 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShahzaib Iqbal
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023




Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
Feature Enhancer Segmentation Network (FES-Net) for Vessel Segmentation
Sep 07, 2023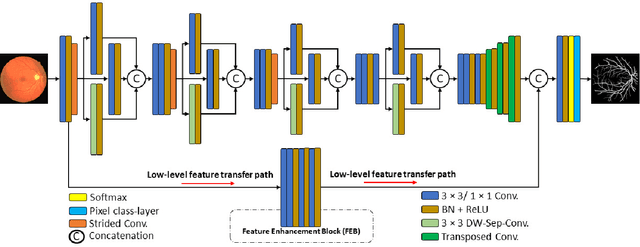
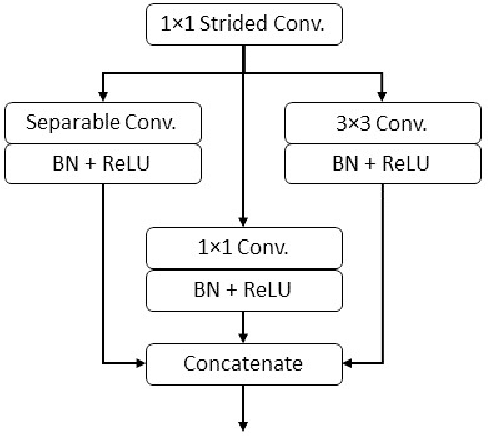
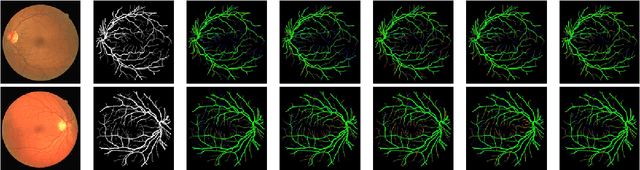
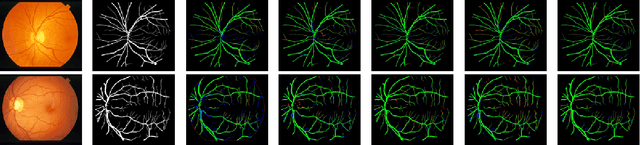
Diseases such as diabetic retinopathy and age-related macular degeneration pose a significant risk to vision, highlighting the importance of precise segmentation of retinal vessels for the tracking and diagnosis of progression. However, existing vessel segmentation methods that heavily rely on encoder-decoder structures struggle to capture contextual information about retinal vessel configurations, leading to challenges in reconciling semantic disparities between encoder and decoder features. To address this, we propose a novel feature enhancement segmentation network (FES-Net) that achieves accurate pixel-wise segmentation without requiring additional image enhancement steps. FES-Net directly processes the input image and utilizes four prompt convolutional blocks (PCBs) during downsampling, complemented by a shallow upsampling approach to generate a binary mask for each class. We evaluate the performance of FES-Net on four publicly available state-of-the-art datasets: DRIVE, STARE, CHASE, and HRF. The evaluation results clearly demonstrate the superior performance of FES-Net compared to other competitive approaches documented in the existing literature.
LDMRes-Net: Enabling Real-Time Disease Monitoring through Efficient Image Segmentation
Jun 09, 2023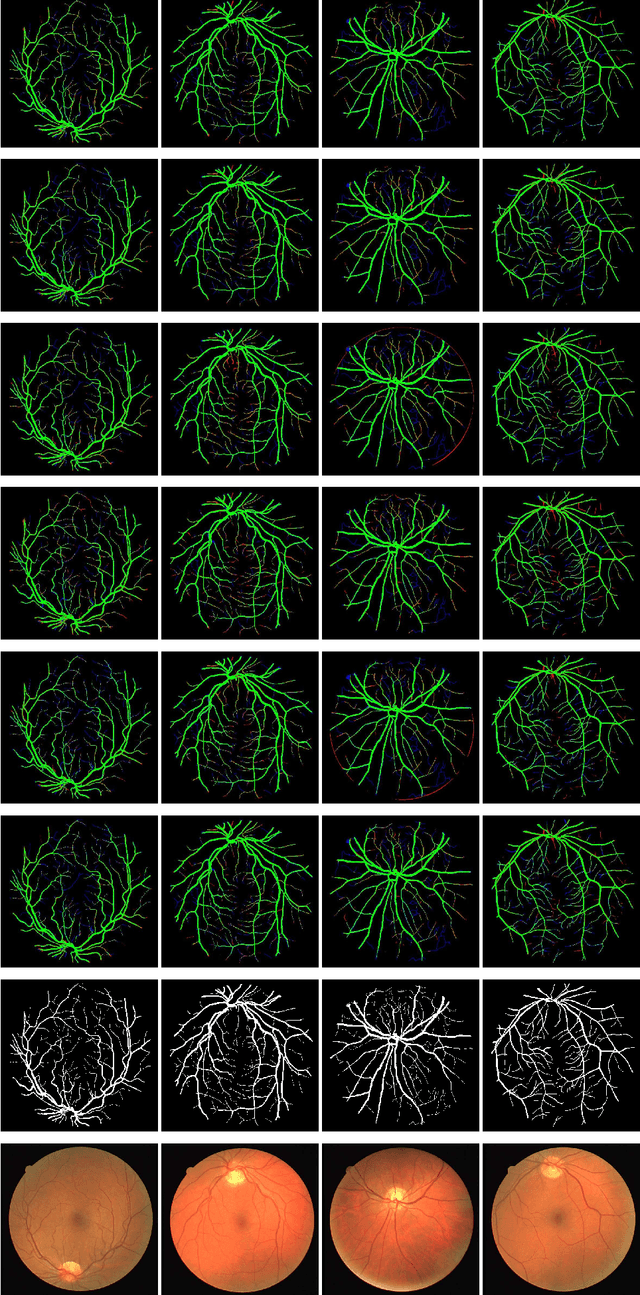
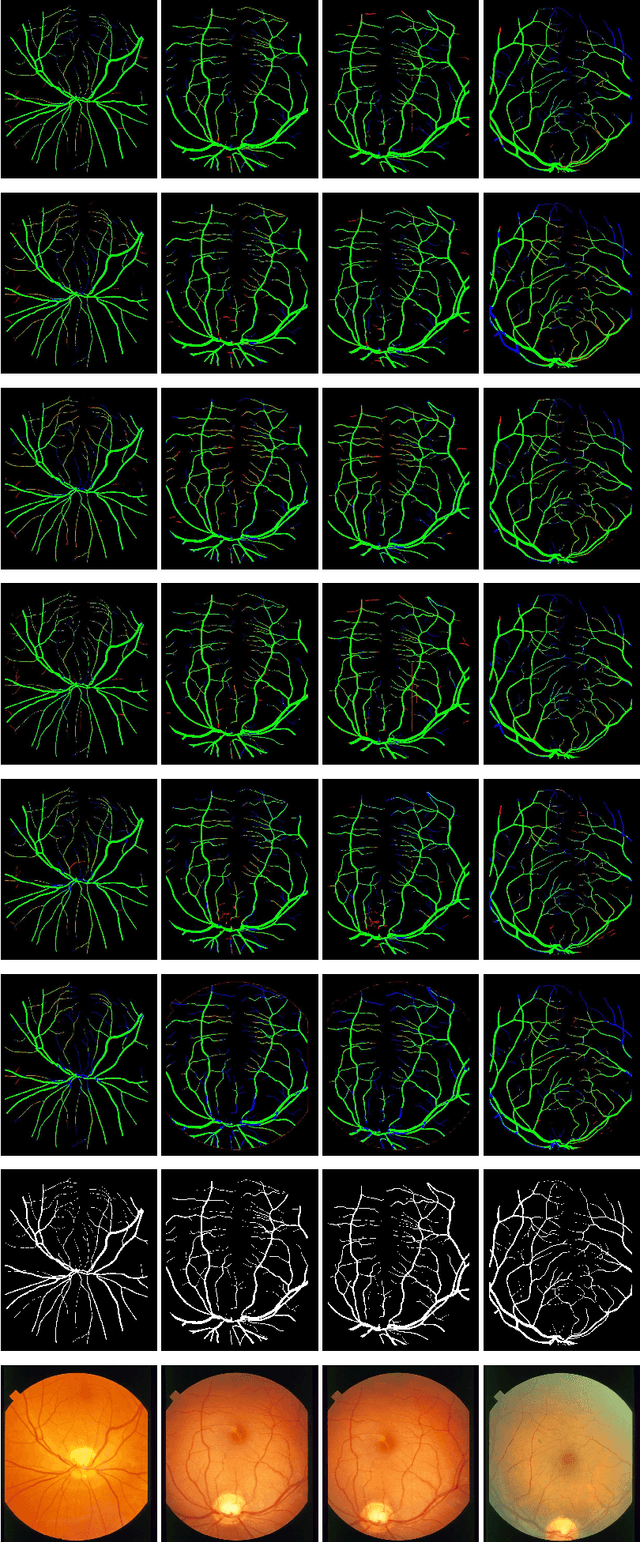

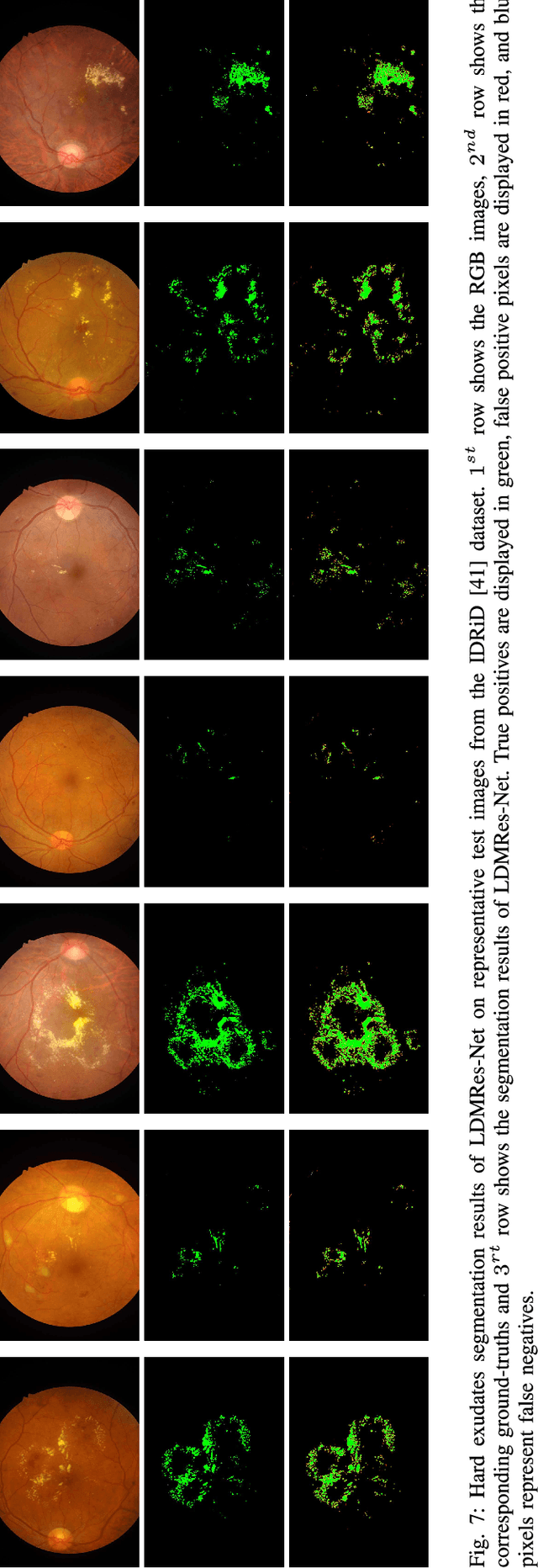
Retinal eye diseases can lead to irreversible vision loss in both eyes if not diagnosed and treated earlier. Owing to the complexities of retinal diseases, the likelihood that retinal images would contain two or more abnormalities is very high. The current deep learning algorithms used for segmenting retinal images with multiple labels and features suffer from inadequate detection accuracy and a lack of generalizability. In this paper, we propose a lightweight and efficient network, featuring dual multi-residual connections to enhance segmentation performance while minimizing computational cost. The proposed network is evaluated on eight publicly available retinal image datasets and achieved promising segmentation results, which demonstrate the effectiveness of the proposed network for retinal image analysis tasks. The proposed network's lightweight and efficient design makes it a promising candidate for real-time retinal image analysis applications.