 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMudit Verma
Hindsight PRIORs for Reward Learning from Human Preferences
Apr 12, 2024
Preference based Reinforcement Learning (PbRL) removes the need to hand specify a reward function by learning a reward from preference feedback over policy behaviors. Current approaches to PbRL do not address the credit assignment problem inherent in determining which parts of a behavior most contributed to a preference, which result in data intensive approaches and subpar reward functions. We address such limitations by introducing a credit assignment strategy (Hindsight PRIOR) that uses a world model to approximate state importance within a trajectory and then guides rewards to be proportional to state importance through an auxiliary predicted return redistribution objective. Incorporating state importance into reward learning improves the speed of policy learning, overall policy performance, and reward recovery on both locomotion and manipulation tasks. For example, Hindsight PRIOR recovers on average significantly (p<0.05) more reward on MetaWorld (20%) and DMC (15%). The performance gains and our ablations demonstrate the benefits even a simple credit assignment strategy can have on reward learning and that state importance in forward dynamics prediction is a strong proxy for a state's contribution to a preference decision. Code repository can be found at https://github.com/apple/ml-rlhf-hindsight-prior.
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
Theory of Mind abilities of Large Language Models in Human-Robot Interaction : An Illusion?
Jan 17, 2024Large Language Models have shown exceptional generative abilities in various natural language and generation tasks. However, possible anthropomorphization and leniency towards failure cases have propelled discussions on emergent abilities of Large Language Models especially on Theory of Mind (ToM) abilities in Large Language Models. While several false-belief tests exists to verify the ability to infer and maintain mental models of another entity, we study a special application of ToM abilities that has higher stakes and possibly irreversible consequences : Human Robot Interaction. In this work, we explore the task of Perceived Behavior Recognition, where a robot employs a Large Language Model (LLM) to assess the robot's generated behavior in a manner similar to human observer. We focus on four behavior types, namely - explicable, legible, predictable, and obfuscatory behavior which have been extensively used to synthesize interpretable robot behaviors. The LLMs goal is, therefore to be a human proxy to the agent, and to answer how a certain agent behavior would be perceived by the human in the loop, for example "Given a robot's behavior X, would the human observer find it explicable?". We conduct a human subject study to verify that the users are able to correctly answer such a question in the curated situations (robot setting and plan) across five domains. A first analysis of the belief test yields extremely positive results inflating ones expectations of LLMs possessing ToM abilities. We then propose and perform a suite of perturbation tests which breaks this illusion, i.e. Inconsistent Belief, Uninformative Context and Conviction Test. We conclude that, the high score of LLMs on vanilla prompts showcases its potential use in HRI settings, however to possess ToM demands invariance to trivial or irrelevant perturbations in the context which LLMs lack.
Benchmarking Multi-Agent Preference-based Reinforcement Learning for Human-AI Teaming
Dec 21, 2023Preference-based Reinforcement Learning (PbRL) is an active area of research, and has made significant strides in single-agent actor and in observer human-in-the-loop scenarios. However, its application within the co-operative multi-agent RL frameworks, where humans actively participate and express preferences for agent behavior, remains largely uncharted. We consider a two-agent (Human-AI) cooperative setup where both the agents are rewarded according to human's reward function for the team. However, the agent does not have access to it, and instead, utilizes preference-based queries to elicit its objectives and human's preferences for the robot in the human-robot team. We introduce the notion of Human-Flexibility, i.e. whether the human partner is amenable to multiple team strategies, with a special case being Specified Orchestration where the human has a single team policy in mind (most constrained case). We propose a suite of domains to study PbRL for Human-AI cooperative setup which explicitly require forced cooperation. Adapting state-of-the-art single-agent PbRL algorithms to our two-agent setting, we conduct a comprehensive benchmarking study across our domain suite. Our findings highlight the challenges associated with high degree of Human-Flexibility and the limited access to the human's envisioned policy in PbRL for Human-AI cooperation. Notably, we observe that PbRL algorithms exhibit effective performance exclusively in the case of Specified Orchestration which can be seen as an upper bound PbRL performance for future research.
Methods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023
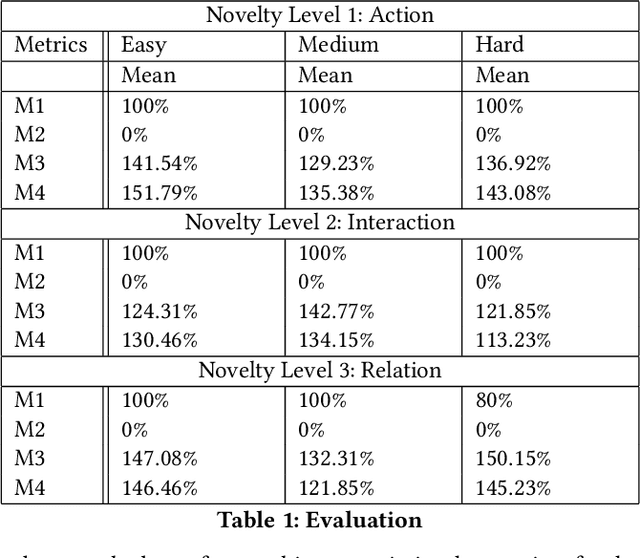
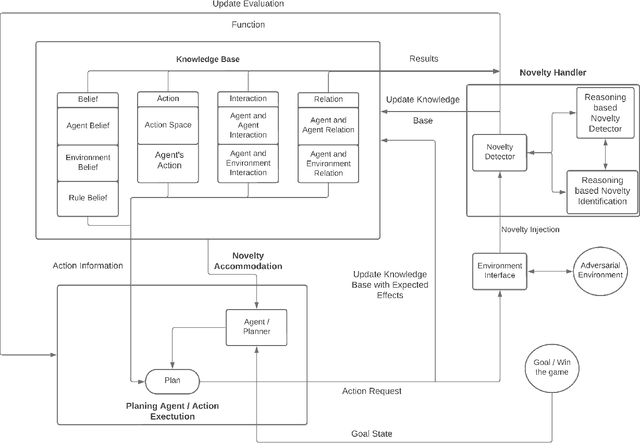
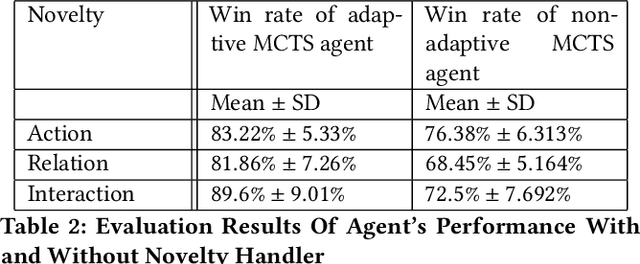
Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.
Exploiting Unlabeled Data for Feedback Efficient Human Preference based Reinforcement Learning
Feb 17, 2023

Preference Based Reinforcement Learning has shown much promise for utilizing human binary feedback on queried trajectory pairs to recover the underlying reward model of the Human in the Loop (HiL). While works have attempted to better utilize the queries made to the human, in this work we make two observations about the unlabeled trajectories collected by the agent and propose two corresponding loss functions that ensure participation of unlabeled trajectories in the reward learning process, and structure the embedding space of the reward model such that it reflects the structure of state space with respect to action distances. We validate the proposed method on one locomotion domain and one robotic manipulation task and compare with the state-of-the-art baseline PEBBLE. We further present an ablation of the proposed loss components across both the domains and find that not only each of the loss components perform better than the baseline, but the synergic combination of the two has much better reward recovery and human feedback sample efficiency.
A State Augmentation based approach to Reinforcement Learning from Human Preferences
Feb 17, 2023


Reinforcement Learning has suffered from poor reward specification, and issues for reward hacking even in simple enough domains. Preference Based Reinforcement Learning attempts to solve the issue by utilizing binary feedbacks on queried trajectory pairs by a human in the loop indicating their preferences about the agent's behavior to learn a reward model. In this work, we present a state augmentation technique that allows the agent's reward model to be robust and follow an invariance consistency that significantly improved performance, i.e. the reward recovery and subsequent return computed using the learned policy over our baseline PEBBLE. We validate our method on three domains, Mountain Car, a locomotion task of Quadruped-Walk, and a robotic manipulation task of Sweep-Into, and find that using the proposed augmentation the agent not only benefits in the overall performance but does so, quite early in the agent's training phase.
Data Driven Reward Initialization for Preference based Reinforcement Learning
Feb 17, 2023



Preference-based Reinforcement Learning (PbRL) methods utilize binary feedback from the human in the loop (HiL) over queried trajectory pairs to learn a reward model in an attempt to approximate the human's underlying reward function capturing their preferences. In this work, we investigate the issue of a high degree of variability in the initialized reward models which are sensitive to random seeds of the experiment. This further compounds the issue of degenerate reward functions PbRL methods already suffer from. We propose a data-driven reward initialization method that does not add any additional cost to the human in the loop and negligible cost to the PbRL agent and show that doing so ensures that the predicted rewards of the initialized reward model are uniform in the state space and this reduces the variability in the performance of the method across multiple runs and is shown to improve the overall performance compared to other initialization methods.
Towards customizable reinforcement learning agents: Enabling preference specification through online vocabulary expansion
Oct 27, 2022



There is a growing interest in developing automated agents that can work alongside humans. In addition to completing the assigned task, such an agent will undoubtedly be expected to behave in a manner that is preferred by the human. This requires the human to communicate their preferences to the agent. To achieve this, the current approaches either require the users to specify the reward function or the preference is interactively learned from queries that ask the user to compare trajectories. The former approach can be challenging if the internal representation used by the agent is inscrutable to the human while the latter is unnecessarily cumbersome for the user if their preference can be specified more easily in symbolic terms. In this work, we propose PRESCA (PREference Specification through Concept Acquisition), a system that allows users to specify their preferences in terms of concepts that they understand. PRESCA maintains a set of such concepts in a shared vocabulary. If the relevant concept is not in the shared vocabulary, then it is learned. To make learning a new concept more efficient, PRESCA leverages causal associations between the target concept and concepts that are already known. Additionally, the effort of learning the new concept is amortized by adding the concept to the shared vocabulary for supporting preference specification in future interactions. We evaluate PRESCA by using it on a Minecraft environment and show that it can be effectively used to make the agent align with the user's preference.
Symbol Guided Hindsight Priors for Reward Learning from Human Preferences
Oct 19, 2022

Specifying rewards for reinforcement learned (RL) agents is challenging. Preference-based RL (PbRL) mitigates these challenges by inferring a reward from feedback over sets of trajectories. However, the effectiveness of PbRL is limited by the amount of feedback needed to reliably recover the structure of the target reward. We present the PRIor Over Rewards (PRIOR) framework, which incorporates priors about the structure of the reward function and the preference feedback into the reward learning process. Imposing these priors as soft constraints on the reward learning objective reduces the amount of feedback required by half and improves overall reward recovery. Additionally, we demonstrate that using an abstract state space for the computation of the priors further improves the reward learning and the agent's performance.