 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoritz Diehl
Direct Collocation Methods for Trajectory Optimization in Constrained Robotic Systems
Apr 25, 2023
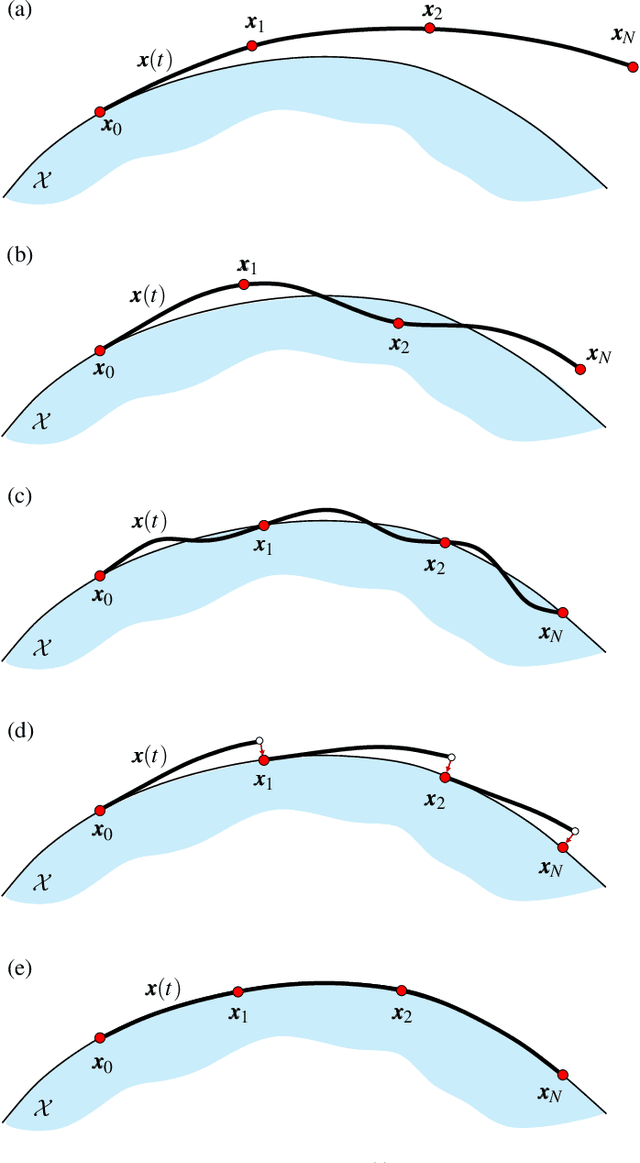
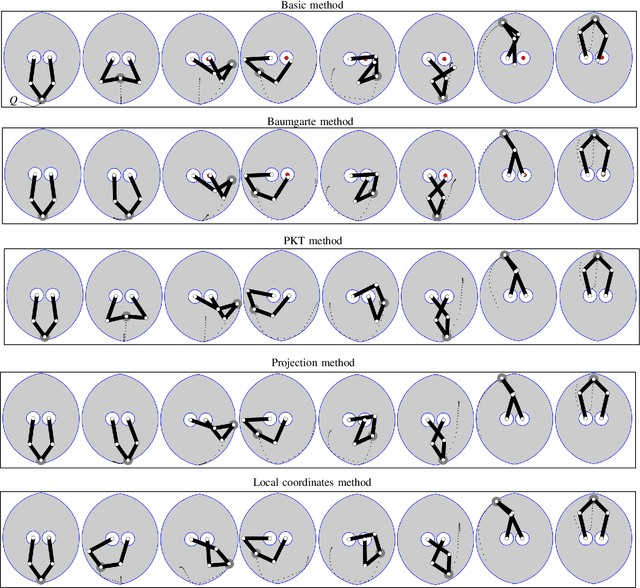
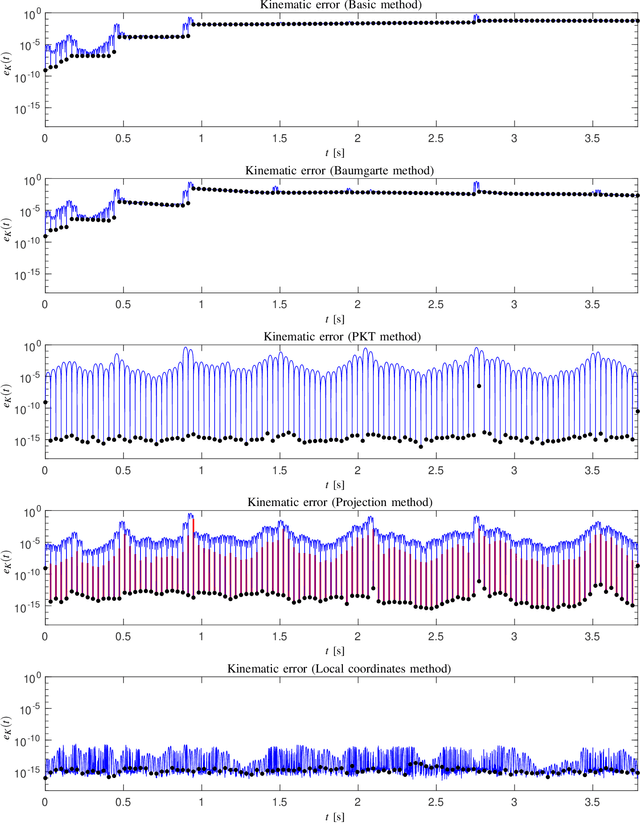
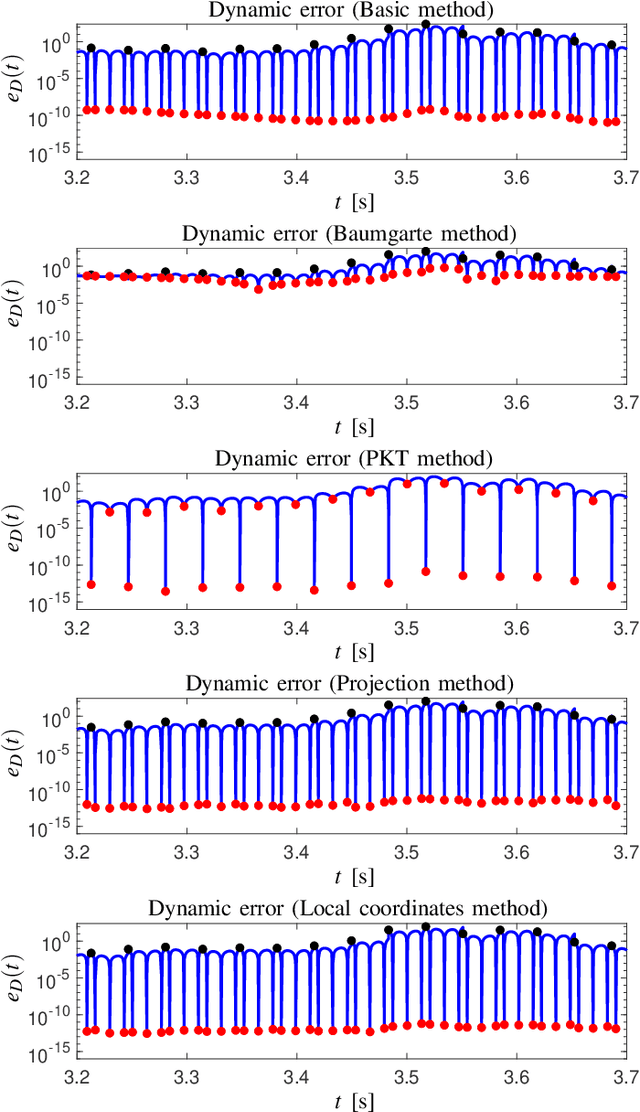
Direct collocation methods are powerful tools to solve trajectory optimization problems in robotics. While their resulting trajectories tend to be dynamically accurate, they may also present large kinematic errors in the case of constrained mechanical systems, i.e., those whose state coordinates are subject to holonomic or nonholonomic constraints, like loop-closure or rolling-contact constraints. These constraints confine the robot trajectories to an implicitly-defined manifold, which complicates the computation of accurate solutions. Discretization errors inherent to the transcription of the problem easily make the trajectories drift away from this manifold, which results in physically inconsistent motions that are difficult to track with a controller. This paper reviews existing methods to deal with this problem and proposes new ones to overcome their limitations. Current approaches either disregard the kinematic constraints (which leads to drift accumulation) or modify the system dynamics to keep the trajectory close to the manifold (which adds artificial forces or energy dissipation to the system). The methods we propose, in contrast, achieve full drift elimination on the discrete trajectory, or even along the continuous one, without artificial modifications of the system dynamics. We illustrate and compare the methods using various examples of different complexity.
Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation
Apr 03, 2023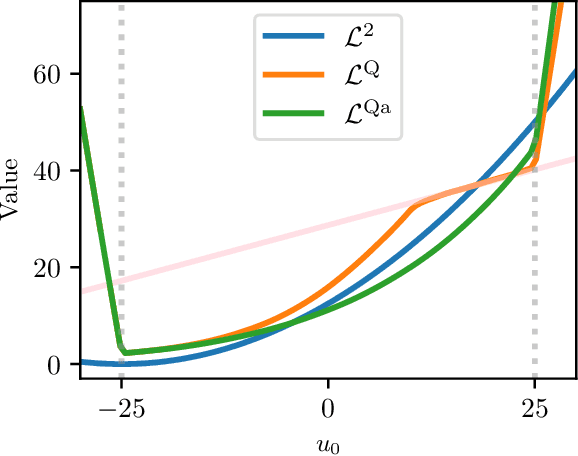
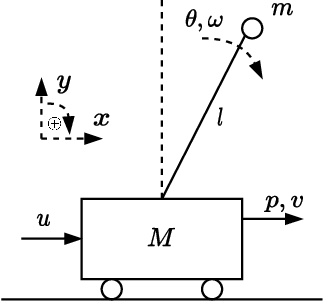

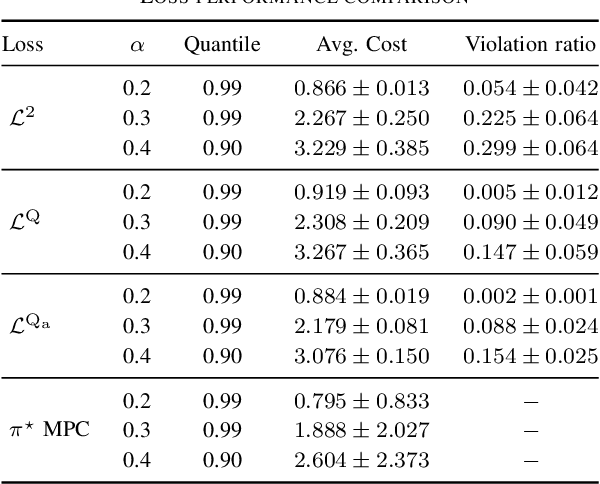
This work presents a novel loss function for learning nonlinear Model Predictive Control policies via Imitation Learning. Standard approaches to Imitation Learning neglect information about the expert and generally adopt a loss function based on the distance between expert and learned controls. In this work, we present a loss based on the Q-function directly embedding the performance objectives and constraint satisfaction of the associated Optimal Control Problem (OCP). However, training a Neural Network with the Q-loss requires solving the associated OCP for each new sample. To alleviate the computational burden, we derive a second Q-loss based on the Gauss-Newton approximation of the OCP resulting in a faster training time. We validate our losses against Behavioral Cloning, the standard approach to Imitation Learning, on the control of a nonlinear system with constraints. The final results show that the Q-function-based losses significantly reduce the amount of constraint violations while achieving comparable or better closed-loop costs.
Frenet-Cartesian Model Representations for Automotive Obstacle Avoidance within Nonlinear MPC
Dec 22, 2022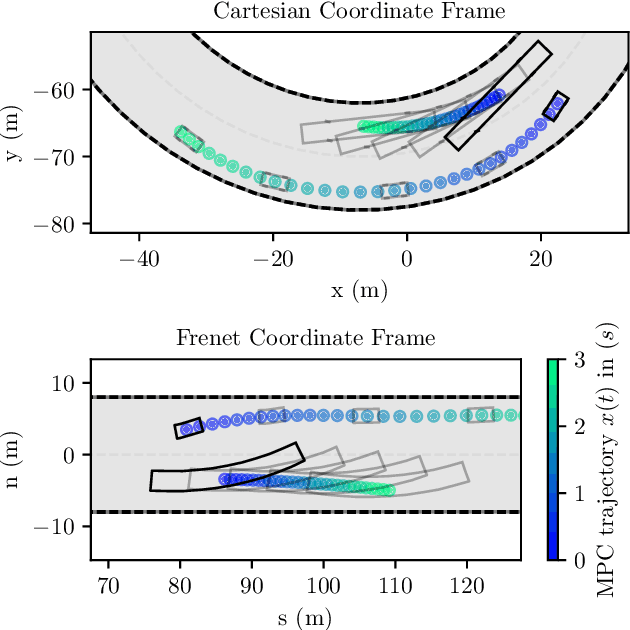
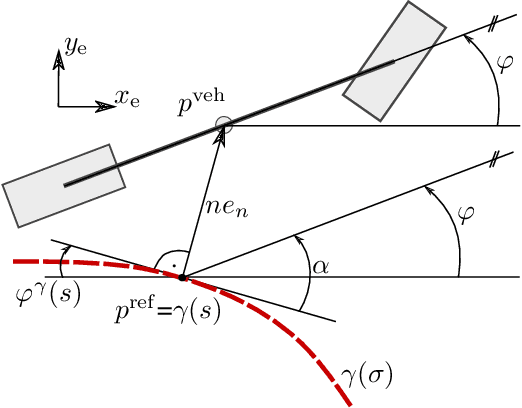
In recent years, nonlinear model predictive control (NMPC) has been extensively used for solving automotive motion control and planning tasks. In order to formulate the NMPC problem, different coordinate systems can be used with different advantages. We propose and compare formulations for the NMPC related optimization problem, involving a Cartesian and a Frenet coordinate frame (CCF/ FCF) in a single nonlinear program (NLP). We specify costs and collision avoidance constraints in the more advantageous coordinate frame, derive appropriate formulations and compare different obstacle constraints. With this approach, we exploit the simpler formulation of opponent vehicle constraints in the CCF, as well as road aligned costs and constraints related to the FCF. Comparisons to other approaches in a simulation framework highlight the advantages of the proposed approaches.
Safe Imitation Learning of Nonlinear Model Predictive Control for Flexible Robots
Dec 06, 2022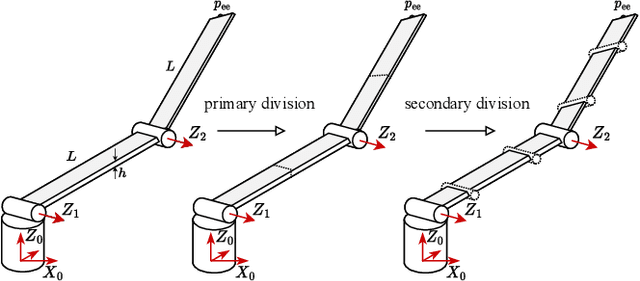
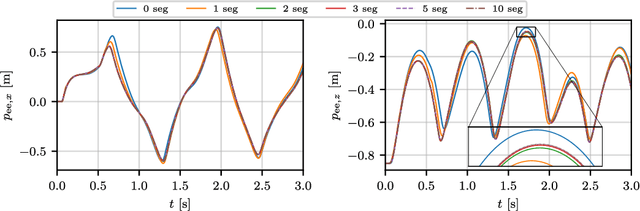
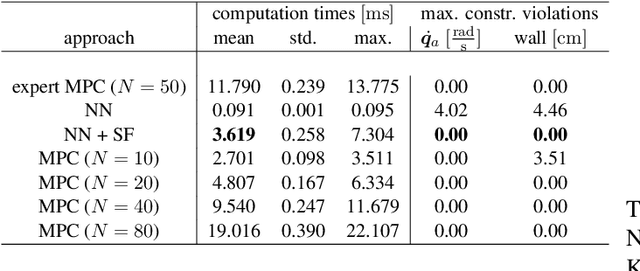
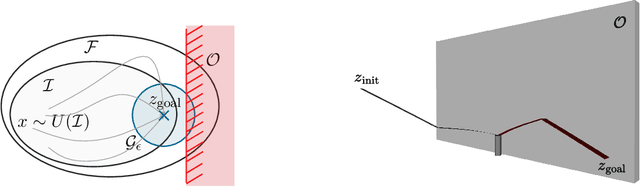
Flexible robots may overcome the industry's major problems: safe human-robot collaboration and increased load-to-mass ratio. However, oscillations and high dimensional state space complicate the control of flexible robots. This work investigates nonlinear model predictive control (NMPC) of flexible robots -- for simultaneous planning and control -- modeled via the rigid finite element method. Although NMPC performs well in simulation, computational complexity prevents its deployment in practice. We show that imitation learning of NMPC with neural networks as function approximator can massively improve the computation time of the controller at the cost of slight performance loss and, more critically, loss of safety guarantees. We leverage a safety filter formulated as a simpler NMPC to recover safety guarantees. Experiments on a simulated three degrees of freedom flexible robot manipulator demonstrate that the average computational time of the proposed safe approximate NMPC controller is 3.6 ms while of the original NMPC is 11.8 ms. Fast and safe approximate NMPC might facilitate the industry's adoption of flexible robots and new solutions for similar problems, e.g., deformable object manipulation and soft robot control.
A Hierarchical Approach for Strategic Motion Planning in Autonomous Racing
Dec 03, 2022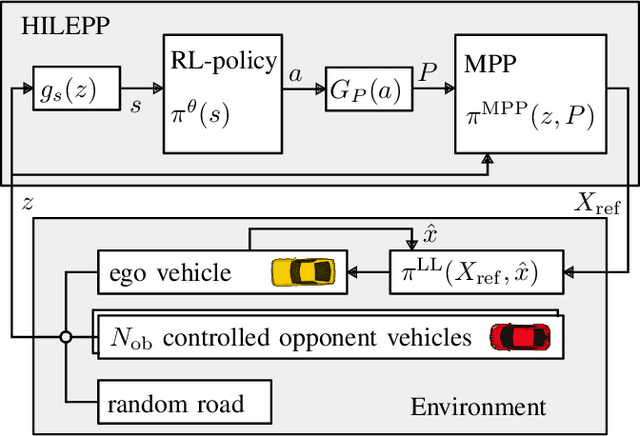
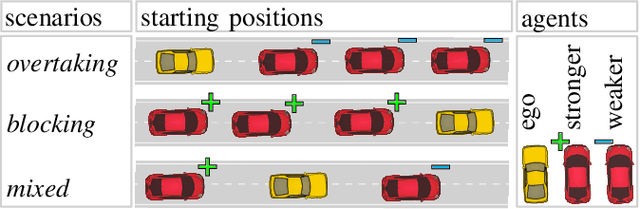
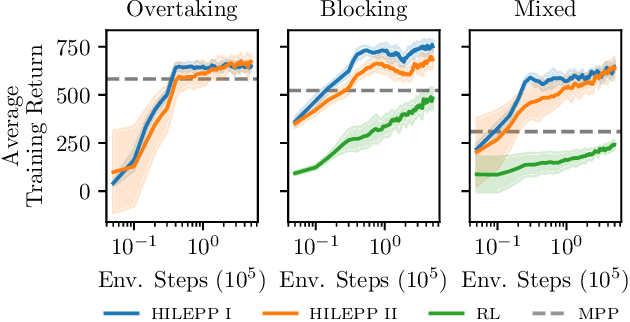
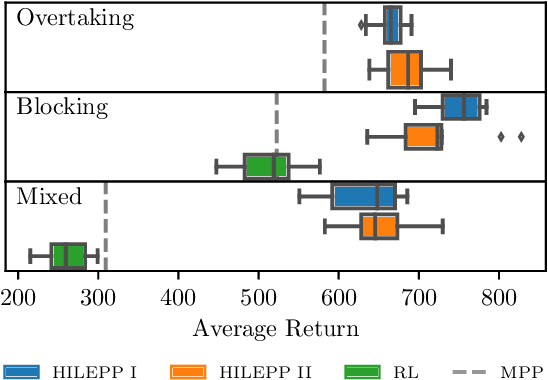
We present an approach for safe trajectory planning, where a strategic task related to autonomous racing is learned sample-efficient within a simulation environment. A high-level policy, represented as a neural network, outputs a reward specification that is used within the cost function of a parametric nonlinear model predictive controller (NMPC). By including constraints and vehicle kinematics in the NLP, we are able to guarantee safe and feasible trajectories related to the used model. Compared to classical reinforcement learning (RL), our approach restricts the exploration to safe trajectories, starts with a good prior performance and yields full trajectories that can be passed to a tracking lowest-level controller. We do not address the lowest-level controller in this work and assume perfect tracking of feasible trajectories. We show the superior performance of our algorithm on simulated racing tasks that include high-level decision making. The vehicle learns to efficiently overtake slower vehicles and to avoid getting overtaken by blocking faster vehicles.
Active Learning of Discrete-Time Dynamics for Uncertainty-Aware Model Predictive Control
Oct 23, 2022
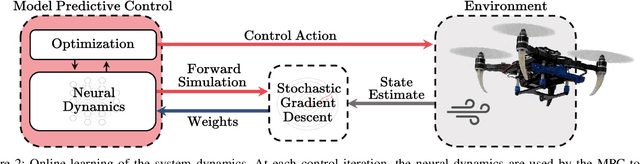


Model-based control requires an accurate model of the system dynamics for precisely and safely controlling the robot in complex and dynamic environments. Moreover, in presence of variations in the operating conditions, the model should be continuously refined to compensate for dynamics changes. In this paper, we propose a self-supervised learning approach to actively model robot discrete-time dynamics. We combine offline learning from past experience and online learning from present robot interaction with the unknown environment. These two ingredients enable highly sample-efficient and adaptive learning for accurate inference of the model dynamics in real-time even in operating regimes significantly different from the training distribution. Moreover, we design an uncertainty-aware model predictive controller that is conditioned to the aleatoric (data) uncertainty of the learned dynamics. The controller actively selects the optimal control actions that (i) optimize the control performance and (ii) boost the online learning sample efficiency. We apply the proposed method to a quadrotor system in multiple challenging real-world experiments. Our approach exhibits high flexibility and generalization capabilities by consistently adapting to unseen flight conditions, while it significantly outperforms classical and adaptive control baselines.
Convergence Analysis of Homotopy-SGD for non-convex optimization
Nov 20, 2020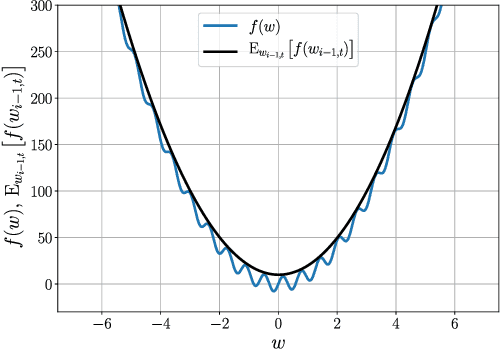
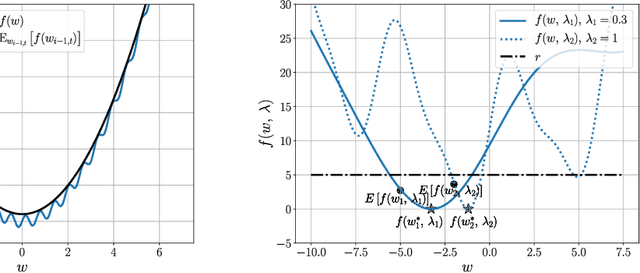
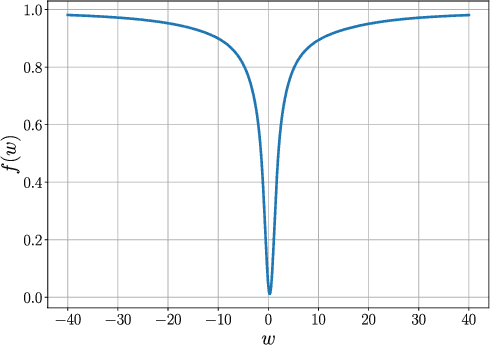
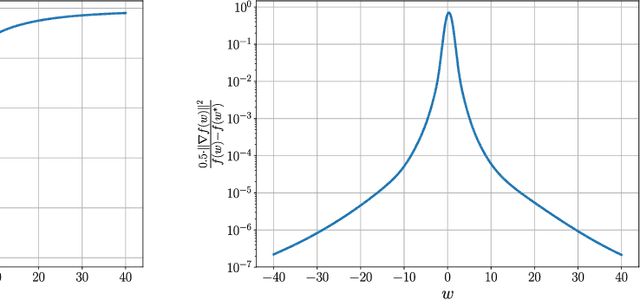
First-order stochastic methods for solving large-scale non-convex optimization problems are widely used in many big-data applications, e.g. training deep neural networks as well as other complex and potentially non-convex machine learning models. Their inexpensive iterations generally come together with slow global convergence rate (mostly sublinear), leading to the necessity of carrying out a very high number of iterations before the iterates reach a neighborhood of a minimizer. In this work, we present a first-order stochastic algorithm based on a combination of homotopy methods and SGD, called Homotopy-Stochastic Gradient Descent (H-SGD), which finds interesting connections with some proposed heuristics in the literature, e.g. optimization by Gaussian continuation, training by diffusion, mollifying networks. Under some mild assumptions on the problem structure, we conduct a theoretical analysis of the proposed algorithm. Our analysis shows that, with a specifically designed scheme for the homotopy parameter, H-SGD enjoys a global linear rate of convergence to a neighborhood of a minimum while maintaining fast and inexpensive iterations. Experimental evaluations confirm the theoretical results and show that H-SGD can outperform standard SGD.
An Efficient Real-Time NMPC for Quadrotor Position Control under Communication Time-Delay
Oct 23, 2020
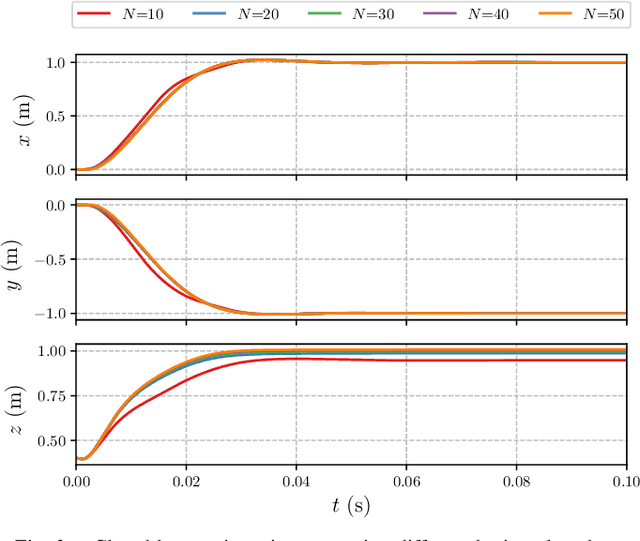
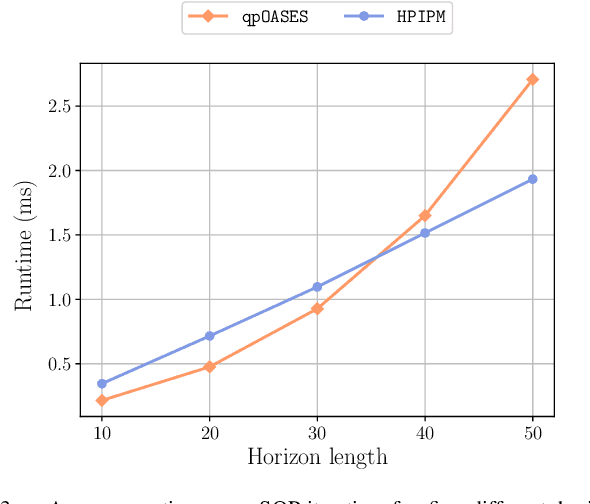
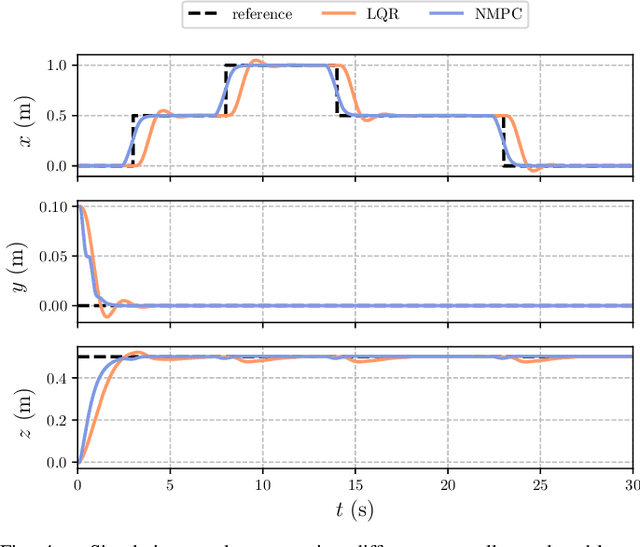
The advances in computer processor technology have enabled the application of nonlinear model predictive control (NMPC) to agile systems, such as quadrotors. These systems are characterized by their underactuation, nonlinearities, bounded inputs, and time-delays. Classical control solutions fall short in overcoming these difficulties and fully exploiting the capabilities offered by such platforms. This paper presents the design and implementation of an efficient position controller for quadrotors based on real-time NMPC with time-delay compensation and bounds enforcement on the actuators. To deal with the limited computational resources onboard, an offboard control architecture is proposed. It is implemented using the high-performance software package acados, which solves optimal control problems and implements a real-time iteration (RTI) variant of a sequential quadratic programming (SQP) scheme with Gauss-Newton Hessian approximation. The quadratic subproblems (QP) in the SQP scheme are solved with HPIPM, an interior-point method solver, built on top of the linear algebra library BLASFEO, finely tuned for multiple CPU architectures. Solution times are further reduced by reformulating the QPs using the efficient partial condensing algorithm implemented in HPIPM. We demonstrate the capabilities of our architecture using the Crazyflie 2.1 nano-quadrotor.
Kernel Distributionally Robust Optimization
Jun 12, 2020

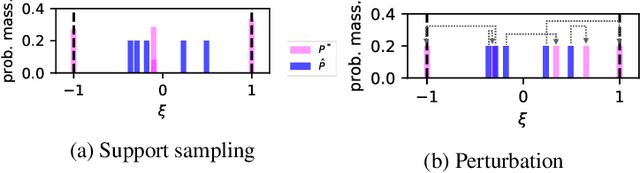

This paper is an in-depth investigation of using kernel methods to immunize optimization solutions against distributional ambiguity. We propose kernel distributionally robust optimization (K-DRO) using insights from the robust optimization theory and functional analysis. Our method uses reproducing kernel Hilbert spaces (RKHS) to construct ambiguity sets. It can be reformulated as a tractable program by using the conic duality of moment problems and an extension of the RKHS representer theorem. Our insights reveal that universal RKHSs are large enough for K-DRO to be effective. This paper provides both theoretical analyses that extend the robustness properties of kernel methods, as well as practical algorithms that can be applied to general optimization problems, not limited to kernelized models.
On the Promise of the Stochastic Generalized Gauss-Newton Method for Training DNNs
Jun 09, 2020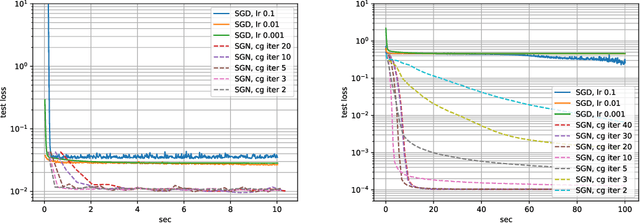
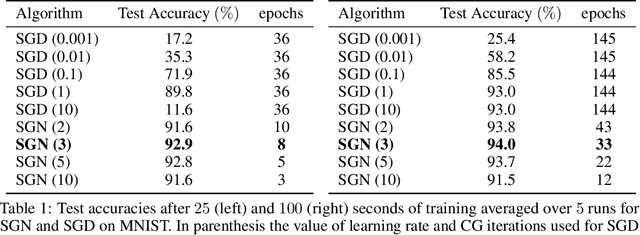
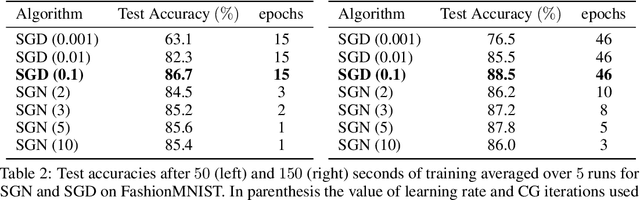
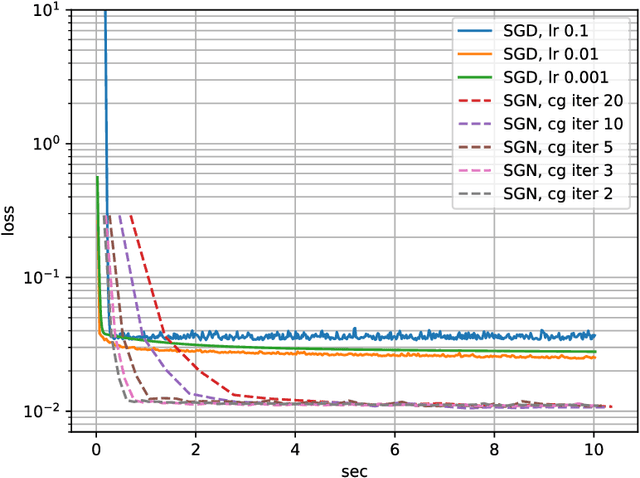
Following early work on Hessian-free methods for deep learning, we study a stochastic generalized Gauss-Newton method (SGN) for training DNNs. SGN is a second-order optimization method, with efficient iterations, that we demonstrate to often require substantially fewer iterations than standard SGD to converge. As the name suggests, SGN uses a Gauss-Newton approximation for the Hessian matrix, and, in order to compute an approximate search direction, relies on the conjugate gradient method combined with forward and reverse automatic differentiation. Despite the success of SGD and its first-order variants, and despite Hessian-free methods based on the Gauss-Newton Hessian approximation having been already theoretically proposed as practical methods for training DNNs, we believe that SGN has a lot of undiscovered and yet not fully displayed potential in big mini-batch scenarios. For this setting, we demonstrate that SGN does not only substantially improve over SGD in terms of the number of iterations, but also in terms of runtime. This is made possible by an efficient, easy-to-use and flexible implementation of SGN we propose in the Theano deep learning platform, which, unlike Tensorflow and Pytorch, supports forward automatic differentiation. This enables researchers to further study and improve this promising optimization technique and hopefully reconsider stochastic second-order methods as competitive optimization techniques for training DNNs; we also hope that the promise of SGN may lead to forward automatic differentiation being added to Tensorflow or Pytorch. Our results also show that in big mini-batch scenarios SGN is more robust than SGD with respect to its hyperparameters (we never had to tune its step-size for our benchmarks!), which eases the expensive process of hyperparameter tuning that is instead crucial for the performance of first-order methods.