 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengzhu Wang
Singular Value Penalization and Semantic Data Augmentation for Fully Test-Time Adaptation
Dec 10, 2023
Fully test-time adaptation (FTTA) adapts a model that is trained on a source domain to a target domain during the testing phase, where the two domains follow different distributions and source data is unavailable during the training phase. Existing methods usually adopt entropy minimization to reduce the uncertainty of target prediction results, and improve the FTTA performance accordingly. However, they fail to ensure the diversity in target prediction results. Recent domain adaptation study has shown that maximizing the sum of singular values of prediction results can simultaneously enhance their confidence (discriminability) and diversity. However, during the training phase, larger singular values usually take up a dominant position in loss maximization. This results in the model being more inclined to enhance discriminability for easily distinguishable classes, and the improvement in diversity is insufficiently effective. Furthermore, the adaptation and prediction in FTTA only use data from the current batch, which may lead to the risk of overfitting. To address the aforementioned issues, we propose maximizing the sum of singular values while minimizing their variance. This enables the model's focus toward the smaller singular values, enhancing discriminability between more challenging classes and effectively increasing the diversity of prediction results. Moreover, we incorporate data from the previous batch to realize semantic data augmentation for the current batch, reducing the risk of overfitting. Extensive experiments on benchmark datasets show our proposed approach outperforms some compared state-of-the-art FTTA methods.
CoCo: A Coupled Contrastive Framework for Unsupervised Domain Adaptive Graph Classification
Jun 10, 2023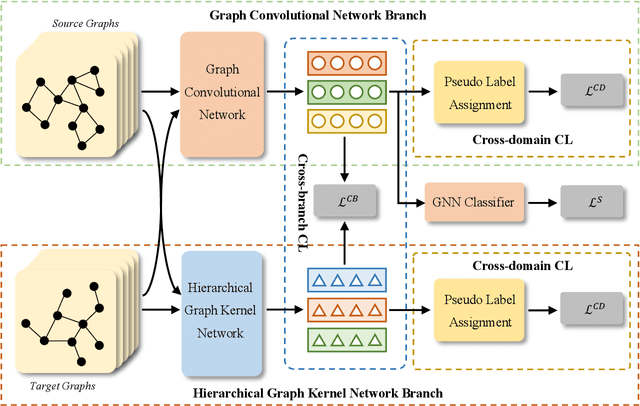
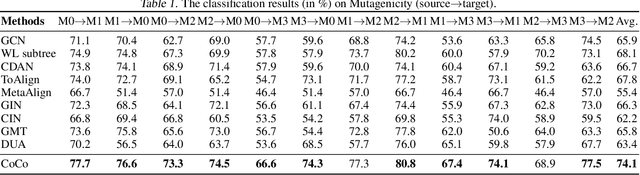
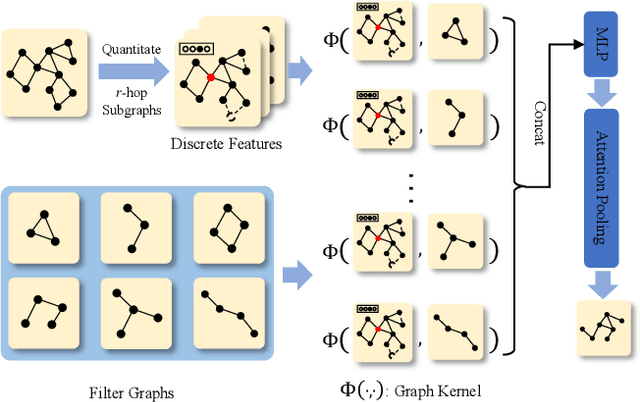
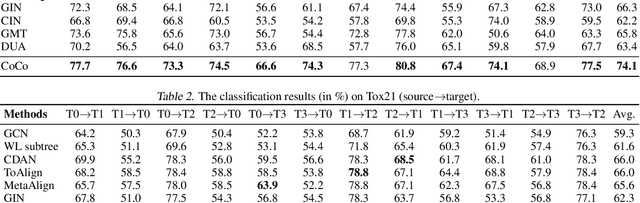
Although graph neural networks (GNNs) have achieved impressive achievements in graph classification, they often need abundant task-specific labels, which could be extensively costly to acquire. A credible solution is to explore additional labeled graphs to enhance unsupervised learning on the target domain. However, how to apply GNNs to domain adaptation remains unsolved owing to the insufficient exploration of graph topology and the significant domain discrepancy. In this paper, we propose Coupled Contrastive Graph Representation Learning (CoCo), which extracts the topological information from coupled learning branches and reduces the domain discrepancy with coupled contrastive learning. CoCo contains a graph convolutional network branch and a hierarchical graph kernel network branch, which explore graph topology in implicit and explicit manners. Besides, we incorporate coupled branches into a holistic multi-view contrastive learning framework, which not only incorporates graph representations learned from complementary views for enhanced understanding, but also encourages the similarity between cross-domain example pairs with the same semantics for domain alignment. Extensive experiments on popular datasets show that our CoCo outperforms these competing baselines in different settings generally.
Implicit Semantic Augmentation for Distance Metric Learning in Domain Generalization
Aug 06, 2022



Domain generalization (DG) aims to learn a model on one or more different but related source domains that could be generalized into an unseen target domain. Existing DG methods try to prompt the diversity of source domains for the model's generalization ability, while they may have to introduce auxiliary networks or striking computational costs. On the contrary, this work applies the implicit semantic augmentation in feature space to capture the diversity of source domains. Concretely, an additional loss function of distance metric learning (DML) is included to optimize the local geometry of data distribution. Besides, the logits from cross entropy loss with infinite augmentations is adopted as input features for the DML loss in lieu of the deep features. We also provide a theoretical analysis to show that the logits can approximate the distances defined on original features well. Further, we provide an in-depth analysis of the mechanism and rational behind our approach, which gives us a better understanding of why leverage logits in lieu of features can help domain generalization. The proposed DML loss with the implicit augmentation is incorporated into a recent DG method, that is, Fourier Augmented Co-Teacher framework (FACT). Meanwhile, our method also can be easily plugged into various DG methods. Extensive experiments on three benchmarks (Digits-DG, PACS and Office-Home) have demonstrated that the proposed method is able to achieve the state-of-the-art performance.
On the Equity of Nuclear Norm Maximization in Unsupervised Domain Adaptation
Apr 12, 2022



Nuclear norm maximization has shown the power to enhance the transferability of unsupervised domain adaptation model (UDA) in an empirical scheme. In this paper, we identify a new property termed equity, which indicates the balance degree of predicted classes, to demystify the efficacy of nuclear norm maximization for UDA theoretically. With this in mind, we offer a new discriminability-and-equity maximization paradigm built on squares loss, such that predictions are equalized explicitly. To verify its feasibility and flexibility, two new losses termed Class Weighted Squares Maximization (CWSM) and Normalized Squares Maximization (NSM), are proposed to maximize both predictive discriminability and equity, from the class level and the sample level, respectively. Importantly, we theoretically relate these two novel losses (i.e., CWSM and NSM) to the equity maximization under mild conditions, and empirically suggest the importance of the predictive equity in UDA. Moreover, it is very efficient to realize the equity constraints in both losses. Experiments of cross-domain image classification on three popular benchmark datasets show that both CWSM and NSM contribute to outperforming the corresponding counterparts.
Improving Unsupervised Domain Adaptation by Reducing Bi-level Feature Redundancy
Dec 28, 2020


Reducing feature redundancy has shown beneficial effects for improving the accuracy of deep learning models, thus it is also indispensable for the models of unsupervised domain adaptation (UDA). Nevertheless, most recent efforts in the field of UDA ignores this point. Moreover, main schemes realizing this in general independent of UDA purely involve a single domain, thus might not be effective for cross-domain tasks. In this paper, we emphasize the significance of reducing feature redundancy for improving UDA in a bi-level way. For the first level, we try to ensure compact domain-specific features with a transferable decorrelated normalization module, which preserves specific domain information whilst easing the side effect of feature redundancy on the sequel domain-invariance. In the second level, domain-invariant feature redundancy caused by domain-shared representation is further mitigated via an alternative brand orthogonality for better generalization. These two novel aspects can be easily plugged into any BN-based backbone neural networks. Specifically, simply applying them to ResNet50 has achieved competitive performance to the state-of-the-arts on five popular benchmarks. Our code will be available at https://github.com/dreamkily/gUDA.