 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanfeng Hong
Linearly-evolved Transformer for Pan-sharpening
Apr 19, 2024
Vision transformer family has dominated the satellite pan-sharpening field driven by the global-wise spatial information modeling mechanism from the core self-attention ingredient. The standard modeling rules within these promising pan-sharpening methods are to roughly stack the transformer variants in a cascaded manner. Despite the remarkable advancement, their success may be at the huge cost of model parameters and FLOPs, thus preventing its application over low-resource satellites.To address this challenge between favorable performance and expensive computation, we tailor an efficient linearly-evolved transformer variant and employ it to construct a lightweight pan-sharpening framework. In detail, we deepen into the popular cascaded transformer modeling with cutting-edge methods and develop the alternative 1-order linearly-evolved transformer variant with the 1-dimensional linear convolution chain to achieve the same function. In this way, our proposed method is capable of benefiting the cascaded modeling rule while achieving favorable performance in the efficient manner. Extensive experiments over multiple satellite datasets suggest that our proposed method achieves competitive performance against other state-of-the-art with fewer computational resources. Further, the consistently favorable performance has been verified over the hyper-spectral image fusion task. Our main focus is to provide an alternative global modeling framework with an efficient structure. The code will be publicly available.
SpectralMamba: Efficient Mamba for Hyperspectral Image Classification
Apr 12, 2024Recurrent neural networks and Transformers have recently dominated most applications in hyperspectral (HS) imaging, owing to their capability to capture long-range dependencies from spectrum sequences. However, despite the success of these sequential architectures, the non-ignorable inefficiency caused by either difficulty in parallelization or computationally prohibitive attention still hinders their practicality, especially for large-scale observation in remote sensing scenarios. To address this issue, we herein propose SpectralMamba -- a novel state space model incorporated efficient deep learning framework for HS image classification. SpectralMamba features the simplified but adequate modeling of HS data dynamics at two levels. First, in spatial-spectral space, a dynamical mask is learned by efficient convolutions to simultaneously encode spatial regularity and spectral peculiarity, thus attenuating the spectral variability and confusion in discriminative representation learning. Second, the merged spectrum can then be efficiently operated in the hidden state space with all parameters learned input-dependent, yielding selectively focused responses without reliance on redundant attention or imparallelizable recurrence. To explore the room for further computational downsizing, a piece-wise scanning mechanism is employed in-between, transferring approximately continuous spectrum into sequences with squeezed length while maintaining short- and long-term contextual profiles among hundreds of bands. Through extensive experiments on four benchmark HS datasets acquired by satellite-, aircraft-, and UAV-borne imagers, SpectralMamba surprisingly creates promising win-wins from both performance and efficiency perspectives.
Low-Rank Representations Meets Deep Unfolding: A Generalized and Interpretable Network for Hyperspectral Anomaly Detection
Feb 23, 2024Current hyperspectral anomaly detection (HAD) benchmark datasets suffer from low resolution, simple background, and small size of the detection data. These factors also limit the performance of the well-known low-rank representation (LRR) models in terms of robustness on the separation of background and target features and the reliance on manual parameter selection. To this end, we build a new set of HAD benchmark datasets for improving the robustness of the HAD algorithm in complex scenarios, AIR-HAD for short. Accordingly, we propose a generalized and interpretable HAD network by deeply unfolding a dictionary-learnable LLR model, named LRR-Net$^+$, which is capable of spectrally decoupling the background structure and object properties in a more generalized fashion and eliminating the bias introduced by vital interference targets concurrently. In addition, LRR-Net$^+$ integrates the solution process of the Alternating Direction Method of Multipliers (ADMM) optimizer with the deep network, guiding its search process and imparting a level of interpretability to parameter optimization. Additionally, the integration of physical models with DL techniques eliminates the need for manual parameter tuning. The manually tuned parameters are seamlessly transformed into trainable parameters for deep neural networks, facilitating a more efficient and automated optimization process. Extensive experiments conducted on the AIR-HAD dataset show the superiority of our LRR-Net$^+$ in terms of detection performance and generalization ability, compared to top-performing rivals. Furthermore, the compilable codes and our AIR-HAD benchmark datasets in this paper will be made available freely and openly at \url{https://sites.google.com/view/danfeng-hong}.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023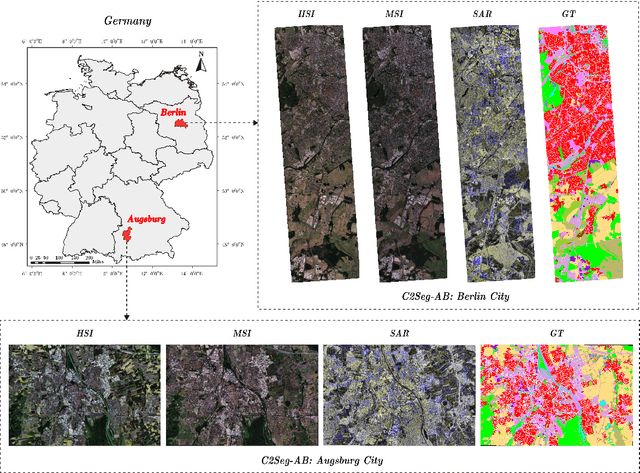
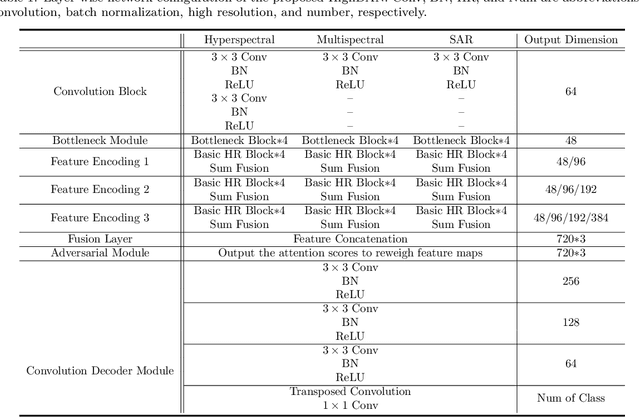
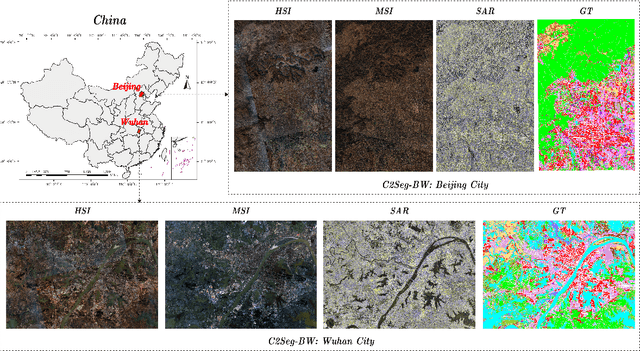
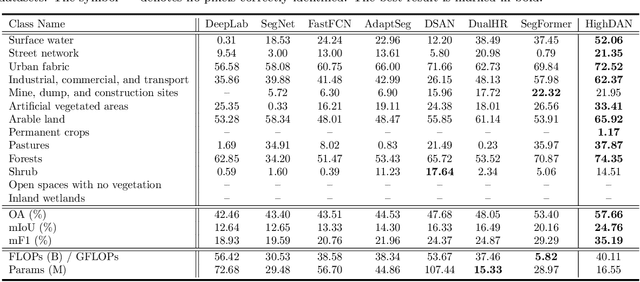
Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
Spatial Gated Multi-Layer Perceptron for Land Use and Land Cover Mapping
Aug 09, 2023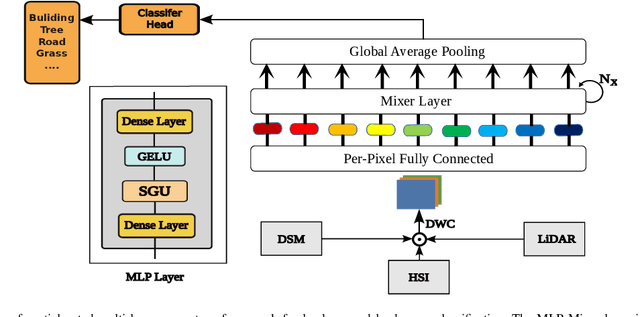
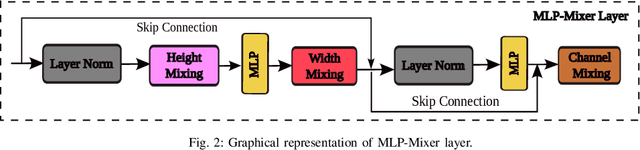

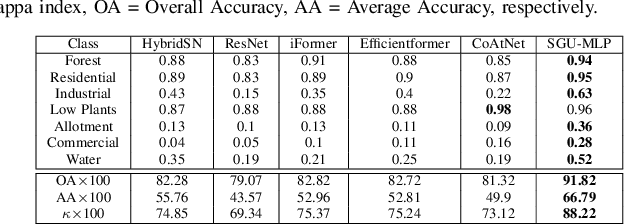
Convolutional Neural Networks (CNNs) are models that are utilized extensively for the hierarchical extraction of features. Vision transformers (ViTs), through the use of a self-attention mechanism, have recently achieved superior modeling of global contextual information compared to CNNs. However, to realize their image classification strength, ViTs require substantial training datasets. Where the available training data are limited, current advanced multi-layer perceptrons (MLPs) can provide viable alternatives to both deep CNNs and ViTs. In this paper, we developed the SGU-MLP, a learning algorithm that effectively uses both MLPs and spatial gating units (SGUs) for precise land use land cover (LULC) mapping. Results illustrated the superiority of the developed SGU-MLP classification algorithm over several CNN and CNN-ViT-based models, including HybridSN, ResNet, iFormer, EfficientFormer and CoAtNet. The proposed SGU-MLP algorithm was tested through three experiments in Houston, USA, Berlin, Germany and Augsburg, Germany. The SGU-MLP classification model was found to consistently outperform the benchmark CNN and CNN-ViT-based algorithms. For example, for the Houston experiment, SGU-MLP significantly outperformed HybridSN, CoAtNet, Efficientformer, iFormer and ResNet by approximately 15%, 19%, 20%, 21%, and 25%, respectively, in terms of average accuracy. The code will be made publicly available at https://github.com/aj1365/SGUMLP
UIU-Net: U-Net in U-Net for Infrared Small Object Detection
Dec 02, 2022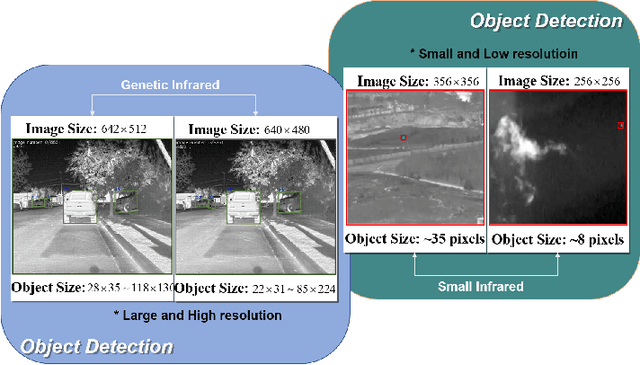
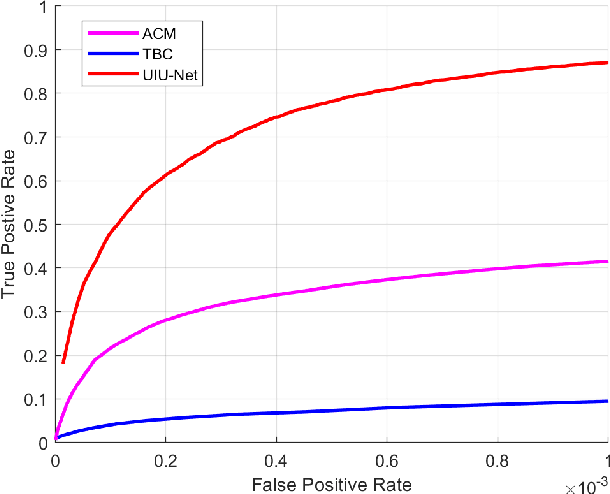
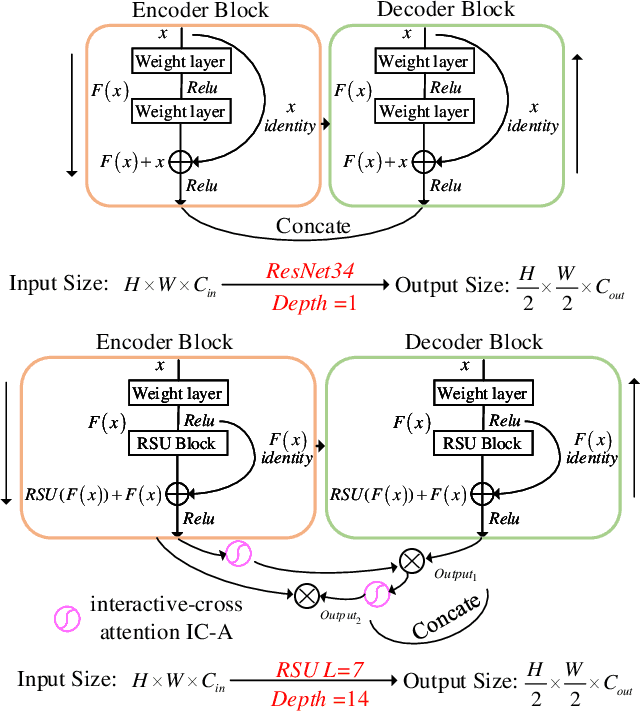
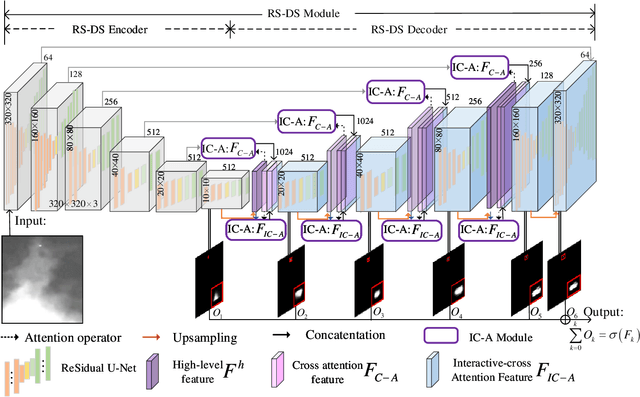
Learning-based infrared small object detection methods currently rely heavily on the classification backbone network. This tends to result in tiny object loss and feature distinguishability limitations as the network depth increases. Furthermore, small objects in infrared images are frequently emerged bright and dark, posing severe demands for obtaining precise object contrast information. For this reason, we in this paper propose a simple and effective ``U-Net in U-Net'' framework, UIU-Net for short, and detect small objects in infrared images. As the name suggests, UIU-Net embeds a tiny U-Net into a larger U-Net backbone, enabling the multi-level and multi-scale representation learning of objects. Moreover, UIU-Net can be trained from scratch, and the learned features can enhance global and local contrast information effectively. More specifically, the UIU-Net model is divided into two modules: the resolution-maintenance deep supervision (RM-DS) module and the interactive-cross attention (IC-A) module. RM-DS integrates Residual U-blocks into a deep supervision network to generate deep multi-scale resolution-maintenance features while learning global context information. Further, IC-A encodes the local context information between the low-level details and high-level semantic features. Extensive experiments conducted on two infrared single-frame image datasets, i.e., SIRST and Synthetic datasets, show the effectiveness and superiority of the proposed UIU-Net in comparison with several state-of-the-art infrared small object detection methods. The proposed UIU-Net also produces powerful generalization performance for video sequence infrared small object datasets, e.g., ATR ground/air video sequence dataset. The codes of this work are available openly at \url{https://github.com/danfenghong/IEEE_TIP_UIU-Net}.
Panchromatic and Multispectral Image Fusion via Alternating Reverse Filtering Network
Oct 15, 2022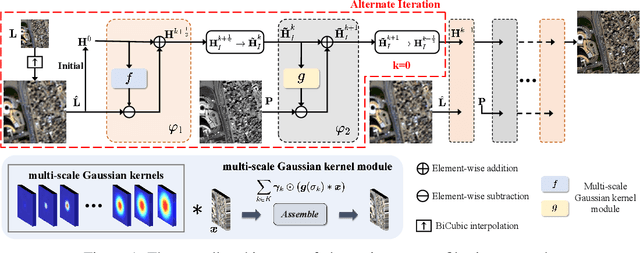
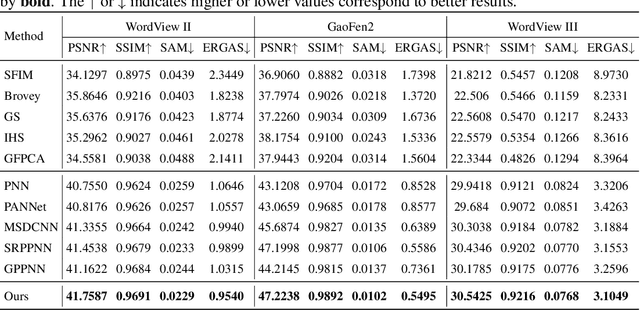
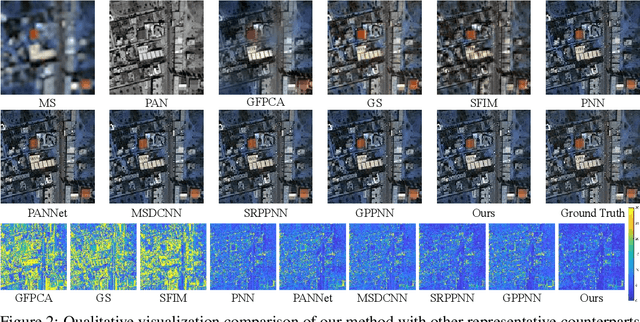

Panchromatic (PAN) and multi-spectral (MS) image fusion, named Pan-sharpening, refers to super-resolve the low-resolution (LR) multi-spectral (MS) images in the spatial domain to generate the expected high-resolution (HR) MS images, conditioning on the corresponding high-resolution PAN images. In this paper, we present a simple yet effective \textit{alternating reverse filtering network} for pan-sharpening. Inspired by the classical reverse filtering that reverses images to the status before filtering, we formulate pan-sharpening as an alternately iterative reverse filtering process, which fuses LR MS and HR MS in an interpretable manner. Different from existing model-driven methods that require well-designed priors and degradation assumptions, the reverse filtering process avoids the dependency on pre-defined exact priors. To guarantee the stability and convergence of the iterative process via contraction mapping on a metric space, we develop the learnable multi-scale Gaussian kernel module, instead of using specific filters. We demonstrate the theoretical feasibility of such formulations. Extensive experiments on diverse scenes to thoroughly verify the performance of our method, significantly outperforming the state of the arts.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022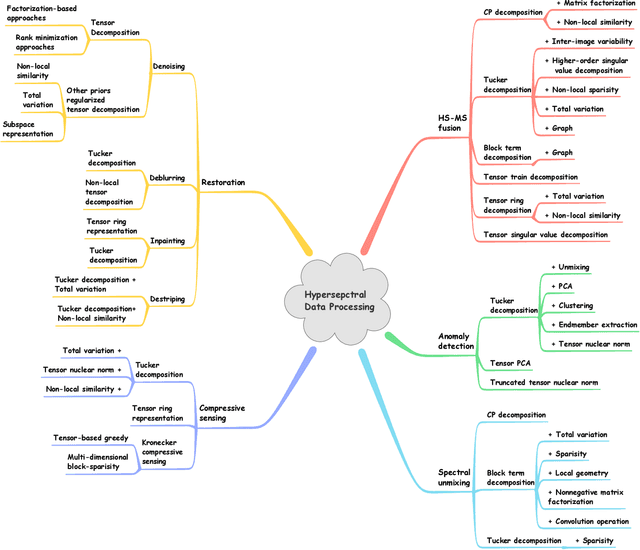



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.