 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuhammad Usman
Blue and Green-Mode Energy-Efficient Chemiresistive Sensor Array Realized by Rapid Ensemble Learning
Mar 03, 2024
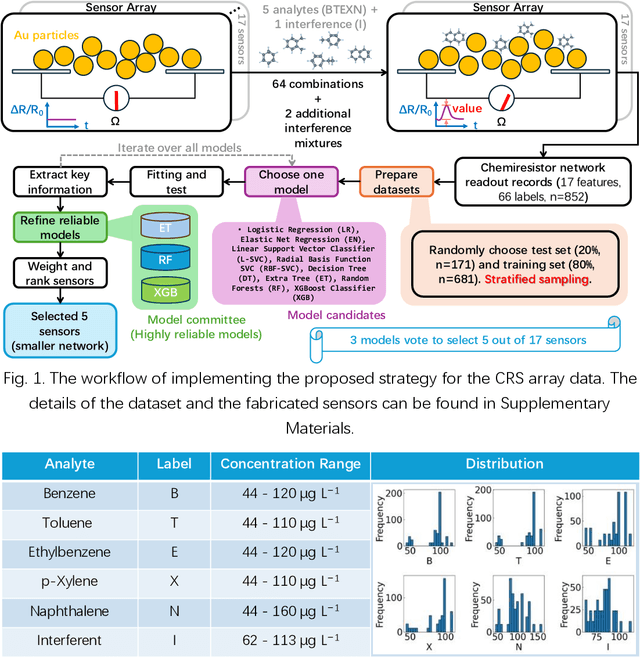
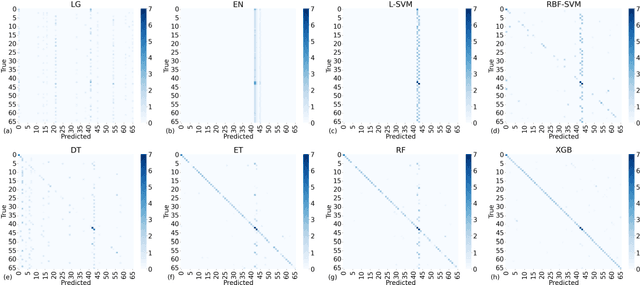
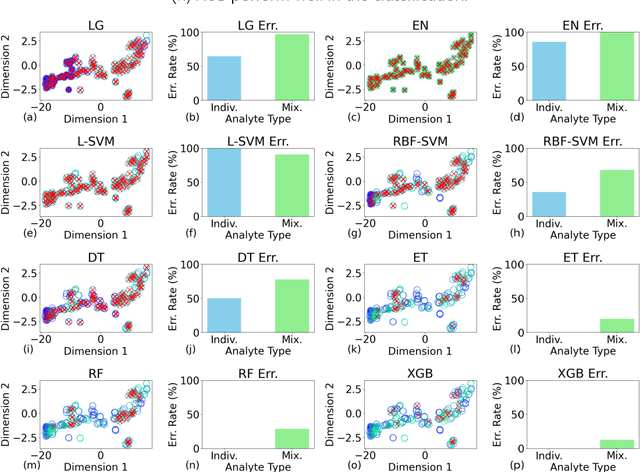
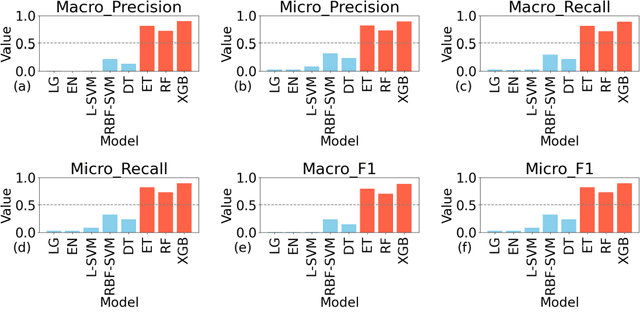
The rapid advancement of Internet of Things (IoT) necessitates the development of optimized Chemiresistive Sensor (CRS) arrays that are both energy-efficient and capable. This study introduces a novel optimization strategy that employs a rapid ensemble learning-based model committee approach to achieve these goals. Utilizing machine learning models such as Elastic Net Regression, Random Forests, and XGBoost, among others, the strategy identifies the most impactful sensors in a CRS array for accurate classification: A weighted voting mechanism is introduced to aggregate the models' opinions in sensor selection, thereby setting up wo distinct working modes, termed "Blue" and "Green". The Blue mode operates with all sensors for maximum detection capability, while the Green mode selectively activates only key sensors, significantly reducing energy consumption without compromising detection accuracy. The strategy is validated through theoretical calculations and Monte Carlo simulations, demonstrating its effectiveness and accuracy. The proposed optimization strategy not only elevates the detection capability of CRS arrays but also brings it closer to theoretical limits, promising significant implications for the development of low-cost, easily fabricable next-generation IoT sensor terminals.
Radio Signal Classification by Adversarially Robust Quantum Machine Learning
Dec 13, 2023Radio signal classification plays a pivotal role in identifying the modulation scheme used in received radio signals, which is essential for demodulation and proper interpretation of the transmitted information. Researchers have underscored the high susceptibility of ML algorithms for radio signal classification to adversarial attacks. Such vulnerability could result in severe consequences, including misinterpretation of critical messages, interception of classified information, or disruption of communication channels. Recent advancements in quantum computing have revolutionized theories and implementations of computation, bringing the unprecedented development of Quantum Machine Learning (QML). It is shown that quantum variational classifiers (QVCs) provide notably enhanced robustness against classical adversarial attacks in image classification. However, no research has yet explored whether QML can similarly mitigate adversarial threats in the context of radio signal classification. This work applies QVCs to radio signal classification and studies their robustness to various adversarial attacks. We also propose the novel application of the approximate amplitude encoding (AAE) technique to encode radio signal data efficiently. Our extensive simulation results present that attacks generated on QVCs transfer well to CNN models, indicating that these adversarial examples can fool neural networks that they are not explicitly designed to attack. However, the converse is not true. QVCs primarily resist the attacks generated on CNNs. Overall, with comprehensive simulations, our results shed new light on the growing field of QML by bridging knowledge gaps in QAML in radio signal classification and uncovering the advantages of applying QML methods in practical applications.
Clustering by Contour coreset and variational quantum eigensolver
Dec 06, 2023Recent work has proposed solving the k-means clustering problem on quantum computers via the Quantum Approximate Optimization Algorithm (QAOA) and coreset techniques. Although the current method demonstrates the possibility of quantum k-means clustering, it does not ensure high accuracy and consistency across a wide range of datasets. The existing coreset techniques are designed for classical algorithms and there has been no quantum-tailored coreset technique which is designed to boost the accuracy of quantum algorithms. In this work, we propose solving the k-means clustering problem with the variational quantum eigensolver (VQE) and a customised coreset method, the Contour coreset, which has been formulated with specific focus on quantum algorithms. Extensive simulations with synthetic and real-life data demonstrated that our VQE+Contour Coreset approach outperforms existing QAOA+Coreset k-means clustering approaches with higher accuracy and lower standard deviation. Our work has shown that quantum tailored coreset techniques has the potential to significantly boost the performance of quantum algorithms when compared to using generic off-the-shelf coreset techniques.
The Importance of Multimodal Emotion Conditioning and Affect Consistency for Embodied Conversational Agents
Sep 26, 2023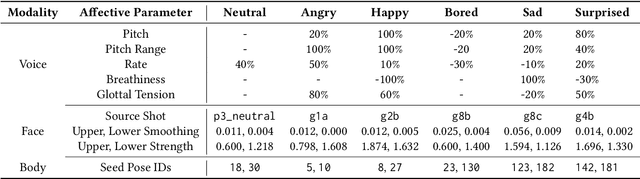


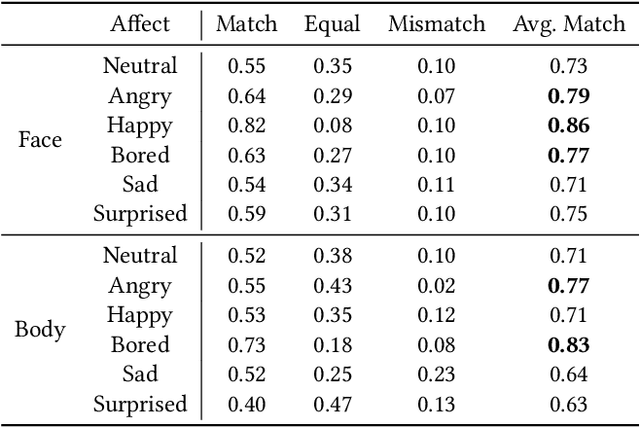
Previous studies regarding the perception of emotions for embodied virtual agents have shown the effectiveness of using virtual characters in conveying emotions through interactions with humans. However, creating an autonomous embodied conversational agent with expressive behaviors presents two major challenges. The first challenge is the difficulty of synthesizing the conversational behaviors for each modality that are as expressive as real human behaviors. The second challenge is that the affects are modeled independently, which makes it difficult to generate multimodal responses with consistent emotions across all modalities. In this work, we propose a conceptual framework, ACTOR (Affect-Consistent mulTimodal behaviOR generation), that aims to increase the perception of affects by generating multimodal behaviors conditioned on a consistent driving affect. We have conducted a user study with 199 participants to assess how the average person judges the affects perceived from multimodal behaviors that are consistent and inconsistent with respect to a driving affect. The result shows that among all model conditions, our affect-consistent framework receives the highest Likert scores for the perception of driving affects. Our statistical analysis suggests that making a modality affect-inconsistent significantly decreases the perception of driving affects. We also observe that multimodal behaviors conditioned on consistent affects are more expressive compared to behaviors with inconsistent affects. Therefore, we conclude that multimodal emotion conditioning and affect consistency are vital to enhancing the perception of affects for embodied conversational agents.
DSLOT-NN: Digit-Serial Left-to-Right Neural Network Accelerator
Sep 22, 2023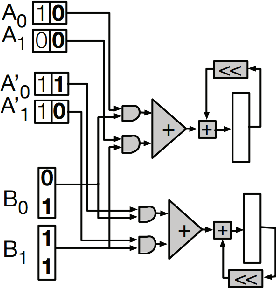
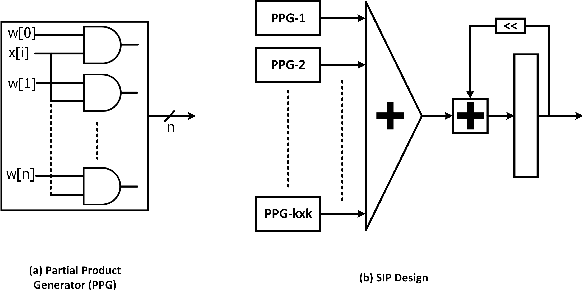
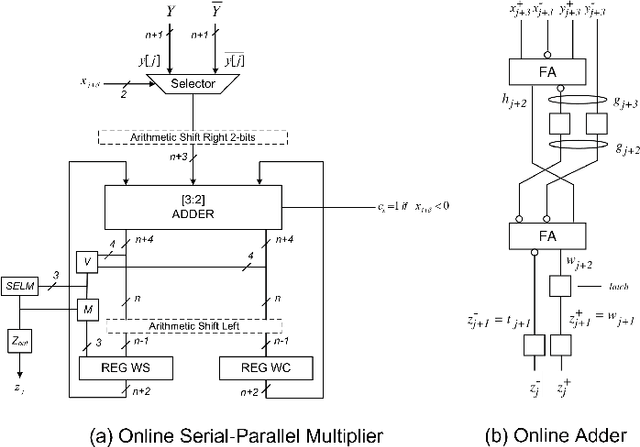
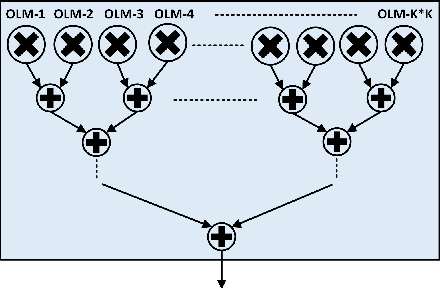
We propose a Digit-Serial Left-tO-righT (DSLOT) arithmetic based processing technique called DSLOT-NN with aim to accelerate inference of the convolution operation in the deep neural networks (DNNs). The proposed work has the ability to assess and terminate the ineffective convolutions which results in massive power and energy savings. The processing engine is comprised of low-latency most-significant-digit-first (MSDF) (also called online) multipliers and adders that processes data from left-to-right, allowing the execution of subsequent operations in digit-pipelined manner. Use of online operators eliminates the need for the development of complex mechanism of identifying the negative activation, as the output with highest weight value is generated first, and the sign of the result can be identified as soon as first non-zero digit is generated. The precision of the online operators can be tuned at run-time, making them extremely useful in situations where accuracy can be compromised for power and energy savings. The proposed design has been implemented on Xilinx Virtex-7 FPGA and is compared with state-of-the-art Stripes on various performance metrics. The results show the proposed design presents power savings, has shorter cycle time, and approximately 50% higher OPS per watt.
A Comprehensive Overview of Large Language Models
Jul 12, 2023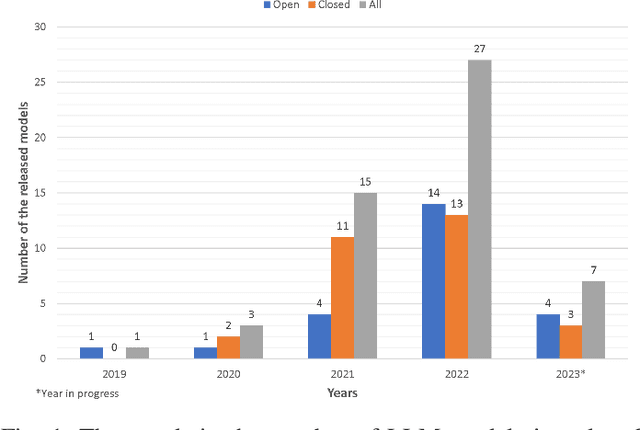
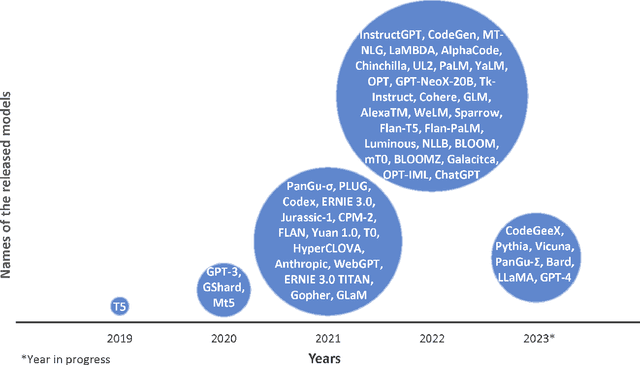
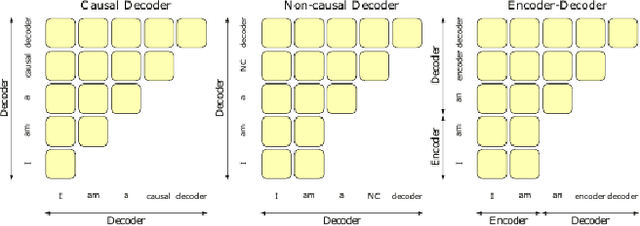

Large Language Models (LLMs) have shown excellent generalization capabilities that have led to the development of numerous models. These models propose various new architectures, tweaking existing architectures with refined training strategies, increasing context length, using high-quality training data, and increasing training time to outperform baselines. Analyzing new developments is crucial for identifying changes that enhance training stability and improve generalization in LLMs. This survey paper comprehensively analyses the LLMs architectures and their categorization, training strategies, training datasets, and performance evaluations and discusses future research directions. Moreover, the paper also discusses the basic building blocks and concepts behind LLMs, followed by a complete overview of LLMs, including their important features and functions. Finally, the paper summarizes significant findings from LLM research and consolidates essential architectural and training strategies for developing advanced LLMs. Given the continuous advancements in LLMs, we intend to regularly update this paper by incorporating new sections and featuring the latest LLM models.
Towards quantum enhanced adversarial robustness in machine learning
Jun 22, 2023Machine learning algorithms are powerful tools for data driven tasks such as image classification and feature detection, however their vulnerability to adversarial examples - input samples manipulated to fool the algorithm - remains a serious challenge. The integration of machine learning with quantum computing has the potential to yield tools offering not only better accuracy and computational efficiency, but also superior robustness against adversarial attacks. Indeed, recent work has employed quantum mechanical phenomena to defend against adversarial attacks, spurring the rapid development of the field of quantum adversarial machine learning (QAML) and potentially yielding a new source of quantum advantage. Despite promising early results, there remain challenges towards building robust real-world QAML tools. In this review we discuss recent progress in QAML and identify key challenges. We also suggest future research directions which could determine the route to practicality for QAML approaches as quantum computing hardware scales up and noise levels are reduced.
* 10 Pages, 4 Figures
Automating Microservices Test Failure Analysis using Kubernetes Cluster Logs
Jun 13, 2023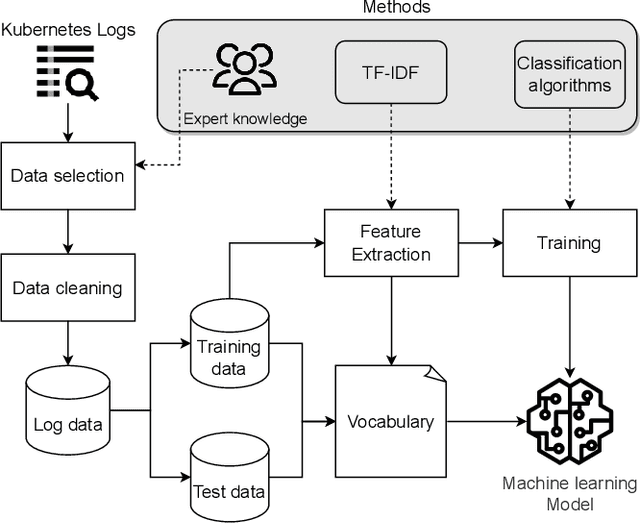
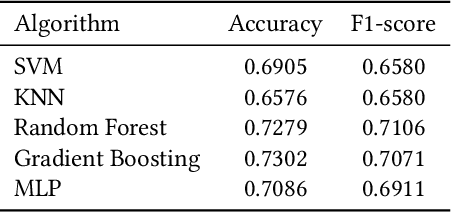
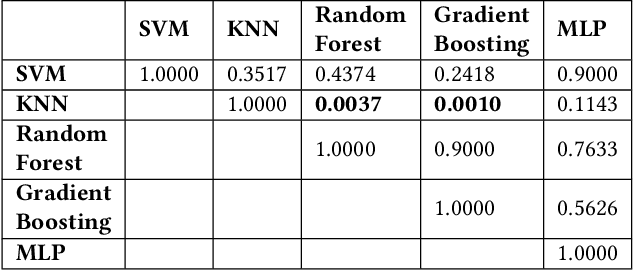
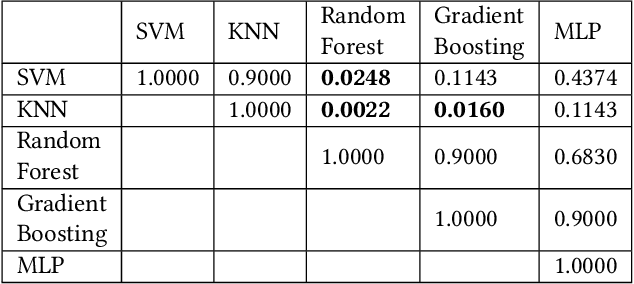
Kubernetes is a free, open-source container orchestration system for deploying and managing Docker containers that host microservices. Kubernetes cluster logs help in determining the reason for the failure. However, as systems become more complex, identifying failure reasons manually becomes more difficult and time-consuming. This study aims to identify effective and efficient classification algorithms to automatically determine the failure reason. We compare five classification algorithms, Support Vector Machines, K-Nearest Neighbors, Random Forest, Gradient Boosting Classifier, and Multilayer Perceptron. Our results indicate that Random Forest produces good accuracy while requiring fewer computational resources than other algorithms.
LDMRes-Net: Enabling Real-Time Disease Monitoring through Efficient Image Segmentation
Jun 09, 2023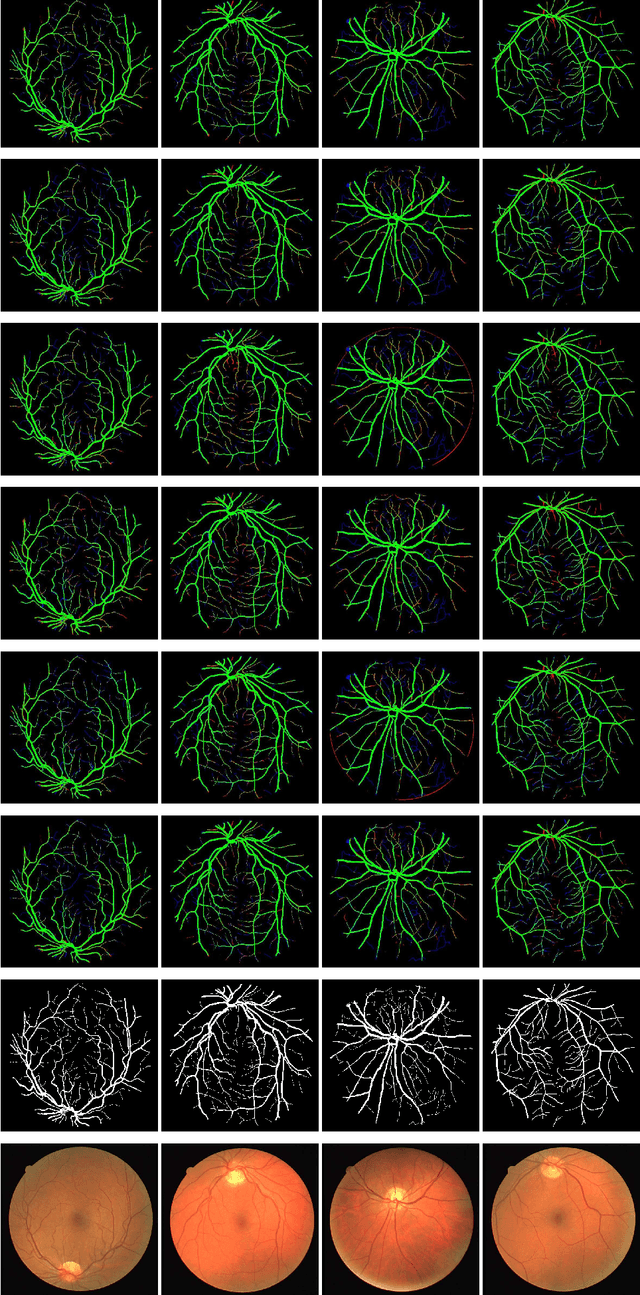
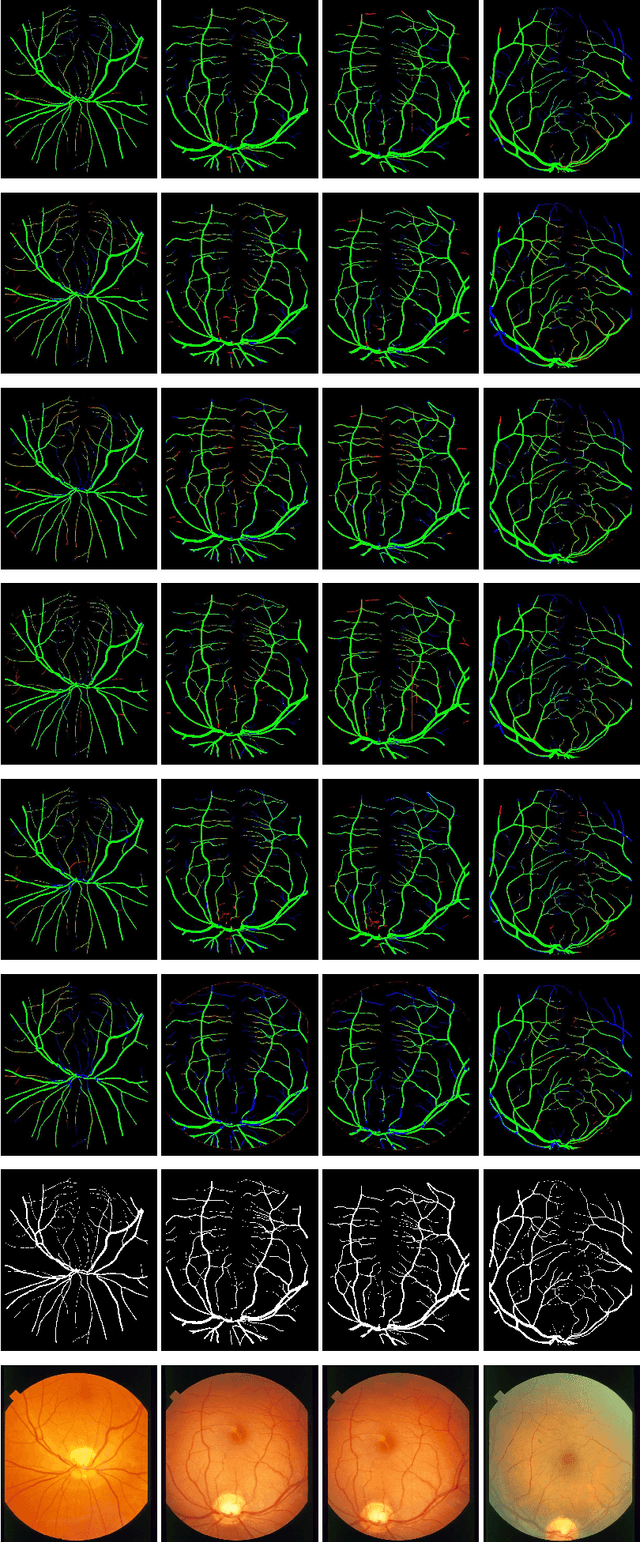

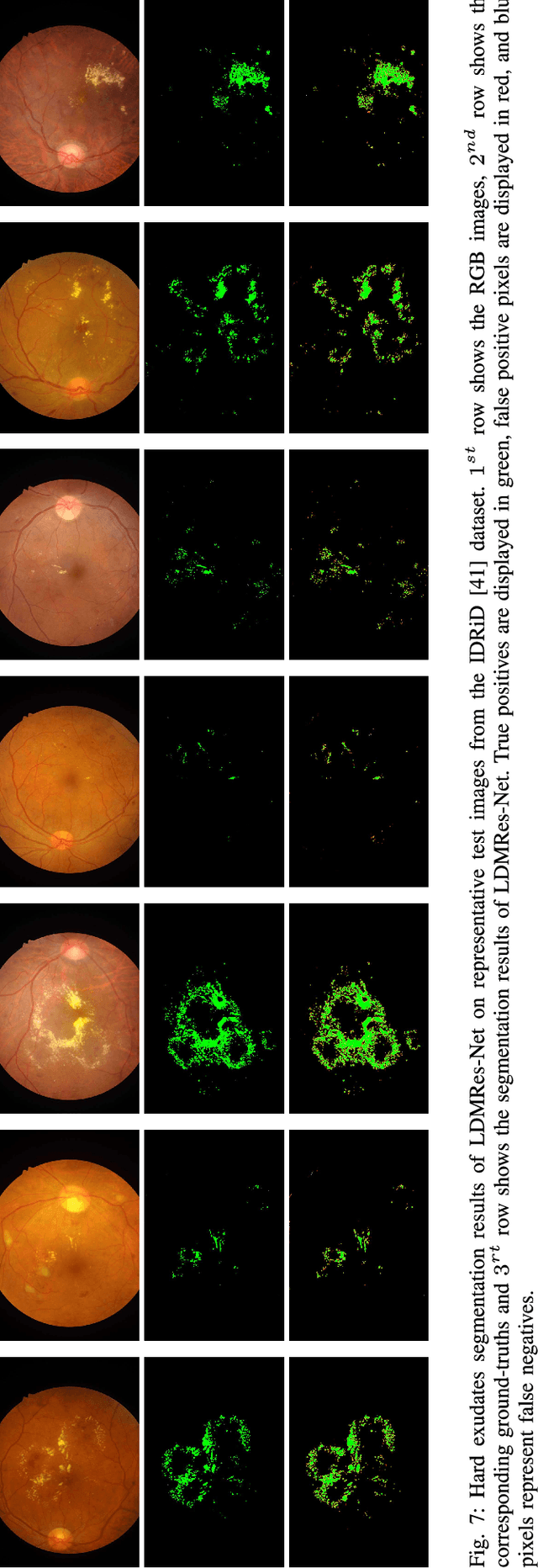
Retinal eye diseases can lead to irreversible vision loss in both eyes if not diagnosed and treated earlier. Owing to the complexities of retinal diseases, the likelihood that retinal images would contain two or more abnormalities is very high. The current deep learning algorithms used for segmenting retinal images with multiple labels and features suffer from inadequate detection accuracy and a lack of generalizability. In this paper, we propose a lightweight and efficient network, featuring dual multi-residual connections to enhance segmentation performance while minimizing computational cost. The proposed network is evaluated on eight publicly available retinal image datasets and achieved promising segmentation results, which demonstrate the effectiveness of the proposed network for retinal image analysis tasks. The proposed network's lightweight and efficient design makes it a promising candidate for real-time retinal image analysis applications.
Low-Latency Online Multiplier with Reduced Activities and Minimized Interconnect for Inner Product Arrays
Apr 06, 2023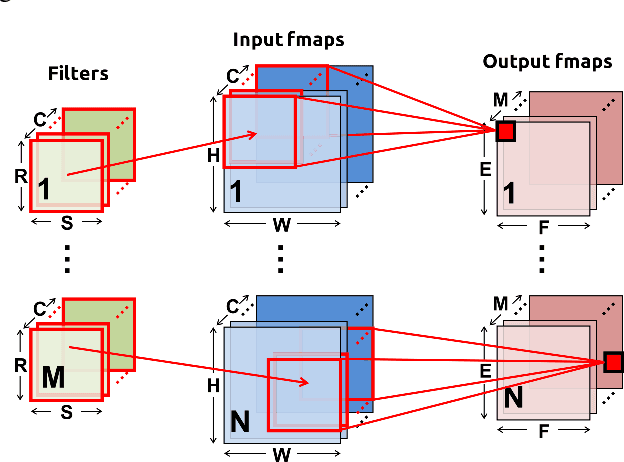
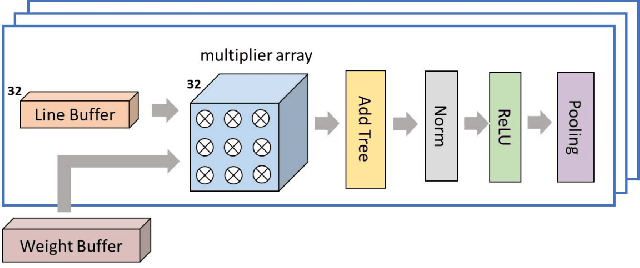
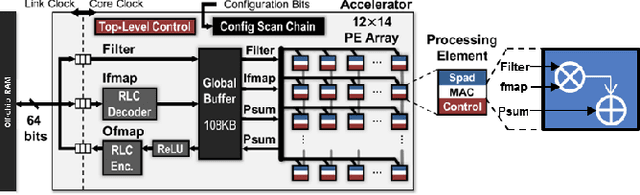
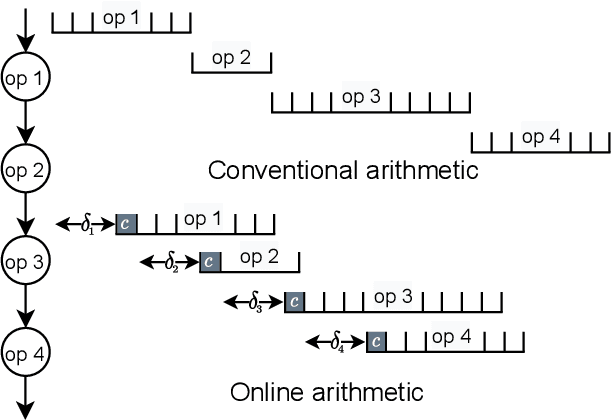
Multiplication is indispensable and is one of the core operations in many modern applications including signal processing and neural networks. Conventional right-to-left (RL) multiplier extensively contributes to the power consumption, area utilization and critical path delay in such applications. This paper proposes a low latency multiplier based on online or left-to-right (LR) arithmetic which can increase throughput and reduce latency by digit-level pipelining. Online arithmetic enables overlapping successive operations regardless of data dependency because of the most significant digit first mode of operation. To produce most significant digit first, it uses redundant number system and we can have a carry-free addition, therefore, the delay of the arithmetic operation is independent of operand bit width. The operations are performed digit by digit serially from left to right which allows gradual increase in the slice activities making it suitable for implementation on reconfigurable devices. Serial nature of the online algorithm and gradual increment/decrement of active slices minimize the interconnects and signal activities resulting in overall reduction of area and power consumption. We present online multipliers with; both inputs in serial, and one in serial and one in parallel. Pipelined and non-pipelined designs of the proposed multipliers have been synthesized with GSCL 45nm technology on Synopsys Design Compiler. Thorough comparative analysis has been performed using widely used performance metrics. The results show that the proposed online multipliers outperform the RL multipliers.