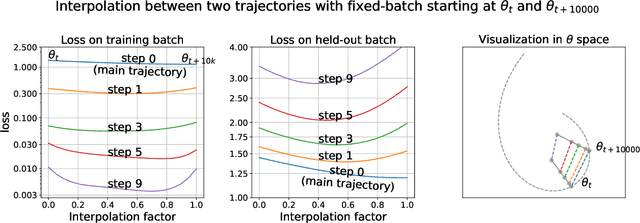
Stochastic gradient descent plays a fundamental role in nearly all applications of deep learning. However its efficiency and remarkable ability to converge to global minimum remains shrouded in mystery. The loss function defined on a large network with large amount of data is known to be non-convex. However, relatively little has been explored about the behavior of loss function on individual batches. Remarkably, we show that for ResNet the loss for any fixed mini-batch when measured along side SGD trajectory appears to be accurately modeled by a quadratic function. In particular, a very low loss value can be reached in just one step of gradient descent with large enough learning rate. We propose a simple model and a geometric interpretation that allows to analyze the relationship between the gradients of stochastic mini-batches and the full batch and how the learning rate affects the relationship between improvement on individual and full batch. Our analysis allows us to discover the equivalency between iterate aggregates and specific learning rate schedules. In particular, for Exponential Moving Average (EMA) and Stochastic Weight Averaging we show that our proposed model matches the observed training trajectories on ImageNet. Our theoretical model predicts that an even simpler averaging technique, averaging just two points a few steps apart, also significantly improves accuracy compared to the baseline. We validated our findings on ImageNet and other datasets using ResNet architecture.
Transformers learn in-context by gradient descent
Dec 15, 2022
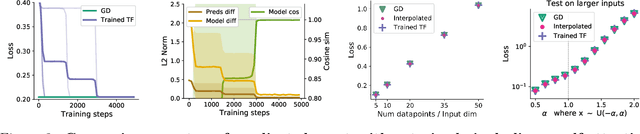
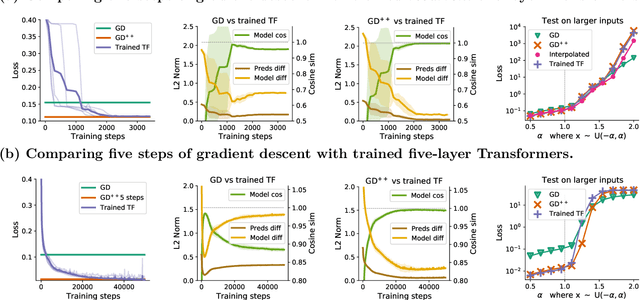
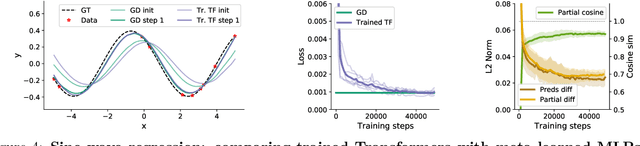
Transformers have become the state-of-the-art neural network architecture across numerous domains of machine learning. This is partly due to their celebrated ability to transfer and to learn in-context based on few examples. Nevertheless, the mechanisms by which Transformers become in-context learners are not well understood and remain mostly an intuition. Here, we argue that training Transformers on auto-regressive tasks can be closely related to well-known gradient-based meta-learning formulations. We start by providing a simple weight construction that shows the equivalence of data transformations induced by 1) a single linear self-attention layer and by 2) gradient-descent (GD) on a regression loss. Motivated by that construction, we show empirically that when training self-attention-only Transformers on simple regression tasks either the models learned by GD and Transformers show great similarity or, remarkably, the weights found by optimization match the construction. Thus we show how trained Transformers implement gradient descent in their forward pass. This allows us, at least in the domain of regression problems, to mechanistically understand the inner workings of optimized Transformers that learn in-context. Furthermore, we identify how Transformers surpass plain gradient descent by an iterative curvature correction and learn linear models on deep data representations to solve non-linear regression tasks. Finally, we discuss intriguing parallels to a mechanism identified to be crucial for in-context learning termed induction-head (Olsson et al., 2022) and show how it could be understood as a specific case of in-context learning by gradient descent learning within Transformers.
Decentralized Learning with Multi-Headed Distillation
Nov 28, 2022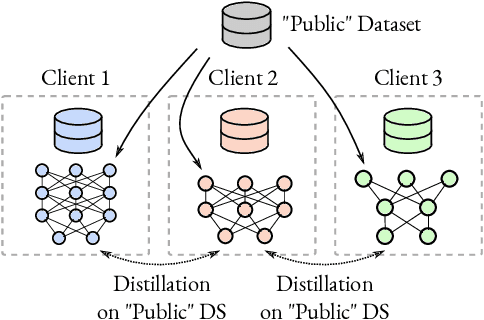

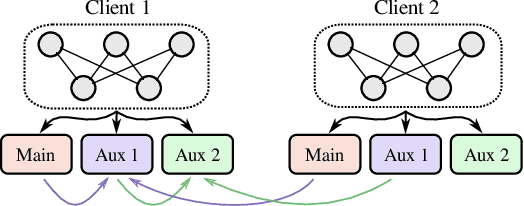
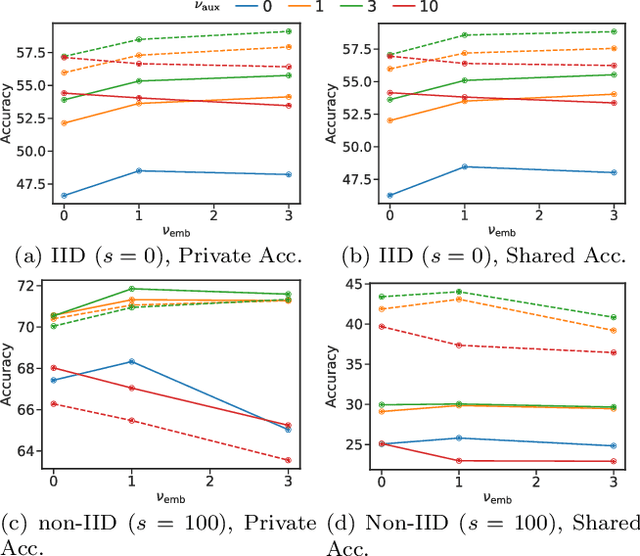
Decentralized learning with private data is a central problem in machine learning. We propose a novel distillation-based decentralized learning technique that allows multiple agents with private non-iid data to learn from each other, without having to share their data, weights or weight updates. Our approach is communication efficient, utilizes an unlabeled public dataset and uses multiple auxiliary heads for each client, greatly improving training efficiency in the case of heterogeneous data. This approach allows individual models to preserve and enhance performance on their private tasks while also dramatically improving their performance on the global aggregated data distribution. We study the effects of data and model architecture heterogeneity and the impact of the underlying communication graph topology on learning efficiency and show that our agents can significantly improve their performance compared to learning in isolation.
Fine-tuning Image Transformers using Learnable Memory
Mar 30, 2022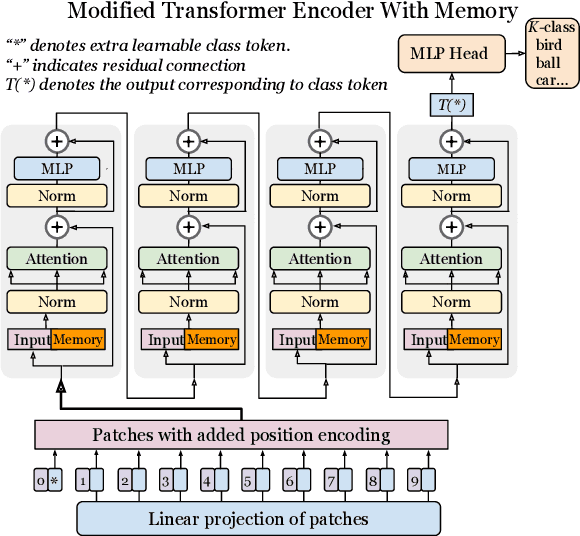
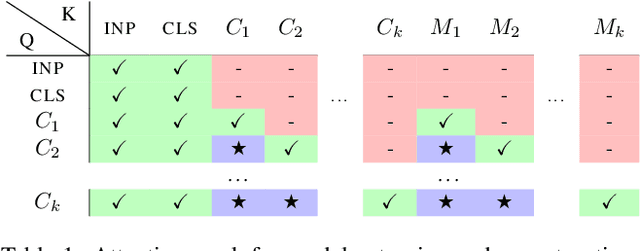
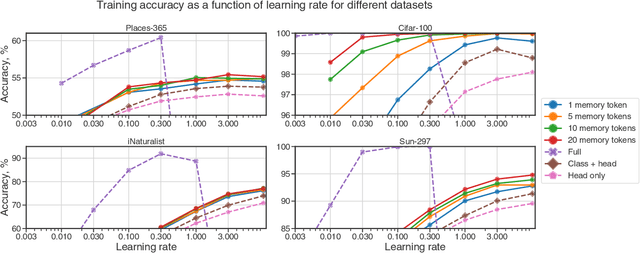
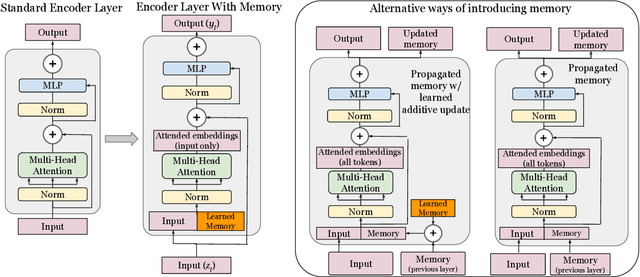
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
Jan 15, 2022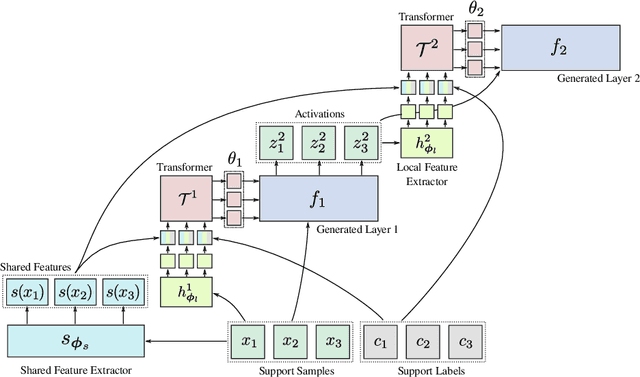
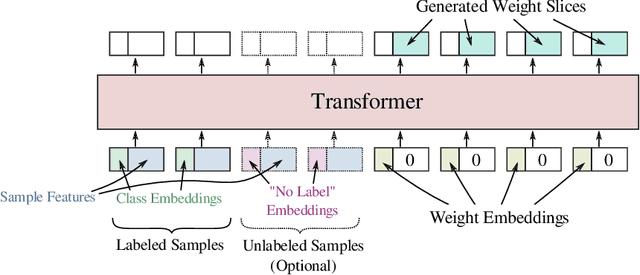
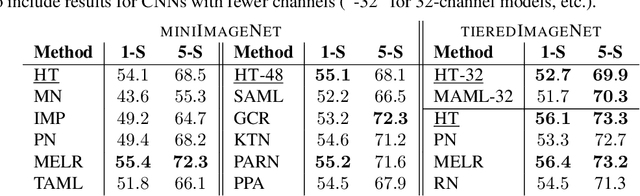
In this work we propose a HyperTransformer, a transformer-based model for few-shot learning that generates weights of a convolutional neural network (CNN) directly from support samples. Since the dependence of a small generated CNN model on a specific task is encoded by a high-capacity transformer model, we effectively decouple the complexity of the large task space from the complexity of individual tasks. Our method is particularly effective for small target CNN architectures where learning a fixed universal task-independent embedding is not optimal and better performance is attained when the information about the task can modulate all model parameters. For larger models we discover that generating the last layer alone allows us to produce competitive or better results than those obtained with state-of-the-art methods while being end-to-end differentiable. Finally, we extend our approach to a semi-supervised regime utilizing unlabeled samples in the support set and further improving few-shot performance.
GradMax: Growing Neural Networks using Gradient Information
Jan 13, 2022

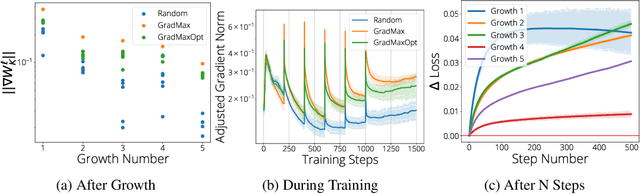

The architecture and the parameters of neural networks are often optimized independently, which requires costly retraining of the parameters whenever the architecture is modified. In this work we instead focus on growing the architecture without requiring costly retraining. We present a method that adds new neurons during training without impacting what is already learned, while improving the training dynamics. We achieve the latter by maximizing the gradients of the new weights and find the optimal initialization efficiently by means of the singular value decomposition (SVD). We call this technique Gradient Maximizing Growth (GradMax) and demonstrate its effectiveness in variety of vision tasks and architectures.
Meta-Learning Bidirectional Update Rules
Apr 10, 2021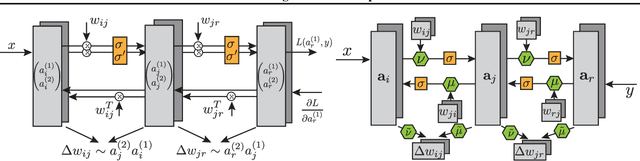
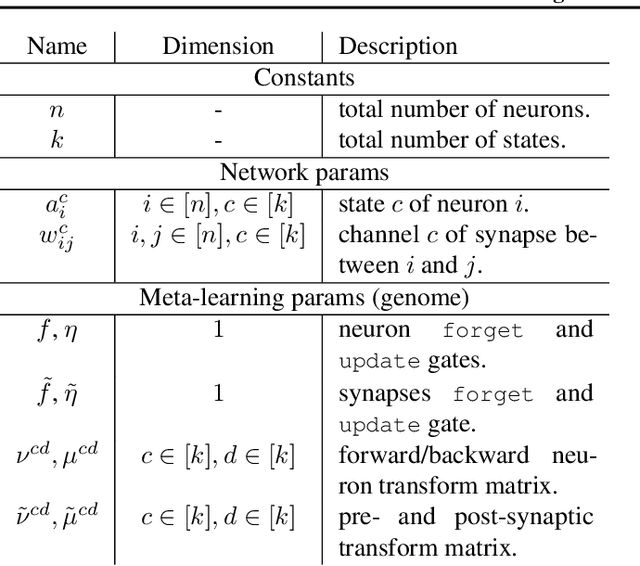
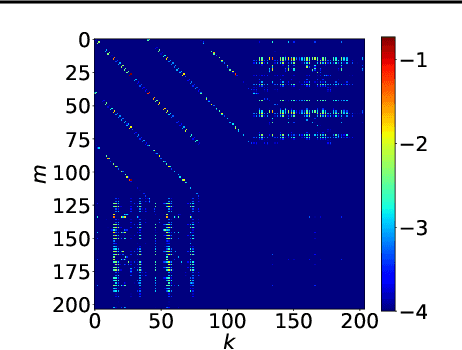
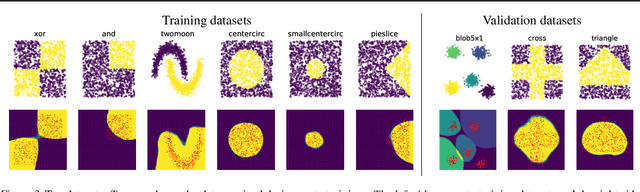
In this paper, we introduce a new type of generalized neural network where neurons and synapses maintain multiple states. We show that classical gradient-based backpropagation in neural networks can be seen as a special case of a two-state network where one state is used for activations and another for gradients, with update rules derived from the chain rule. In our generalized framework, networks have neither explicit notion of nor ever receive gradients. The synapses and neurons are updated using a bidirectional Hebb-style update rule parameterized by a shared low-dimensional "genome". We show that such genomes can be meta-learned from scratch, using either conventional optimization techniques, or evolutionary strategies, such as CMA-ES. Resulting update rules generalize to unseen tasks and train faster than gradient descent based optimizers for several standard computer vision and synthetic tasks.