 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMurali Annavaram
Differentially Private Next-Token Prediction of Large Language Models
Apr 01, 2024
Ensuring the privacy of Large Language Models (LLMs) is becoming increasingly important. The most widely adopted technique to accomplish this is DP-SGD, which trains a model to guarantee Differential Privacy (DP). However, DP-SGD overestimates an adversary's capabilities in having white box access to the model and, as a result, causes longer training times and larger memory usage than SGD. On the other hand, commercial LLM deployments are predominantly cloud-based; hence, adversarial access to LLMs is black-box. Motivated by these observations, we present Private Mixing of Ensemble Distributions (PMixED): a private prediction protocol for next-token prediction that utilizes the inherent stochasticity of next-token sampling and a public model to achieve Differential Privacy. We formalize this by introducing RD-mollifers which project each of the model's output distribution from an ensemble of fine-tuned LLMs onto a set around a public LLM's output distribution, then average the projected distributions and sample from it. Unlike DP-SGD which needs to consider the model architecture during training, PMixED is model agnostic, which makes PMixED a very appealing solution for current deployments. Our results show that PMixED achieves a stronger privacy guarantee than sample-level privacy and outperforms DP-SGD for privacy $\epsilon = 8$ on large-scale datasets. Thus, PMixED offers a practical alternative to DP training methods for achieving strong generative utility without compromising privacy.
Ethos: Rectifying Language Models in Orthogonal Parameter Space
Apr 01, 2024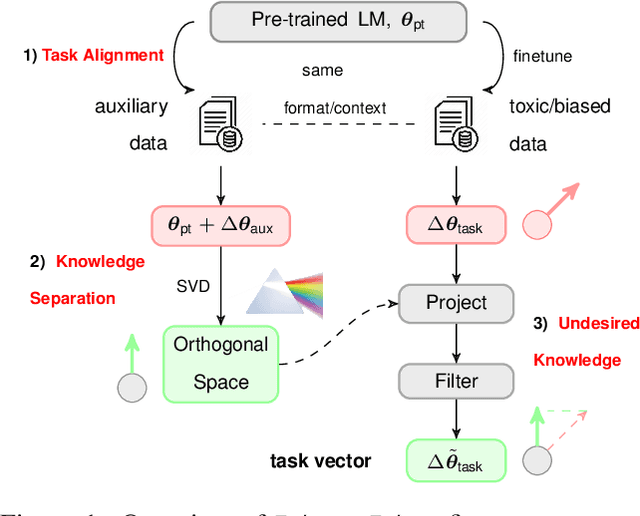
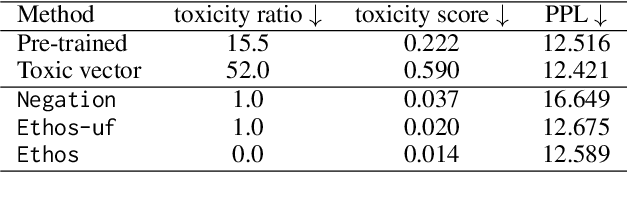
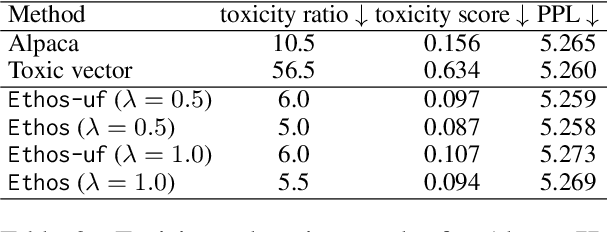

Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset. In this work, we present a new efficient approach, Ethos, that rectifies LMs to mitigate toxicity and bias in outputs and avoid privacy leakage. Ethos is built on task arithmetic. However, unlike current task arithmetic algorithms, Ethos distinguishes general beneficial and undesired knowledge when reconstructing task vectors. Specifically, Ethos first obtains a set of principal components from the pre-trained models using singular value decomposition. Then, by projecting the task vector onto principal components, Ethos identifies the principal components that encode general or undesired knowledge. Ethos performs negating using the task vector with undesired knowledge only, thereby minimizing collateral damage on general model utility. We demonstrate the efficacy of our approach on three different tasks: debiasing, detoxification, and memorization unlearning. Evaluations show Ethos is more effective in removing undesired knowledge and maintaining the overall model performance compared to current task arithmetic methods.
Edge Private Graph Neural Networks with Singular Value Perturbation
Mar 16, 2024



Graph neural networks (GNNs) play a key role in learning representations from graph-structured data and are demonstrated to be useful in many applications. However, the GNN training pipeline has been shown to be vulnerable to node feature leakage and edge extraction attacks. This paper investigates a scenario where an attacker aims to recover private edge information from a trained GNN model. Previous studies have employed differential privacy (DP) to add noise directly to the adjacency matrix or a compact graph representation. The added perturbations cause the graph structure to be substantially morphed, reducing the model utility. We propose a new privacy-preserving GNN training algorithm, Eclipse, that maintains good model utility while providing strong privacy protection on edges. Eclipse is based on two key observations. First, adjacency matrices in graph structures exhibit low-rank behavior. Thus, Eclipse trains GNNs with a low-rank format of the graph via singular values decomposition (SVD), rather than the original graph. Using the low-rank format, Eclipse preserves the primary graph topology and removes the remaining residual edges. Eclipse adds noise to the low-rank singular values instead of the entire graph, thereby preserving the graph privacy while still maintaining enough of the graph structure to maintain model utility. We theoretically show Eclipse provide formal DP guarantee on edges. Experiments on benchmark graph datasets show that Eclipse achieves significantly better privacy-utility tradeoff compared to existing privacy-preserving GNN training methods. In particular, under strong privacy constraints ($\epsilon$ < 4), Eclipse shows significant gains in the model utility by up to 46%. We further demonstrate that Eclipse also has better resilience against common edge attacks (e.g., LPA), lowering the attack AUC by up to 5% compared to other state-of-the-art baselines.
Differentially Private Knowledge Distillation via Synthetic Text Generation
Mar 01, 2024



Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy requires LLMs to train with Differential Privacy (DP) on private data. Concurrently it is also necessary to compress LLMs for real-life deployments on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, concurrently achieving both can result in even more utility loss. To this end, we propose a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private LLM. The knowledge of a teacher model is transferred onto the student in two ways: one way from the synthetic data itself, the hard labels, and the other way by the output distribution of the teacher model evaluated on the synthetic data, the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by exploiting hidden representations. Our results show that our framework substantially improves the utility over existing baselines with strong privacy parameters, {\epsilon} = 2, validating that we can successfully compress autoregressive LLMs while preserving the privacy of training data.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022
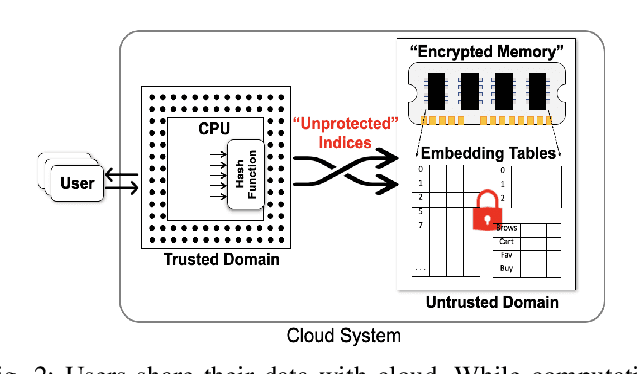
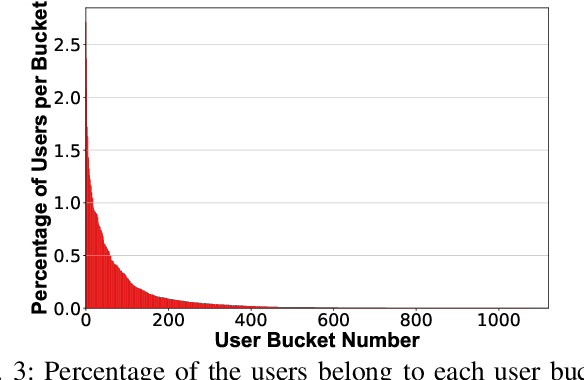
Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
MPC-Pipe: an Efficient Pipeline Scheme for Secure Multi-party Machine Learning Inference
Sep 27, 2022



Multi-party computing (MPC) has been gaining popularity over the past years as a secure computing model, particularly for machine learning (ML) inference. Compared with its competitors, MPC has fewer overheads than homomorphic encryption (HE) and has a more robust threat model than hardware-based trusted execution environments (TEE) such as Intel SGX. Despite its apparent advantages, MPC protocols still pay substantial performance penalties compared to plaintext when applied to ML algorithms. The overhead is due to added computation and communication costs. For multiplications that are ubiquitous in ML algorithms, MPC protocols add 32x more computational costs and 1 round of broadcasting among MPC servers. Moreover, ML computations that have trivial costs in plaintext, such as Softmax, ReLU, and other non-linear operations become very expensive due to added communication. Those added overheads make MPC less palatable to deploy in real-time ML inference frameworks, such as speech translation. In this work, we present MPC-Pipe, an MPC pipeline inference technique that uses two ML-specific approaches. 1) inter-linear-layer pipeline and 2) inner layer pipeline. Those two techniques shorten the total inference runtime for machine learning models. Our experiments have shown to reduce ML inference latency by up to 12.6% when model weights are private and 14.48\% when model weights are public, compared to current MPC protocol implementations.
DarKnight: An Accelerated Framework for Privacy and Integrity Preserving Deep Learning Using Trusted Hardware
Jun 30, 2022



Privacy and security-related concerns are growing as machine learning reaches diverse application domains. The data holders want to train or infer with private data while exploiting accelerators, such as GPUs, that are hosted in the cloud. Cloud systems are vulnerable to attackers that compromise the privacy of data and integrity of computations. Tackling such a challenge requires unifying theoretical privacy algorithms with hardware security capabilities. This paper presents DarKnight, a framework for large DNN training while protecting input privacy and computation integrity. DarKnight relies on cooperative execution between trusted execution environments (TEE) and accelerators, where the TEE provides privacy and integrity verification, while accelerators perform the bulk of the linear algebraic computation to optimize the performance. In particular, DarKnight uses a customized data encoding strategy based on matrix masking to create input obfuscation within a TEE. The obfuscated data is then offloaded to GPUs for fast linear algebraic computation. DarKnight's data obfuscation strategy provides provable data privacy and computation integrity in the cloud servers. While prior works tackle inference privacy and cannot be utilized for training, DarKnight's encoding scheme is designed to support both training and inference.
Attribute Inference Attack of Speech Emotion Recognition in Federated Learning Settings
Dec 26, 2021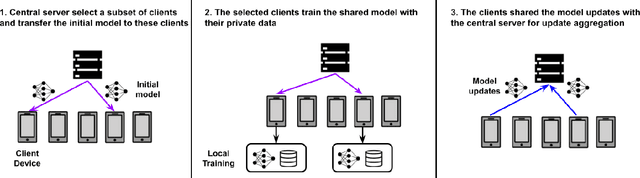
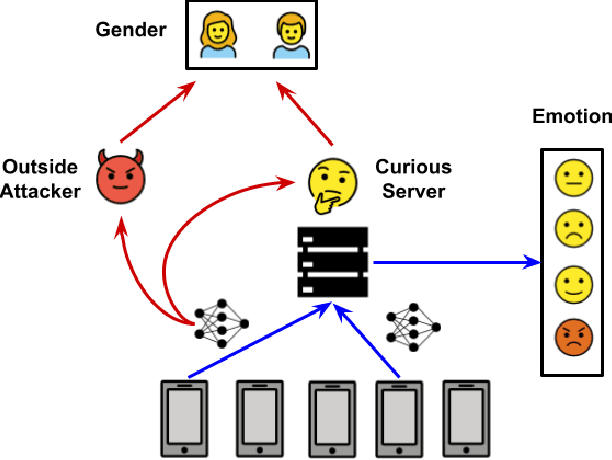
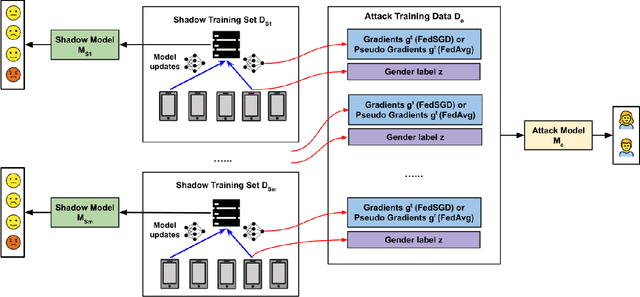
Speech emotion recognition (SER) processes speech signals to detect and characterize expressed perceived emotions. Many SER application systems often acquire and transmit speech data collected at the client-side to remote cloud platforms for inference and decision making. However, speech data carry rich information not only about emotions conveyed in vocal expressions, but also other sensitive demographic traits such as gender, age and language background. Consequently, it is desirable for SER systems to have the ability to classify emotion constructs while preventing unintended/improper inferences of sensitive and demographic information. Federated learning (FL) is a distributed machine learning paradigm that coordinates clients to train a model collaboratively without sharing their local data. This training approach appears secure and can improve privacy for SER. However, recent works have demonstrated that FL approaches are still vulnerable to various privacy attacks like reconstruction attacks and membership inference attacks. Although most of these have focused on computer vision applications, such information leakages exist in the SER systems trained using the FL technique. To assess the information leakage of SER systems trained using FL, we propose an attribute inference attack framework that infers sensitive attribute information of the clients from shared gradients or model parameters, corresponding to the FedSGD and the FedAvg training algorithms, respectively. As a use case, we empirically evaluate our approach for predicting the client's gender information using three SER benchmark datasets: IEMOCAP, CREMA-D, and MSP-Improv. We show that the attribute inference attack is achievable for SER systems trained using FL. We further identify that most information leakage possibly comes from the first layer in the SER model.
Verifiable Coded Computing: Towards Fast, Secure and Private Distributed Machine Learning
Jul 27, 2021

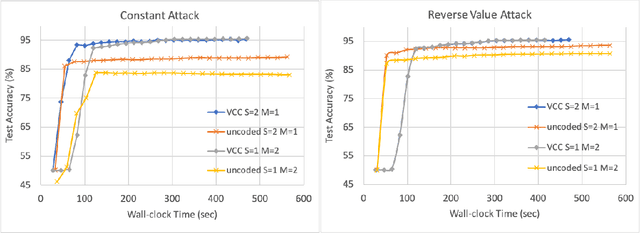
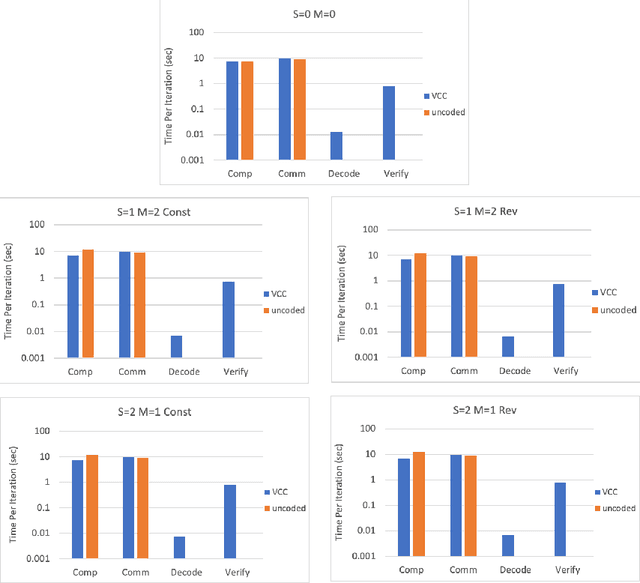
Stragglers, Byzantine workers, and data privacy are the main bottlenecks in distributed cloud computing. Several prior works proposed coded computing strategies to jointly address all three challenges. They require either a large number of workers, a significant communication cost or a significant computational complexity to tolerate malicious workers. Much of the overhead in prior schemes comes from the fact that they tightly couple coding for all three problems into a single framework. In this work, we propose Verifiable Coded Computing (VCC) framework that decouples Byzantine node detection challenge from the straggler tolerance. VCC leverages coded computing just for handling stragglers and privacy, and then uses an orthogonal approach of verifiable computing to tackle Byzantine nodes. Furthermore, VCC dynamically adapts its coding scheme to tradeoff straggler tolerance with Byzantine protection and vice-versa. We evaluate VCC on compute intensive distributed logistic regression application. Our experiments show that VCC speeds up the conventional uncoded implementation of distributed logistic regression by $3.2\times-6.9\times$, and also improves the test accuracy by up to $12.6\%$.
SpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks
Jun 04, 2021



Graph Neural Networks (GNNs) are the first choice methods for graph machine learning problems thanks to their ability to learn state-of-the-art level representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated Learning is the de-facto standard for collaborative training of machine learning models over many distributed edge devices without the need for centralization. Nevertheless, training graph neural networks in a federated setting is vaguely defined and brings statistical and systems challenges. This work proposes SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. SpreadGNN extends federated multi-task learning to realistic serverless settings for GNNs, and utilizes a novel optimization algorithm with a convergence guarantee, Decentralized Periodic Averaging SGD (DPA-SGD), to solve decentralized multi-task learning problems. We empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. Our results show that SpreadGNN outperforms GNN models trained over a central server-dependent federated learning system, even in constrained topologies. The source code is publicly available at https://github.com/FedML-AI/SpreadGNN