 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNikita Kuzmin
Probabilistic Back-ends for Online Speaker Recognition and Clustering
Feb 19, 2023



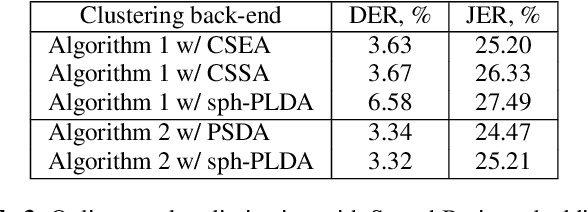
This paper focuses on multi-enrollment speaker recognition which naturally occurs in the task of online speaker clustering, and studies the properties of different scoring back-ends in this scenario. First, we show that popular cosine scoring suffers from poor score calibration with a varying number of enrollment utterances. Second, we propose a simple replacement for cosine scoring based on an extremely constrained version of probabilistic linear discriminant analysis (PLDA). The proposed model improves over the cosine scoring for multi-enrollment recognition while keeping the same performance in the case of one-to-one comparisons. Finally, we consider an online speaker clustering task where each step naturally involves multi-enrollment recognition. We propose an online clustering algorithm allowing us to take benefits from the PLDA model such as the ability to handle uncertainty and better score calibration. Our experiments demonstrate the effectiveness of the proposed algorithm.
Magnitude-aware Probabilistic Speaker Embeddings
Feb 28, 2022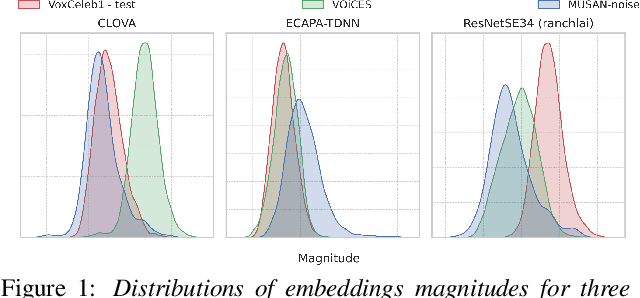


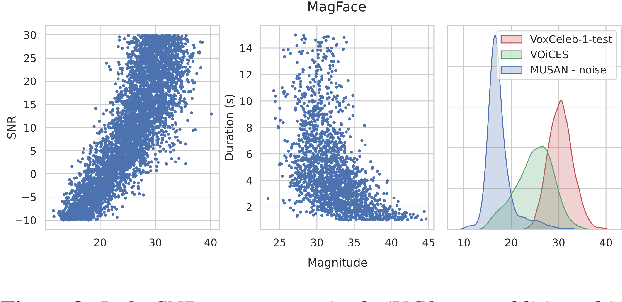
Recently, hyperspherical embeddings have established themselves as a dominant technique for face and voice recognition. Specifically, Euclidean space vector embeddings are learned to encode person-specific information in their direction while ignoring the magnitude. However, recent studies have shown that the magnitudes of the embeddings extracted by deep neural networks may indicate the quality of the corresponding inputs. This paper explores the properties of the magnitudes of the embeddings related to quality assessment and out-of-distribution detection. We propose a new probabilistic speaker embedding extractor using the information encoded in the embedding magnitude and leverage it in the speaker verification pipeline. We also propose several quality-aware diarization methods and incorporate the magnitudes in those. Our results indicate significant improvements over magnitude-agnostic baselines both in speaker verification and diarization tasks.