 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaoto Yokoya
ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model
Apr 14, 2024
Convolutional neural networks (CNN) and Transformers have made impressive progress in the field of remote sensing change detection (CD). However, both architectures have inherent shortcomings. Recently, the Mamba architecture, based on state space models, has shown remarkable performance in a series of natural language processing tasks, which can effectively compensate for the shortcomings of the above two architectures. In this paper, we explore for the first time the potential of the Mamba architecture for remote sensing CD tasks. We tailor the corresponding frameworks, called MambaBCD, MambaSCD, and MambaBDA, for binary change detection (BCD), semantic change detection (SCD), and building damage assessment (BDA), respectively. All three frameworks adopt the cutting-edge Visual Mamba architecture as the encoder, which allows full learning of global spatial contextual information from the input images. For the change decoder, which is available in all three architectures, we propose three spatio-temporal relationship modeling mechanisms, which can be naturally combined with the Mamba architecture and fully utilize its attribute to achieve spatio-temporal interaction of multi-temporal features, thereby obtaining accurate change information. On five benchmark datasets, our proposed frameworks outperform current CNN- and Transformer-based approaches without using any complex training strategies or tricks, fully demonstrating the potential of the Mamba architecture in CD tasks. Specifically, we obtained 83.11%, 88.39% and 94.19% F1 scores on the three BCD datasets SYSU, LEVIR-CD+, and WHU-CD; on the SCD dataset SECOND, we obtained 24.11% SeK; and on the BDA dataset xBD, we obtained 81.41% overall F1 score. Further experiments show that our architecture is quite robust to degraded data. The source code will be available in https://github.com/ChenHongruixuan/MambaCD
Change Detection Between Optical Remote Sensing Imagery and Map Data via Segment Anything Model (SAM)
Jan 17, 2024Unsupervised multimodal change detection is pivotal for time-sensitive tasks and comprehensive multi-temporal Earth monitoring. In this study, we explore unsupervised multimodal change detection between two key remote sensing data sources: optical high-resolution imagery and OpenStreetMap (OSM) data. Specifically, we propose to utilize the vision foundation model Segmentation Anything Model (SAM), for addressing our task. Leveraging SAM's exceptional zero-shot transfer capability, high-quality segmentation maps of optical images can be obtained. Thus, we can directly compare these two heterogeneous data forms in the so-called segmentation domain. We then introduce two strategies for guiding SAM's segmentation process: the 'no-prompt' and 'box/mask prompt' methods. The two strategies are designed to detect land-cover changes in general scenarios and to identify new land-cover objects within existing backgrounds, respectively. Experimental results on three datasets indicate that the proposed approach can achieve more competitive results compared to representative unsupervised multimodal change detection methods.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Submeter-level Land Cover Mapping of Japan
Nov 19, 2023Deep learning has shown promising performance in submeter-level mapping tasks; however, the annotation cost of submeter-level imagery remains a challenge, especially when applied on a large scale. In this paper, we present the first submeter-level land cover mapping of Japan with eight classes, at a relatively low annotation cost. We introduce a human-in-the-loop deep learning framework leveraging OpenEarthMap, a recently introduced benchmark dataset for global submeter-level land cover mapping, with a U-Net model that achieves national-scale mapping with a small amount of additional labeled data. By adding a small amount of labeled data of areas or regions where a U-Net model trained on OpenEarthMap clearly failed and retraining the model, an overall accuracy of 80\% was achieved, which is a nearly 16 percentage point improvement after retraining. Using aerial imagery provided by the Geospatial Information Authority of Japan, we create land cover classification maps of eight classes for the entire country of Japan. Our framework, with its low annotation cost and high-accuracy mapping results, demonstrates the potential to contribute to the automatic updating of national-scale land cover mapping using submeter-level optical remote sensing data. The mapping results will be made publicly available.
Enhancing Monocular Height Estimation from Aerial Images with Street-view Images
Nov 03, 2023Accurate height estimation from monocular aerial imagery presents a significant challenge due to its inherently ill-posed nature. This limitation is rooted in the absence of adequate geometric constraints available to the model when training with monocular imagery. Without additional geometric information to supplement the monocular image data, the model's ability to provide reliable estimations is compromised. In this paper, we propose a method that enhances monocular height estimation by incorporating street-view images. Our insight is that street-view images provide a distinct viewing perspective and rich structural details of the scene, serving as geometric constraints to enhance the performance of monocular height estimation. Specifically, we aim to optimize an implicit 3D scene representation, density field, with geometry constraints from street-view images, thereby improving the accuracy and robustness of height estimation. Our experimental results demonstrate the effectiveness of our proposed method, outperforming the baseline and offering significant improvements in terms of accuracy and structural consistency.
Flooding Regularization for Stable Training of Generative Adversarial Networks
Nov 01, 2023Generative Adversarial Networks (GANs) have shown remarkable performance in image generation. However, GAN training suffers from the problem of instability. One of the main approaches to address this problem is to modify the loss function, often using regularization terms in addition to changing the type of adversarial losses. This paper focuses on directly regularizing the adversarial loss function. We propose a method that applies flooding, an overfitting suppression method in supervised learning, to GANs to directly prevent the discriminator's loss from becoming excessively low. Flooding requires tuning the flood level, but when applied to GANs, we propose that the appropriate range of flood level settings is determined by the adversarial loss function, supported by theoretical analysis of GANs using the binary cross entropy loss. We experimentally verify that flooding stabilizes GAN training and can be combined with other stabilization techniques. We also reveal that by restricting the discriminator's loss to be no greater than flood level, the training proceeds stably even when the flood level is somewhat high.
Land-cover change detection using paired OpenStreetMap data and optical high-resolution imagery via object-guided Transformer
Oct 04, 2023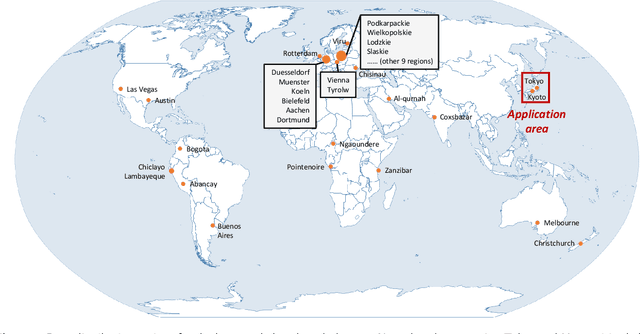

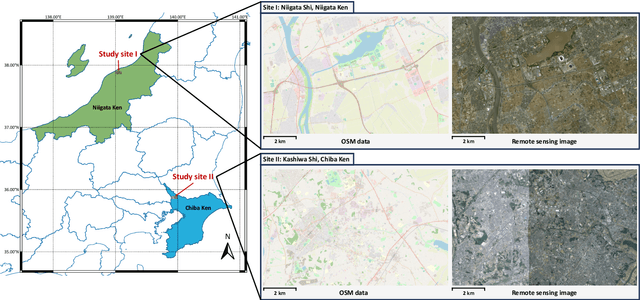
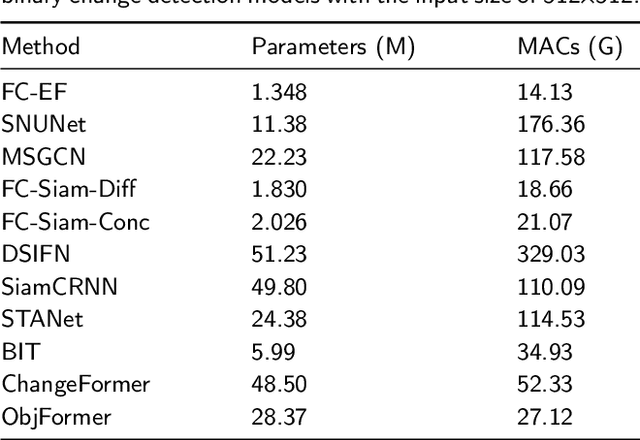
Optical high-resolution imagery and OpenStreetMap (OSM) data are two important data sources for land-cover change detection. Previous studies in these two data sources focus on utilizing the information in OSM data to aid the change detection on multi-temporal optical high-resolution images. This paper pioneers the direct detection of land-cover changes utilizing paired OSM data and optical imagery, thereby broadening the horizons of change detection tasks to encompass more dynamic earth observations. To this end, we propose an object-guided Transformer (ObjFormer) architecture by naturally combining the prevalent object-based image analysis (OBIA) technique with the advanced vision Transformer architecture. The introduction of OBIA can significantly reduce the computational overhead and memory burden in the self-attention module. Specifically, the proposed ObjFormer has a hierarchical pseudo-siamese encoder consisting of object-guided self-attention modules that extract representative features of different levels from OSM data and optical images; a decoder consisting of object-guided cross-attention modules can progressively recover the land-cover changes from the extracted heterogeneous features. In addition to the basic supervised binary change detection task, this paper raises a new semi-supervised semantic change detection task that does not require any manually annotated land-cover labels of optical images to train semantic change detectors. Two lightweight semantic decoders are added to ObjFormer to accomplish this task efficiently. A converse cross-entropy loss is designed to fully utilize the negative samples, thereby contributing to the great performance improvement in this task. The first large-scale benchmark dataset containing 1,287 map-image pairs (1024$\times$ 1024 pixels for each sample) covering 40 regions on six continents ...(see the manuscript for the full abstract)
Exchange means change: an unsupervised single-temporal change detection framework based on intra- and inter-image patch exchange
Oct 01, 2023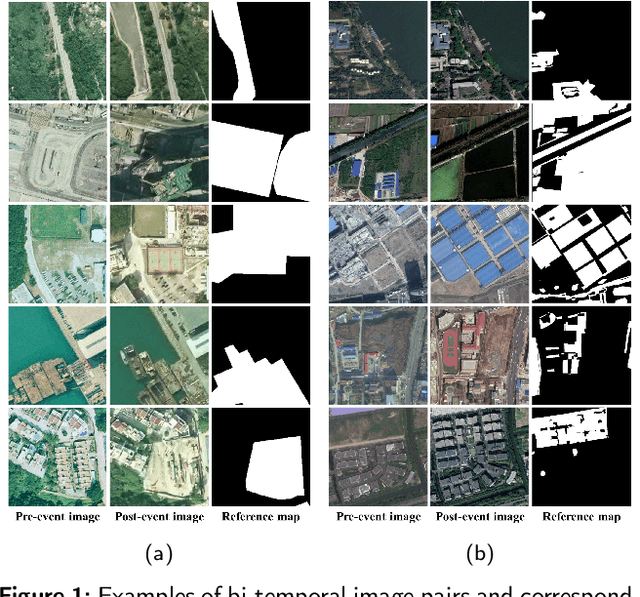

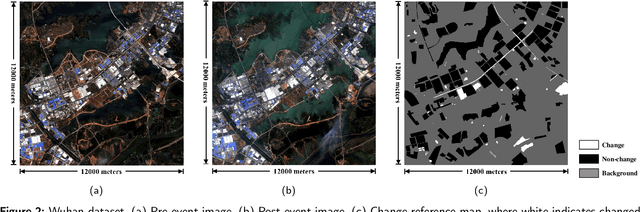
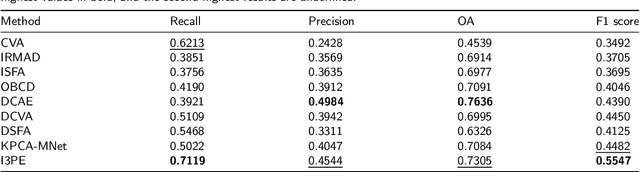
Change detection (CD) is a critical task in studying the dynamics of ecosystems and human activities using multi-temporal remote sensing images. While deep learning has shown promising results in CD tasks, it requires a large number of labeled and paired multi-temporal images to achieve high performance. Pairing and annotating large-scale multi-temporal remote sensing images is both expensive and time-consuming. To make deep learning-based CD techniques more practical and cost-effective, we propose an unsupervised single-temporal CD framework based on intra- and inter-image patch exchange (I3PE). The I3PE framework allows for training deep change detectors on unpaired and unlabeled single-temporal remote sensing images that are readily available in real-world applications. The I3PE framework comprises four steps: 1) intra-image patch exchange method is based on an object-based image analysis method and adaptive clustering algorithm, which generates pseudo-bi-temporal image pairs and corresponding change labels from single-temporal images by exchanging patches within the image; 2) inter-image patch exchange method can generate more types of land-cover changes by exchanging patches between images; 3) a simulation pipeline consisting of several image enhancement methods is proposed to simulate the radiometric difference between pre- and post-event images caused by different imaging conditions in real situations; 4) self-supervised learning based on pseudo-labels is applied to further improve the performance of the change detectors in both unsupervised and semi-supervised cases. Extensive experiments on two large-scale datasets demonstrate that I3PE outperforms representative unsupervised approaches and achieves F1 value improvements of 10.65% and 6.99% to the SOTA method. Moreover, I3PE can improve the performance of the ... (see the original article for full abstract)