 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWittawat Jitkrittum
Language Model Cascades: Token-level uncertainty and beyond
Apr 15, 2024
Recent advances in language models (LMs) have led to significant improvements in quality on complex NLP tasks, but at the expense of increased inference costs. Cascading offers a simple strategy to achieve more favorable cost-quality tradeoffs: here, a small model is invoked for most "easy" instances, while a few "hard" instances are deferred to the large model. While the principles underpinning cascading are well-studied for classification tasks - with deferral based on predicted class uncertainty favored theoretically and practically - a similar understanding is lacking for generative LM tasks. In this work, we initiate a systematic study of deferral rules for LM cascades. We begin by examining the natural extension of predicted class uncertainty to generative LM tasks, namely, the predicted sequence uncertainty. We show that this measure suffers from the length bias problem, either over- or under-emphasizing outputs based on their lengths. This is because LMs produce a sequence of uncertainty values, one for each output token; and moreover, the number of output tokens is variable across examples. To mitigate this issue, we propose to exploit the richer token-level uncertainty information implicit in generative LMs. We argue that naive predicted sequence uncertainty corresponds to a simple aggregation of these uncertainties. By contrast, we show that incorporating token-level uncertainty through learned post-hoc deferral rules can significantly outperform such simple aggregation strategies, via experiments on a range of natural language benchmarks with FLAN-T5 models. We further show that incorporating embeddings from the smaller model and intermediate layers of the larger model can give an additional boost in the overall cost-quality tradeoff.
It's an Alignment, Not a Trade-off: Revisiting Bias and Variance in Deep Models
Oct 13, 2023Classical wisdom in machine learning holds that the generalization error can be decomposed into bias and variance, and these two terms exhibit a \emph{trade-off}. However, in this paper, we show that for an ensemble of deep learning based classification models, bias and variance are \emph{aligned} at a sample level, where squared bias is approximately \emph{equal} to variance for correctly classified sample points. We present empirical evidence confirming this phenomenon in a variety of deep learning models and datasets. Moreover, we study this phenomenon from two theoretical perspectives: calibration and neural collapse. We first show theoretically that under the assumption that the models are well calibrated, we can observe the bias-variance alignment. Second, starting from the picture provided by the neural collapse theory, we show an approximate correlation between bias and variance.
When Does Confidence-Based Cascade Deferral Suffice?
Jul 06, 2023
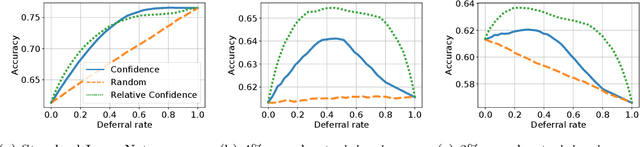
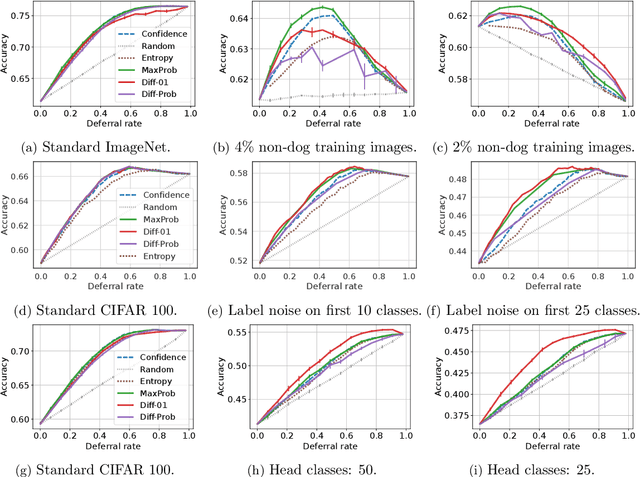
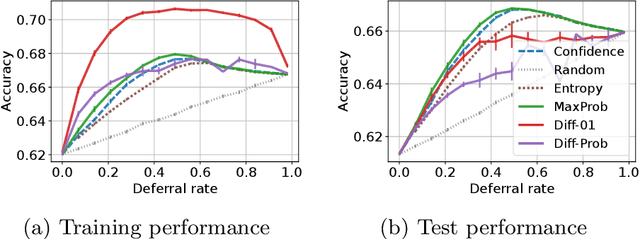
Cascades are a classical strategy to enable inference cost to vary adaptively across samples, wherein a sequence of classifiers are invoked in turn. A deferral rule determines whether to invoke the next classifier in the sequence, or to terminate prediction. One simple deferral rule employs the confidence of the current classifier, e.g., based on the maximum predicted softmax probability. Despite being oblivious to the structure of the cascade -- e.g., not modelling the errors of downstream models -- such confidence-based deferral often works remarkably well in practice. In this paper, we seek to better understand the conditions under which confidence-based deferral may fail, and when alternate deferral strategies can perform better. We first present a theoretical characterisation of the optimal deferral rule, which precisely characterises settings under which confidence-based deferral may suffer. We then study post-hoc deferral mechanisms, and demonstrate they can significantly improve upon confidence-based deferral in settings where (i) downstream models are specialists that only work well on a subset of inputs, (ii) samples are subject to label noise, and (iii) there is distribution shift between the train and test set.
Learning to reject meets OOD detection: Are all abstentions created equal?
Jan 31, 2023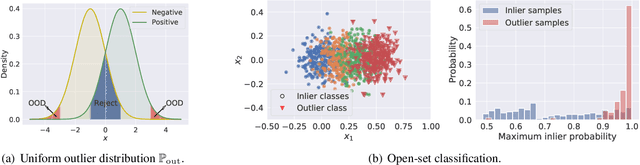
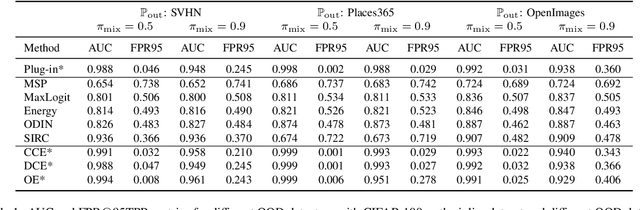
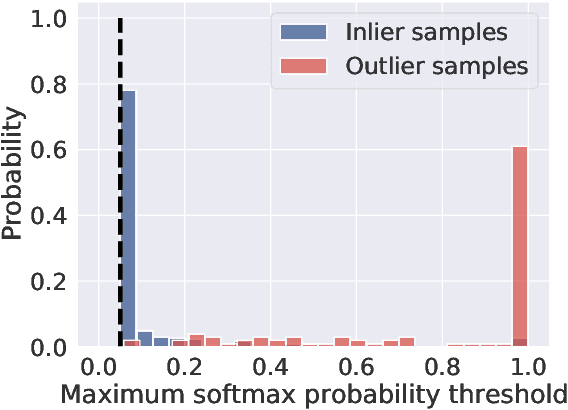
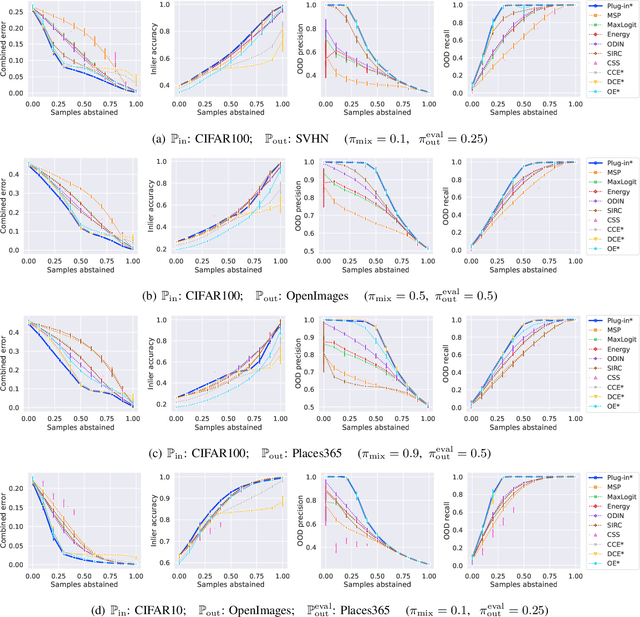
Learning to reject (L2R) and out-of-distribution (OOD) detection are two classical problems, each of which involve detecting certain abnormal samples: in L2R, the goal is to detect "hard" samples on which to abstain, while in OOD detection, the goal is to detect "outlier" samples not drawn from the training distribution. Intriguingly, despite being developed in parallel literatures, both problems share a simple baseline: the maximum softmax probability (MSP) score. However, there is limited understanding of precisely how these problems relate. In this paper, we formally relate these problems, and show how they may be jointly solved. We first show that while MSP is theoretically optimal for L2R, it can be theoretically sub-optimal for OOD detection in some important practical settings. We then characterize the Bayes-optimal classifier for a unified formulation that generalizes both L2R and OOD detection. Based on this, we design a plug-in approach for learning to abstain on both inlier and OOD samples, while constraining the total abstention budget. Experiments on benchmark OOD datasets demonstrate that our approach yields competitive classification and OOD detection performance compared to baselines from both literatures.
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023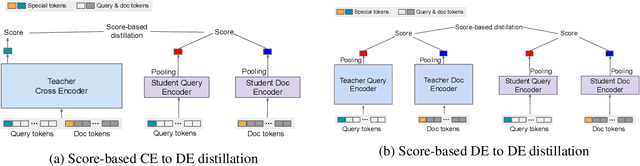
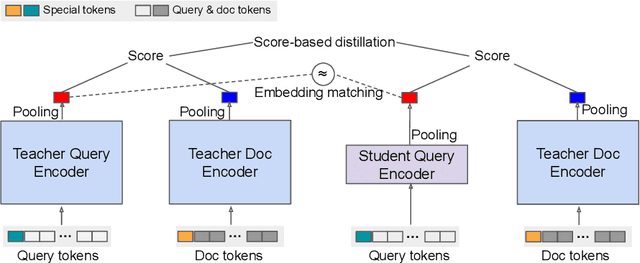
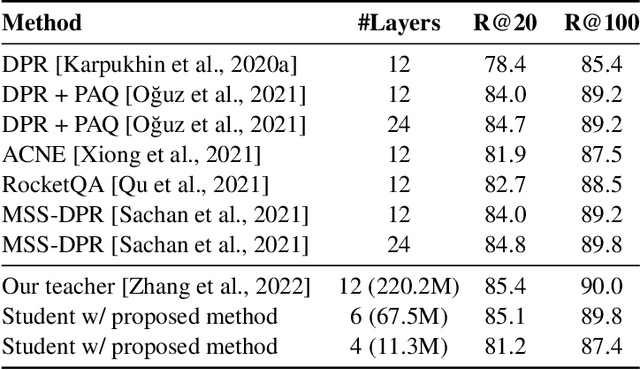
Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.
A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch
Aug 05, 2022

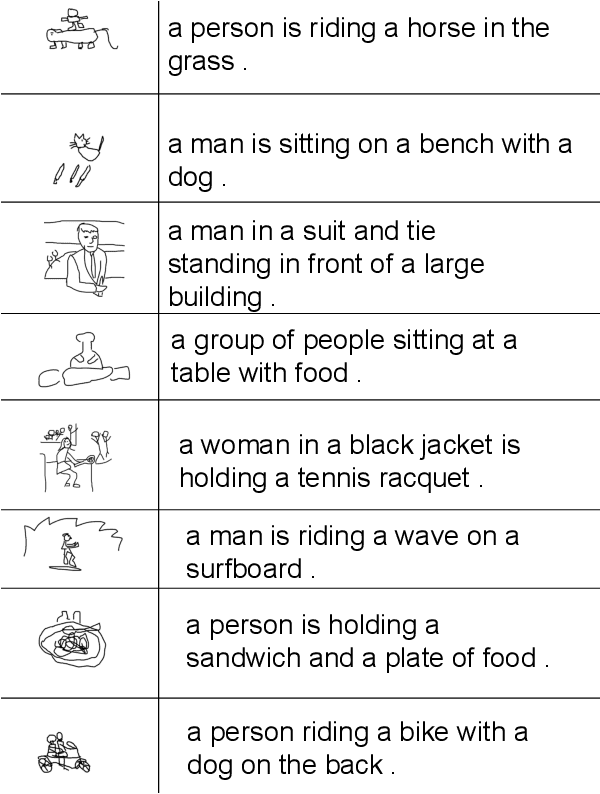

We address the problem of retrieving images with both a sketch and a text query. We present TASK-former (Text And SKetch transformer), an end-to-end trainable model for image retrieval using a text description and a sketch as input. We argue that both input modalities complement each other in a manner that cannot be achieved easily by either one alone. TASK-former follows the late-fusion dual-encoder approach, similar to CLIP, which allows efficient and scalable retrieval since the retrieval set can be indexed independently of the queries. We empirically demonstrate that using an input sketch (even a poorly drawn one) in addition to text considerably increases retrieval recall compared to traditional text-based image retrieval. To evaluate our approach, we collect 5,000 hand-drawn sketches for images in the test set of the COCO dataset. The collected sketches are available a https://janesjanes.github.io/tsbir/.
Discussion of `Multiscale Fisher's Independence Test for Multivariate Dependence'
Jun 22, 2022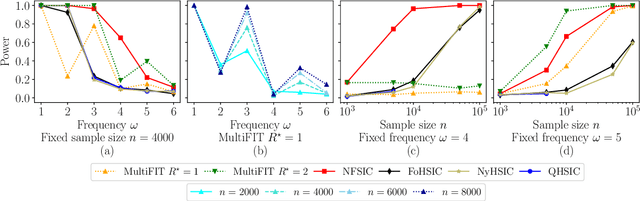
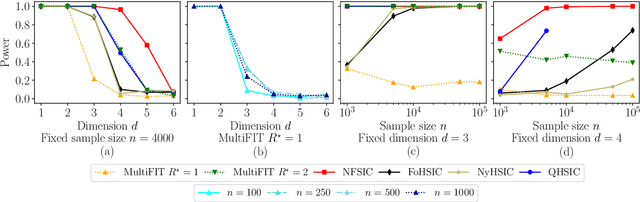
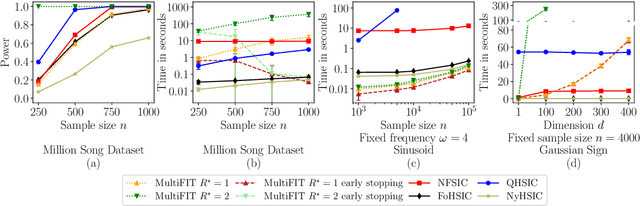
We discuss how MultiFIT, the Multiscale Fisher's Independence Test for Multivariate Dependence proposed by Gorsky and Ma (2022), compares to existing linear-time kernel tests based on the Hilbert-Schmidt independence criterion (HSIC). We highlight the fact that the levels of the kernel tests at any finite sample size can be controlled exactly, as it is the case with the level of MultiFIT. In our experiments, we observe some of the performance limitations of MultiFIT in terms of test power.
ELM: Embedding and Logit Margins for Long-Tail Learning
Apr 27, 2022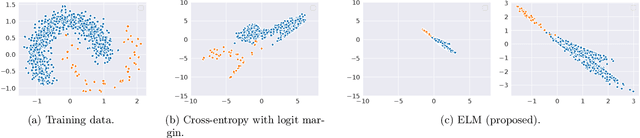
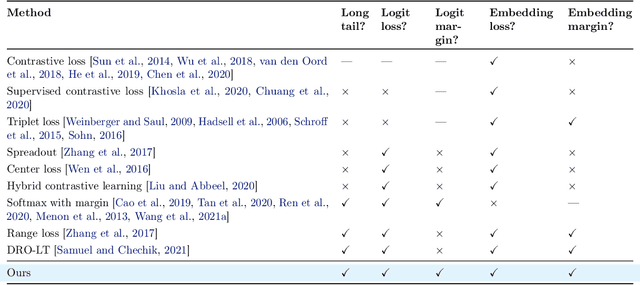
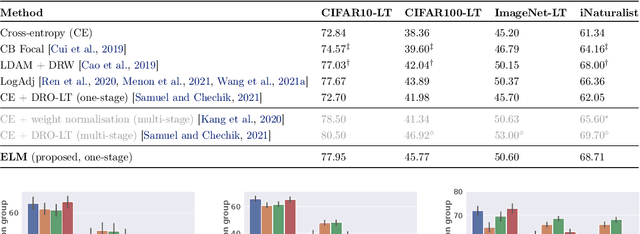
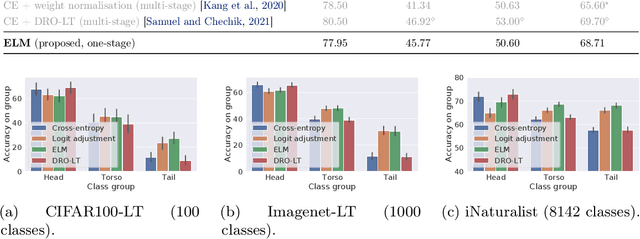
Long-tail learning is the problem of learning under skewed label distributions, which pose a challenge for standard learners. Several recent approaches for the problem have proposed enforcing a suitable margin in logit space. Such techniques are intuitive analogues of the guiding principle behind SVMs, and are equally applicable to linear models and neural models. However, when applied to neural models, such techniques do not explicitly control the geometry of the learned embeddings. This can be potentially sub-optimal, since embeddings for tail classes may be diffuse, resulting in poor generalization for these classes. We present Embedding and Logit Margins (ELM), a unified approach to enforce margins in logit space, and regularize the distribution of embeddings. This connects losses for long-tail learning to proposals in the literature on metric embedding, and contrastive learning. We theoretically show that minimising the proposed ELM objective helps reduce the generalisation gap. The ELM method is shown to perform well empirically, and results in tighter tail class embeddings.
HD-cos Networks: Efficient Neural Architectures for Secure Multi-Party Computation
Oct 28, 2021
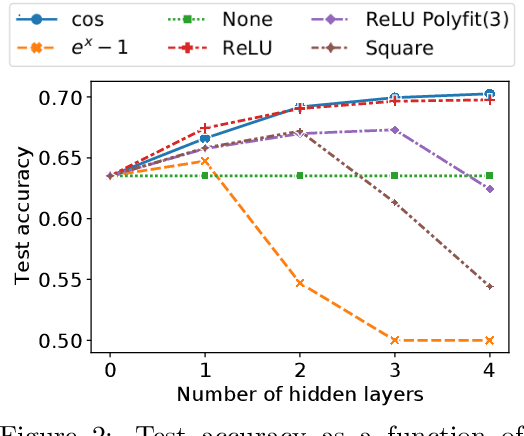
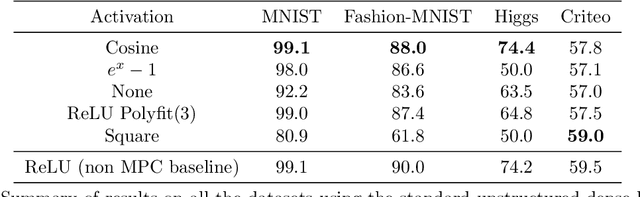

Multi-party computation (MPC) is a branch of cryptography where multiple non-colluding parties execute a well designed protocol to securely compute a function. With the non-colluding party assumption, MPC has a cryptographic guarantee that the parties will not learn sensitive information from the computation process, making it an appealing framework for applications that involve privacy-sensitive user data. In this paper, we study training and inference of neural networks under the MPC setup. This is challenging because the elementary operations of neural networks such as the ReLU activation function and matrix-vector multiplications are very expensive to compute due to the added multi-party communication overhead. To address this, we propose the HD-cos network that uses 1) cosine as activation function, 2) the Hadamard-Diagonal transformation to replace the unstructured linear transformations. We show that both of the approaches enjoy strong theoretical motivations and efficient computation under the MPC setup. We demonstrate on multiple public datasets that HD-cos matches the quality of the more expensive baselines.
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021
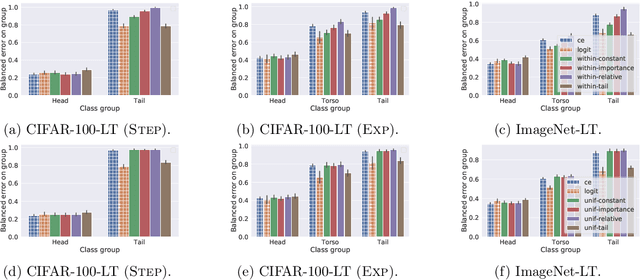

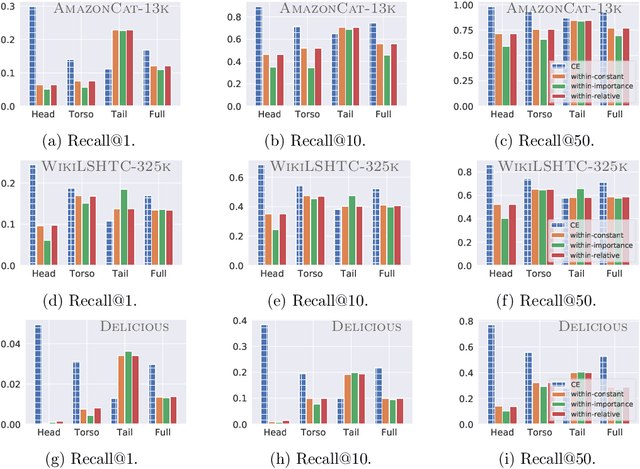
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.