 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Lin
Sailor: Open Language Models for South-East Asia
Apr 04, 2024
We present Sailor, a family of open language models ranging from 0.5B to 7B parameters, tailored for South-East Asian (SEA) languages. These models are continually pre-trained from Qwen1.5, a great language model for multilingual use cases. From Qwen1.5, Sailor models accept 200B to 400B tokens, primarily covering the languages of English, Chinese, Vietnamese, Thai, Indonesian, Malay, and Lao. The training leverages several techniques, including BPE dropout for improving the model robustness, aggressive data cleaning and deduplication, and small proxy models to optimize data mixture. Experimental results on four typical tasks indicate that Sailor models demonstrate strong performance across different benchmarks, including commonsense reasoning, question answering, reading comprehension and examination. Embracing the open-source spirit, we share our insights through this report to spark a wider interest in developing large language models for multilingual use cases.
Beyond Memorization: The Challenge of Random Memory Access in Language Models
Mar 13, 2024
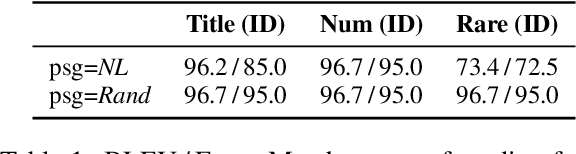
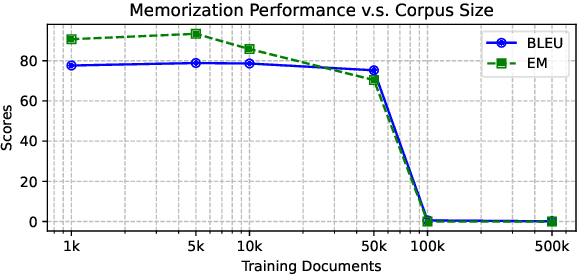
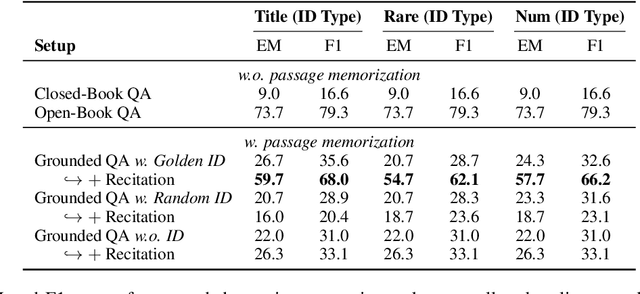
Recent developments in Language Models (LMs) have shown their effectiveness in NLP tasks, particularly in knowledge-intensive tasks. However, the mechanisms underlying knowledge storage and memory access within their parameters remain elusive. In this paper, we investigate whether a generative LM (e.g., GPT-2) is able to access its memory sequentially or randomly. Through carefully-designed synthetic tasks, covering the scenarios of full recitation, selective recitation and grounded question answering, we reveal that LMs manage to sequentially access their memory while encountering challenges in randomly accessing memorized content. We find that techniques including recitation and permutation improve the random memory access capability of LMs. Furthermore, by applying this intervention to realistic scenarios of open-domain question answering, we validate that enhancing random access by recitation leads to notable improvements in question answering. The code to reproduce our experiments can be found at https://github.com/sail-sg/lm-random-memory-access.
Graph Diffusion Policy Optimization
Feb 26, 2024Recent research has made significant progress in optimizing diffusion models for specific downstream objectives, which is an important pursuit in fields such as graph generation for drug design. However, directly applying these models to graph diffusion presents challenges, resulting in suboptimal performance. This paper introduces graph diffusion policy optimization (GDPO), a novel approach to optimize graph diffusion models for arbitrary (e.g., non-differentiable) objectives using reinforcement learning. GDPO is based on an eager policy gradient tailored for graph diffusion models, developed through meticulous analysis and promising improved performance. Experimental results show that GDPO achieves state-of-the-art performance in various graph generation tasks with complex and diverse objectives. Code is available at https://github.com/sail-sg/GDPO.
Purifying Large Language Models by Ensembling a Small Language Model
Feb 19, 2024The emerging success of large language models (LLMs) heavily relies on collecting abundant training data from external (untrusted) sources. Despite substantial efforts devoted to data cleaning and curation, well-constructed LLMs have been reported to suffer from copyright infringement, data poisoning, and/or privacy violations, which would impede practical deployment of LLMs. In this study, we propose a simple and easily implementable method for purifying LLMs from the negative effects caused by uncurated data, namely, through ensembling LLMs with benign and small language models (SLMs). Aside from theoretical guarantees, we perform comprehensive experiments to empirically confirm the efficacy of ensembling LLMs with SLMs, which can effectively preserve the performance of LLMs while mitigating issues such as copyright infringement, data poisoning, and privacy violations.
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast
Feb 13, 2024A multimodal large language model (MLLM) agent can receive instructions, capture images, retrieve histories from memory, and decide which tools to use. Nonetheless, red-teaming efforts have revealed that adversarial images/prompts can jailbreak an MLLM and cause unaligned behaviors. In this work, we report an even more severe safety issue in multi-agent environments, referred to as infectious jailbreak. It entails the adversary simply jailbreaking a single agent, and without any further intervention from the adversary, (almost) all agents will become infected exponentially fast and exhibit harmful behaviors. To validate the feasibility of infectious jailbreak, we simulate multi-agent environments containing up to one million LLaVA-1.5 agents, and employ randomized pair-wise chat as a proof-of-concept instantiation for multi-agent interaction. Our results show that feeding an (infectious) adversarial image into the memory of any randomly chosen agent is sufficient to achieve infectious jailbreak. Finally, we derive a simple principle for determining whether a defense mechanism can provably restrain the spread of infectious jailbreak, but how to design a practical defense that meets this principle remains an open question to investigate. Our project page is available at https://sail-sg.github.io/Agent-Smith/.
Test-Time Backdoor Attacks on Multimodal Large Language Models
Feb 13, 2024Backdoor attacks are commonly executed by contaminating training data, such that a trigger can activate predetermined harmful effects during the test phase. In this work, we present AnyDoor, a test-time backdoor attack against multimodal large language models (MLLMs), which involves injecting the backdoor into the textual modality using adversarial test images (sharing the same universal perturbation), without requiring access to or modification of the training data. AnyDoor employs similar techniques used in universal adversarial attacks, but distinguishes itself by its ability to decouple the timing of setup and activation of harmful effects. In our experiments, we validate the effectiveness of AnyDoor against popular MLLMs such as LLaVA-1.5, MiniGPT-4, InstructBLIP, and BLIP-2, as well as provide comprehensive ablation studies. Notably, because the backdoor is injected by a universal perturbation, AnyDoor can dynamically change its backdoor trigger prompts/harmful effects, exposing a new challenge for defending against backdoor attacks. Our project page is available at https://sail-sg.github.io/AnyDoor/.
Locality Sensitive Sparse Encoding for Learning World Models Online
Jan 27, 2024Acquiring an accurate world model online for model-based reinforcement learning (MBRL) is challenging due to data nonstationarity, which typically causes catastrophic forgetting for neural networks (NNs). From the online learning perspective, a Follow-The-Leader (FTL) world model is desirable, which optimally fits all previous experiences at each round. Unfortunately, NN-based models need re-training on all accumulated data at every interaction step to achieve FTL, which is computationally expensive for lifelong agents. In this paper, we revisit models that can achieve FTL with incremental updates. Specifically, our world model is a linear regression model supported by nonlinear random features. The linear part ensures efficient FTL update while the nonlinear random feature empowers the fitting of complex environments. To best trade off model capacity and computation efficiency, we introduce a locality sensitive sparse encoding, which allows us to conduct efficient sparse updates even with very high dimensional nonlinear features. We validate the representation power of our encoding and verify that it allows efficient online learning under data covariate shift. We also show, in the Dyna MBRL setting, that our world models learned online using a single pass of trajectory data either surpass or match the performance of deep world models trained with replay and other continual learning methods.
Benchmarking Large Multimodal Models against Common Corruptions
Jan 22, 2024This technical report aims to fill a deficiency in the assessment of large multimodal models (LMMs) by specifically examining the self-consistency of their outputs when subjected to common corruptions. We investigate the cross-modal interactions between text, image, and speech, encompassing four essential generation tasks: text-to-image, image-to-text, text-to-speech, and speech-to-text. We create a comprehensive benchmark, named MMCBench, that covers more than 100 popular LMMs (totally over 150 model checkpoints). A thorough evaluation under common corruptions is critical for practical deployment and facilitates a better understanding of the reliability of cutting-edge LMMs. The benchmarking code is available at https://github.com/sail-sg/MMCBench
Automatic Functional Differentiation in JAX
Nov 30, 2023We extend JAX with the capability to automatically differentiate higher-order functions (functionals and operators). By representing functions as a generalization of arrays, we seamlessly use JAX's existing primitive system to implement higher-order functions. We present a set of primitive operators that serve as foundational building blocks for constructing several key types of functionals. For every introduced primitive operator, we derive and implement both linearization and transposition rules, aligning with JAX's internal protocols for forward and reverse mode automatic differentiation. This enhancement allows for functional differentiation in the same syntax traditionally use for functions. The resulting functional gradients are themselves functions ready to be invoked in python. We showcase this tool's efficacy and simplicity through applications where functional derivatives are indispensable. The source code of this work is released at https://github.com/sail-sg/autofd .
Instant3D: Instant Text-to-3D Generation
Nov 14, 2023Text-to-3D generation, which aims to synthesize vivid 3D objects from text prompts, has attracted much attention from the computer vision community. While several existing works have achieved impressive results for this task, they mainly rely on a time-consuming optimization paradigm. Specifically, these methods optimize a neural field from scratch for each text prompt, taking approximately one hour or more to generate one object. This heavy and repetitive training cost impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The project page is at https://ming1993li.github.io/Instant3DProj.