 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng Wei
Determined Multi-Label Learning via Similarity-Based Prompt
Mar 25, 2024
In multi-label classification, each training instance is associated with multiple class labels simultaneously. Unfortunately, collecting the fully precise class labels for each training instance is time- and labor-consuming for real-world applications. To alleviate this problem, a novel labeling setting termed \textit{Determined Multi-Label Learning} (DMLL) is proposed, aiming to effectively alleviate the labeling cost inherent in multi-label tasks. In this novel labeling setting, each training instance is associated with a \textit{determined label} (either "Yes" or "No"), which indicates whether the training instance contains the provided class label. The provided class label is randomly and uniformly selected from the whole candidate labels set. Besides, each training instance only need to be determined once, which significantly reduce the annotation cost of the labeling task for multi-label datasets. In this paper, we theoretically derive an risk-consistent estimator to learn a multi-label classifier from these determined-labeled training data. Additionally, we introduce a similarity-based prompt learning method for the first time, which minimizes the risk-consistent loss of large-scale pre-trained models to learn a supplemental prompt with richer semantic information. Extensive experimental validation underscores the efficacy of our approach, demonstrating superior performance compared to existing state-of-the-art methods.
Learning from Reduced Labels for Long-Tailed Data
Mar 25, 2024Long-tailed data is prevalent in real-world classification tasks and heavily relies on supervised information, which makes the annotation process exceptionally labor-intensive and time-consuming. Unfortunately, despite being a common approach to mitigate labeling costs, existing weakly supervised learning methods struggle to adequately preserve supervised information for tail samples, resulting in a decline in accuracy for the tail classes. To alleviate this problem, we introduce a novel weakly supervised labeling setting called Reduced Label. The proposed labeling setting not only avoids the decline of supervised information for the tail samples, but also decreases the labeling costs associated with long-tailed data. Additionally, we propose an straightforward and highly efficient unbiased framework with strong theoretical guarantees to learn from these Reduced Labels. Extensive experiments conducted on benchmark datasets including ImageNet validate the effectiveness of our approach, surpassing the performance of state-of-the-art weakly supervised methods.
Large Model driven Radiology Report Generation with Clinical Quality Reinforcement Learning
Mar 11, 2024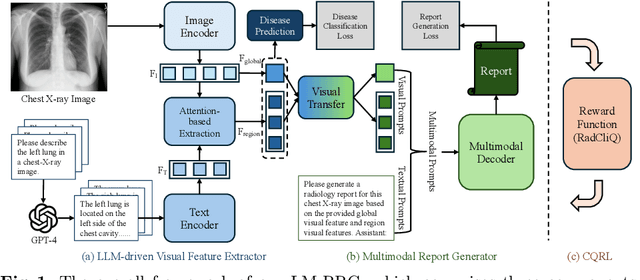
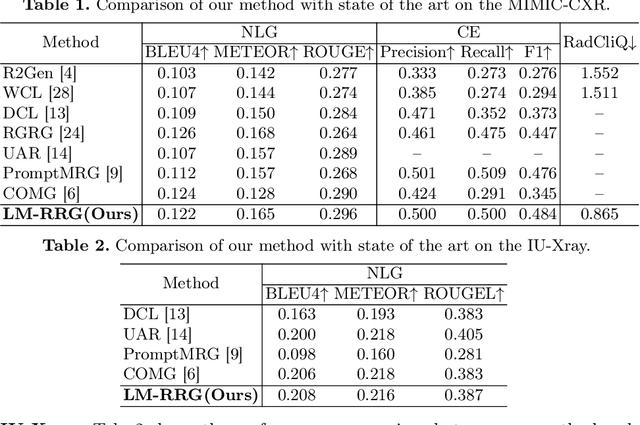

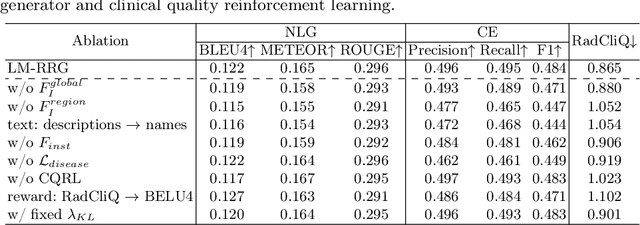
Radiology report generation (RRG) has attracted significant attention due to its potential to reduce the workload of radiologists. Current RRG approaches are still unsatisfactory against clinical standards. This paper introduces a novel RRG method, \textbf{LM-RRG}, that integrates large models (LMs) with clinical quality reinforcement learning to generate accurate and comprehensive chest X-ray radiology reports. Our method first designs a large language model driven feature extractor to analyze and interpret different regions of the chest X-ray image, emphasizing specific regions with medical significance. Next, based on the large model's decoder, we develop a multimodal report generator that leverages multimodal prompts from visual features and textual instruction to produce the radiology report in an auto-regressive way. Finally, to better reflect the clinical significant and insignificant errors that radiologists would normally assign in the report, we introduce a novel clinical quality reinforcement learning strategy. It utilizes the radiology report clinical quality (RadCliQ) metric as a reward function in the learning process. Extensive experiments on the MIMIC-CXR and IU-Xray datasets demonstrate the superiority of our method over the state of the art.
OV-PARTS: Towards Open-Vocabulary Part Segmentation
Oct 08, 2023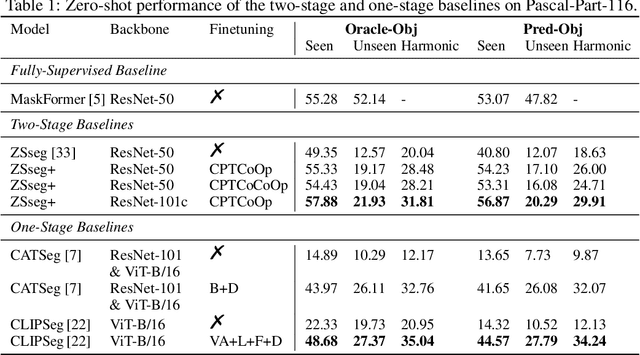
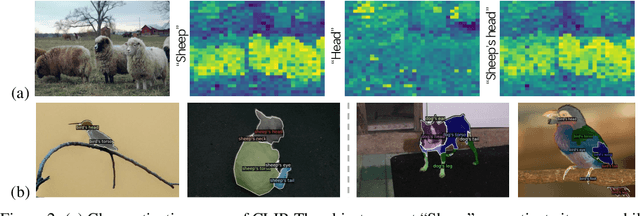
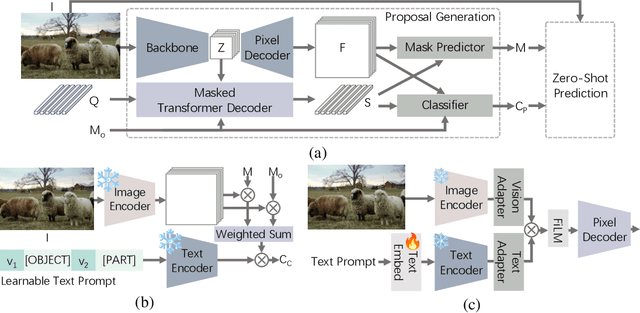
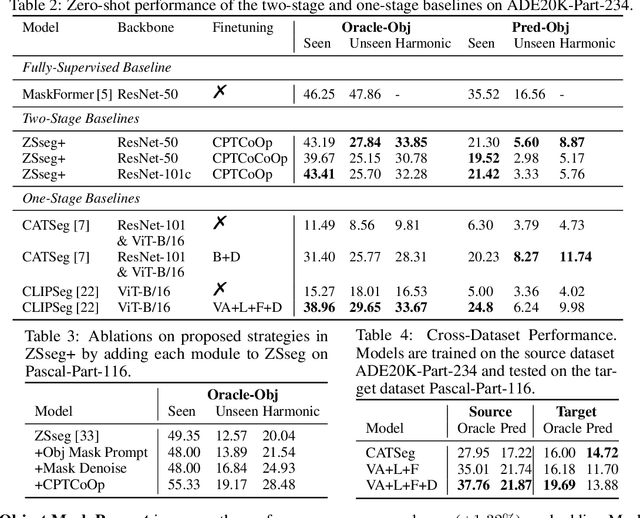
Segmenting and recognizing diverse object parts is a crucial ability in applications spanning various computer vision and robotic tasks. While significant progress has been made in object-level Open-Vocabulary Semantic Segmentation (OVSS), i.e., segmenting objects with arbitrary text, the corresponding part-level research poses additional challenges. Firstly, part segmentation inherently involves intricate boundaries, while limited annotated data compounds the challenge. Secondly, part segmentation introduces an open granularity challenge due to the diverse and often ambiguous definitions of parts in the open world. Furthermore, the large-scale vision and language models, which play a key role in the open vocabulary setting, struggle to recognize parts as effectively as objects. To comprehensively investigate and tackle these challenges, we propose an Open-Vocabulary Part Segmentation (OV-PARTS) benchmark. OV-PARTS includes refined versions of two publicly available datasets: Pascal-Part-116 and ADE20K-Part-234. And it covers three specific tasks: Generalized Zero-Shot Part Segmentation, Cross-Dataset Part Segmentation, and Few-Shot Part Segmentation, providing insights into analogical reasoning, open granularity and few-shot adapting abilities of models. Moreover, we analyze and adapt two prevailing paradigms of existing object-level OVSS methods for OV-PARTS. Extensive experimental analysis is conducted to inspire future research in leveraging foundational models for OV-PARTS. The code and dataset are available at https://github.com/OpenRobotLab/OV_PARTS.
Understanding Masked Autoencoders From a Local Contrastive Perspective
Oct 03, 2023
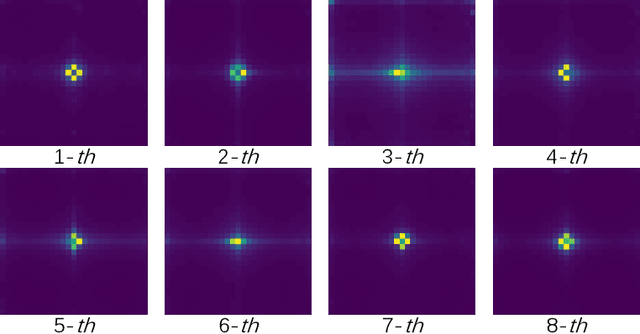
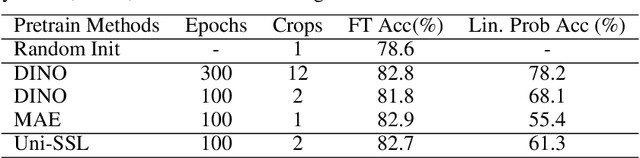
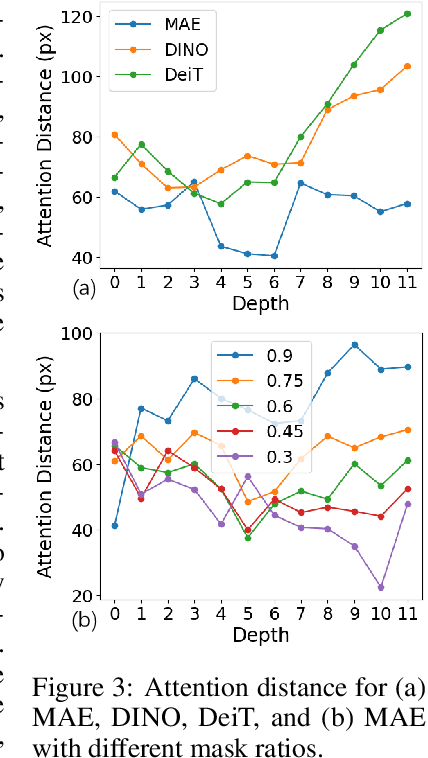
Masked AutoEncoder(MAE) has revolutionized the field of self-supervised learning with its simple yet effective masking and reconstruction strategies. However, despite achieving state-of-the-art performance across various downstream vision tasks, the underlying mechanisms that drive MAE's efficacy are less well-explored compared to the canonical contrastive learning paradigm. In this paper, we explore a new perspective to explain what truly contributes to the "rich hidden representations inside the MAE". Firstly, concerning MAE's generative pretraining pathway, with a unique encoder-decoder architecture to reconstruct images from aggressive masking, we conduct an in-depth analysis of the decoder's behaviors. We empirically find that MAE's decoder mainly learns local features with a limited receptive field, adhering to the well-known Locality Principle. Building upon this locality assumption, we propose a theoretical framework that reformulates the reconstruction-based MAE into a local region-level contrastive learning form for improved understanding. Furthermore, to substantiate the local contrastive nature of MAE, we introduce a Siamese architecture that combines the essence of MAE and contrastive learning without masking and explicit decoder, which sheds light on a unified and more flexible self-supervised learning framework.
SegMatch: A semi-supervised learning method for surgical instrument segmentation
Aug 09, 2023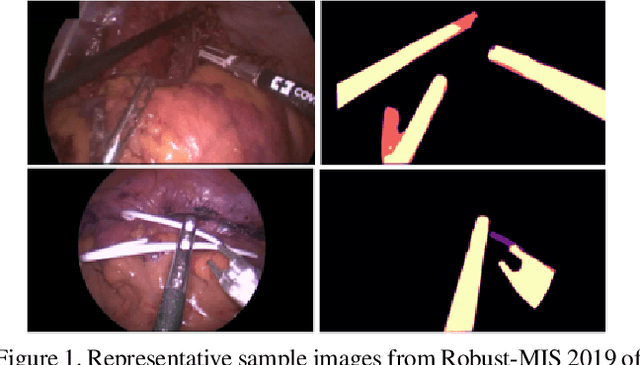
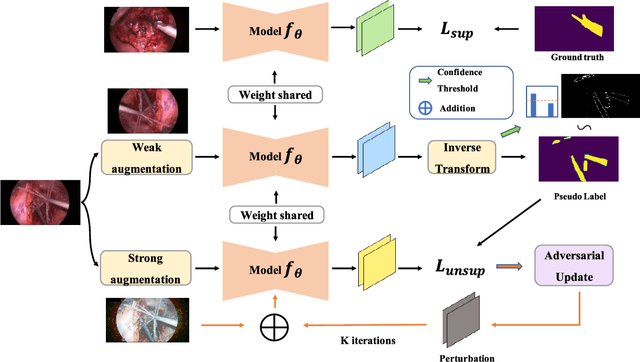
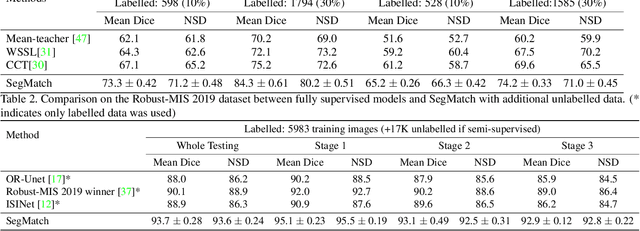
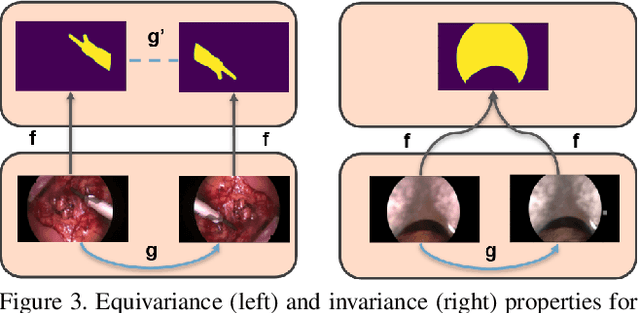
Surgical instrument segmentation is recognised as a key enabler to provide advanced surgical assistance and improve computer assisted interventions. In this work, we propose SegMatch, a semi supervised learning method to reduce the need for expensive annotation for laparoscopic and robotic surgical images. SegMatch builds on FixMatch, a widespread semi supervised classification pipeline combining consistency regularization and pseudo labelling, and adapts it for the purpose of segmentation. In our proposed SegMatch, the unlabelled images are weakly augmented and fed into the segmentation model to generate a pseudo-label to enforce the unsupervised loss against the output of the model for the adversarial augmented image on the pixels with a high confidence score. Our adaptation for segmentation tasks includes carefully considering the equivariance and invariance properties of the augmentation functions we rely on. To increase the relevance of our augmentations, we depart from using only handcrafted augmentations and introduce a trainable adversarial augmentation strategy. Our algorithm was evaluated on the MICCAI Instrument Segmentation Challenge datasets Robust-MIS 2019 and EndoVis 2017. Our results demonstrate that adding unlabelled data for training purposes allows us to surpass the performance of fully supervised approaches which are limited by the availability of training data in these challenges. SegMatch also outperforms a range of state-of-the-art semi-supervised learning semantic segmentation models in different labelled to unlabelled data ratios.
Pick the Best Pre-trained Model: Towards Transferability Estimation for Medical Image Segmentation
Jul 22, 2023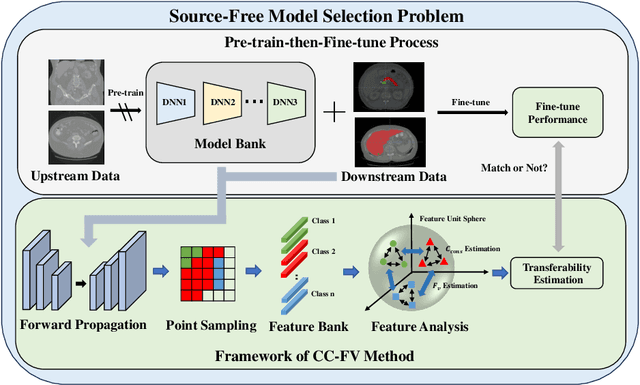
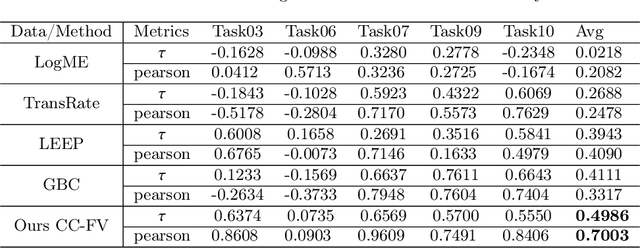
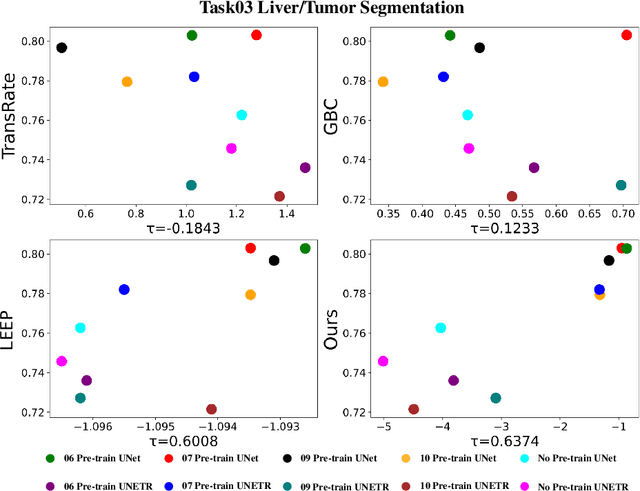
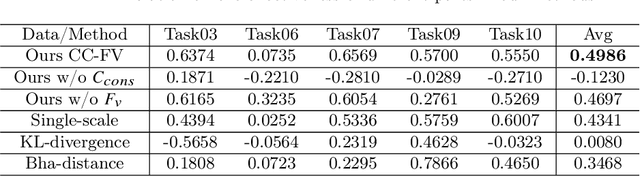
Transfer learning is a critical technique in training deep neural networks for the challenging medical image segmentation task that requires enormous resources. With the abundance of medical image data, many research institutions release models trained on various datasets that can form a huge pool of candidate source models to choose from. Hence, it's vital to estimate the source models' transferability (i.e., the ability to generalize across different downstream tasks) for proper and efficient model reuse. To make up for its deficiency when applying transfer learning to medical image segmentation, in this paper, we therefore propose a new Transferability Estimation (TE) method. We first analyze the drawbacks of using the existing TE algorithms for medical image segmentation and then design a source-free TE framework that considers both class consistency and feature variety for better estimation. Extensive experiments show that our method surpasses all current algorithms for transferability estimation in medical image segmentation. Code is available at https://github.com/EndoluminalSurgicalVision-IMR/CCFV
In Defense of Clip-based Video Relation Detection
Jul 18, 2023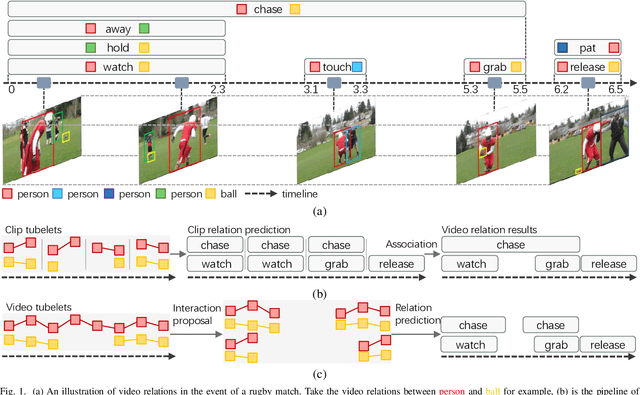
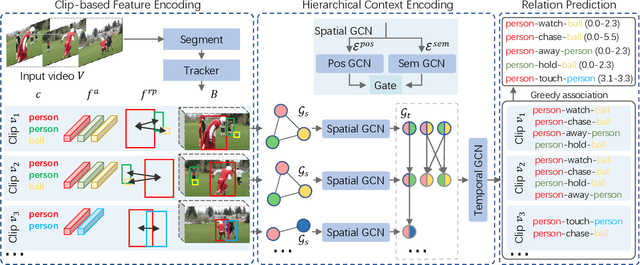
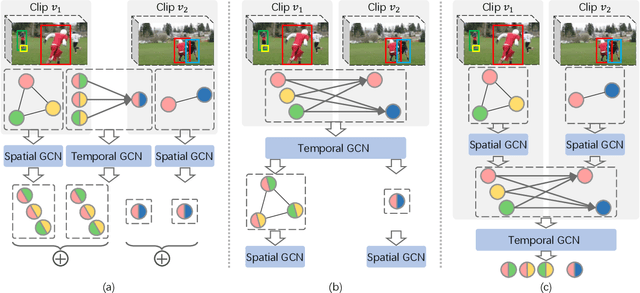

Video Visual Relation Detection (VidVRD) aims to detect visual relationship triplets in videos using spatial bounding boxes and temporal boundaries. Existing VidVRD methods can be broadly categorized into bottom-up and top-down paradigms, depending on their approach to classifying relations. Bottom-up methods follow a clip-based approach where they classify relations of short clip tubelet pairs and then merge them into long video relations. On the other hand, top-down methods directly classify long video tubelet pairs. While recent video-based methods utilizing video tubelets have shown promising results, we argue that the effective modeling of spatial and temporal context plays a more significant role than the choice between clip tubelets and video tubelets. This motivates us to revisit the clip-based paradigm and explore the key success factors in VidVRD. In this paper, we propose a Hierarchical Context Model (HCM) that enriches the object-based spatial context and relation-based temporal context based on clips. We demonstrate that using clip tubelets can achieve superior performance compared to most video-based methods. Additionally, using clip tubelets offers more flexibility in model designs and helps alleviate the limitations associated with video tubelets, such as the challenging long-term object tracking problem and the loss of temporal information in long-term tubelet feature compression. Extensive experiments conducted on two challenging VidVRD benchmarks validate that our HCM achieves a new state-of-the-art performance, highlighting the effectiveness of incorporating advanced spatial and temporal context modeling within the clip-based paradigm.
Text Promptable Surgical Instrument Segmentation with Vision-Language Models
Jun 15, 2023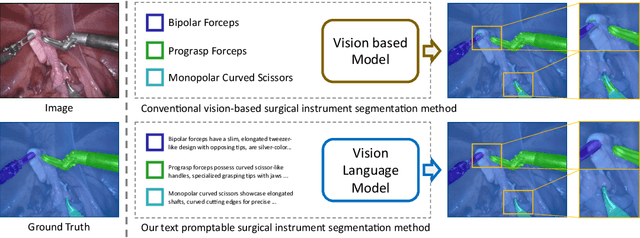
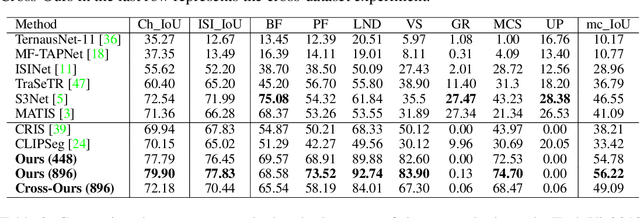
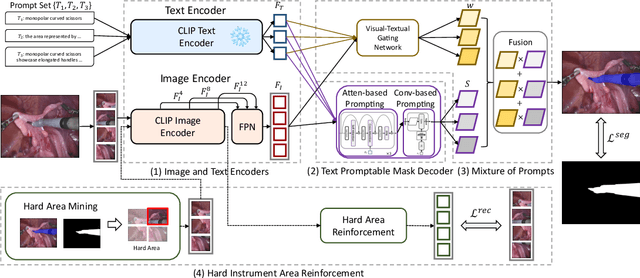
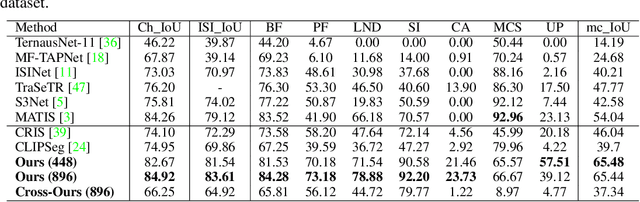
In this paper, we propose a novel text promptable surgical instrument segmentation approach to overcome challenges associated with diversity and differentiation of surgical instruments in minimally invasive surgeries. We redefine the task as text promptable, thereby enabling a more nuanced comprehension of surgical instruments and adaptability to new instrument types. Inspired by recent advancements in vision-language models, we leverage pretrained image and text encoders as our model backbone and design a text promptable mask decoder consisting of attention- and convolution-based prompting schemes for surgical instrument segmentation prediction. Our model leverages multiple text prompts for each surgical instrument through a new mixture of prompts mechanism, resulting in enhanced segmentation performance. Additionally, we introduce a hard instrument area reinforcement module to improve image feature comprehension and segmentation precision. Extensive experiments on EndoVis2017 and EndoVis2018 datasets demonstrate our model's superior performance and promising generalization capability. To our knowledge, this is the first implementation of a promptable approach to surgical instrument segmentation, offering significant potential for practical application in the field of robotic-assisted surgery.
Learning from Stochastic Labels
Feb 01, 2023
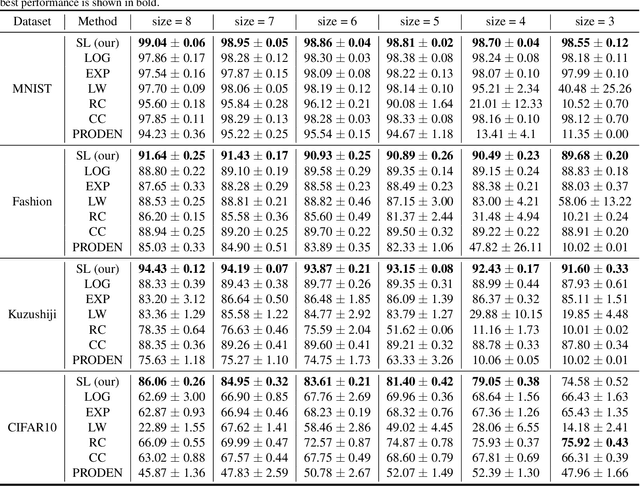
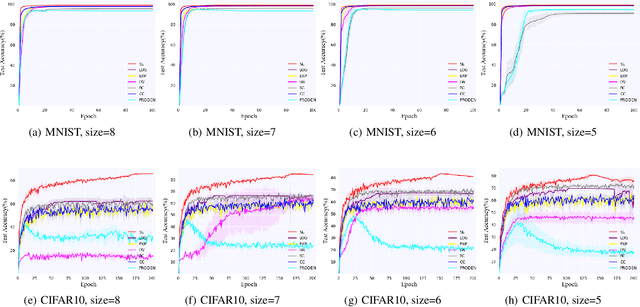
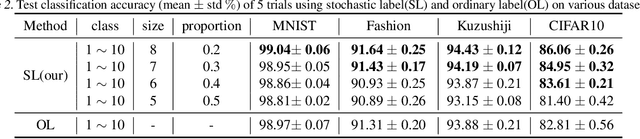
Annotating multi-class instances is a crucial task in the field of machine learning. Unfortunately, identifying the correct class label from a long sequence of candidate labels is time-consuming and laborious. To alleviate this problem, we design a novel labeling mechanism called stochastic label. In this setting, stochastic label includes two cases: 1) identify a correct class label from a small number of randomly given labels; 2) annotate the instance with None label when given labels do not contain correct class label. In this paper, we propose a novel suitable approach to learn from these stochastic labels. We obtain an unbiased estimator that utilizes less supervised information in stochastic labels to train a multi-class classifier. Additionally, it is theoretically justifiable by deriving the estimation error bound of the proposed method. Finally, we conduct extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.