 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNikos Komodakis
SPOT: Self-Training with Patch-Order Permutation for Object-Centric Learning with Autoregressive Transformers
Dec 01, 2023
Unsupervised object-centric learning aims to decompose scenes into interpretable object entities, termed slots. Slot-based auto-encoders stand out as a prominent method for this task. Within them, crucial aspects include guiding the encoder to generate object-specific slots and ensuring the decoder utilizes them during reconstruction. This work introduces two novel techniques, (i) an attention-based self-training approach, which distills superior slot-based attention masks from the decoder to the encoder, enhancing object segmentation, and (ii) an innovative patch-order permutation strategy for autoregressive transformers that strengthens the role of slot vectors in reconstruction. The effectiveness of these strategies is showcased experimentally. The combined approach significantly surpasses prior slot-based autoencoder methods in unsupervised object segmentation, especially with complex real-world images. We provide the implementation code at https://github.com/gkakogeorgiou/spot .
MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
Jul 18, 2023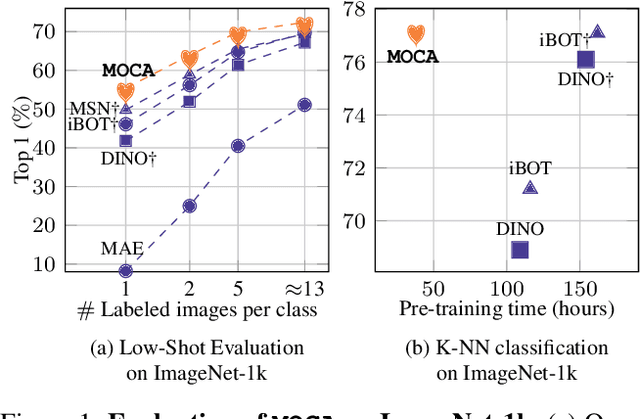

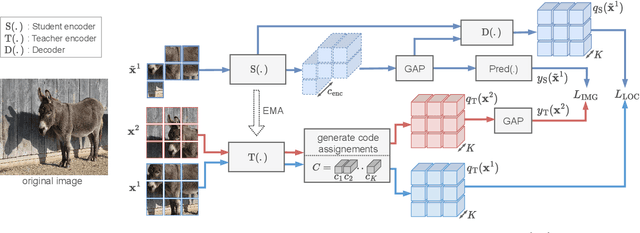
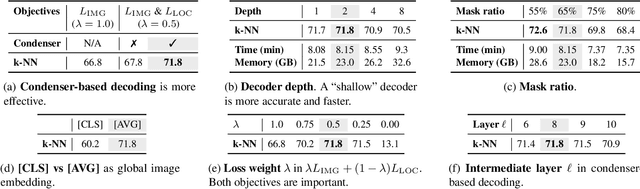
Self-supervised learning can be used for mitigating the greedy needs of Vision Transformer networks for very large fully-annotated datasets. Different classes of self-supervised learning offer representations with either good contextual reasoning properties, e.g., using masked image modeling strategies, or invariance to image perturbations, e.g., with contrastive methods. In this work, we propose a single-stage and standalone method, MOCA, which unifies both desired properties using novel mask-and-predict objectives defined with high-level features (instead of pixel-level details). Moreover, we show how to effectively employ both learning paradigms in a synergistic and computation-efficient way. Doing so, we achieve new state-of-the-art results on low-shot settings and strong experimental results in various evaluation protocols with a training that is at least 3 times faster than prior methods.
What to Hide from Your Students: Attention-Guided Masked Image Modeling
Mar 23, 2022
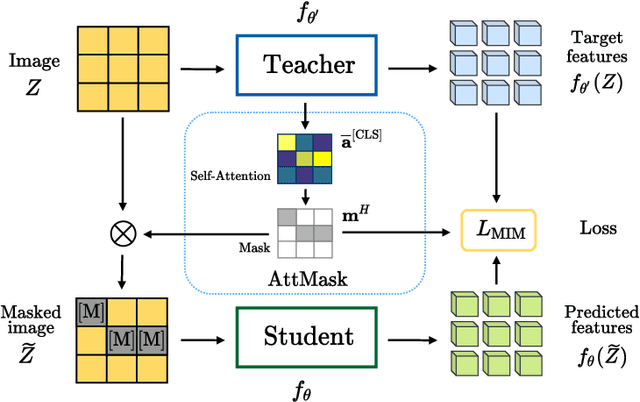
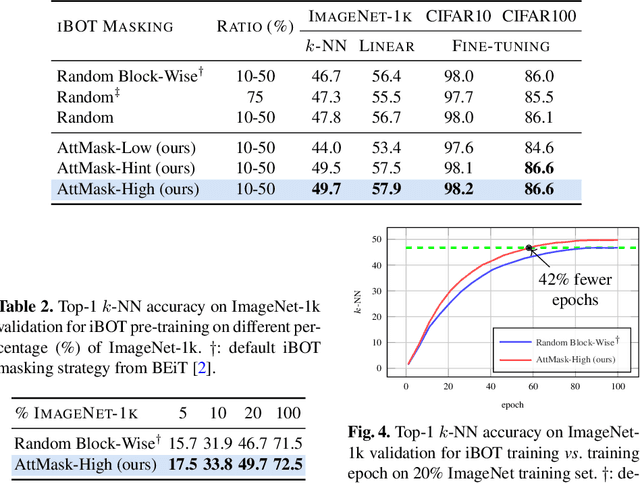
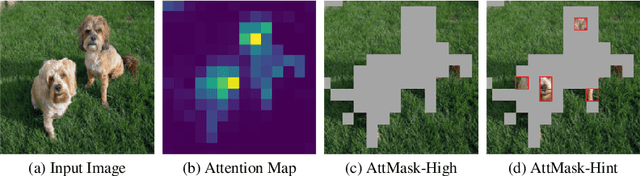
Transformers and masked language modeling are quickly being adopted and explored in computer vision as vision transformers and masked image modeling (MIM). In this work, we argue that image token masking is fundamentally different from token masking in text, due to the amount and correlation of tokens in an image. In particular, to generate a challenging pretext task for MIM, we advocate a shift from random masking to informed masking. We develop and exhibit this idea in the context of distillation-based MIM, where a teacher transformer encoder generates an attention map, which we use to guide masking for the student encoder. We thus introduce a novel masking strategy, called attention-guided masking (AttMask), and we demonstrate its effectiveness over random masking for dense distillation-based MIM as well as plain distillation-based self-supervised learning on classification tokens. We confirm that AttMask accelerates the learning process and improves the performance on a variety of downstream tasks.
Online Bag-of-Visual-Words Generation for Unsupervised Representation Learning
Dec 21, 2020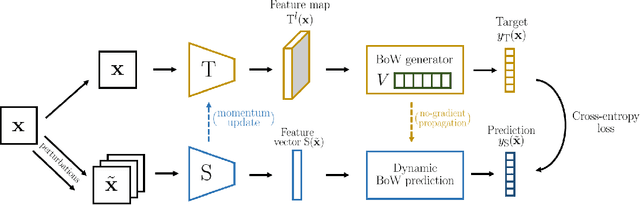
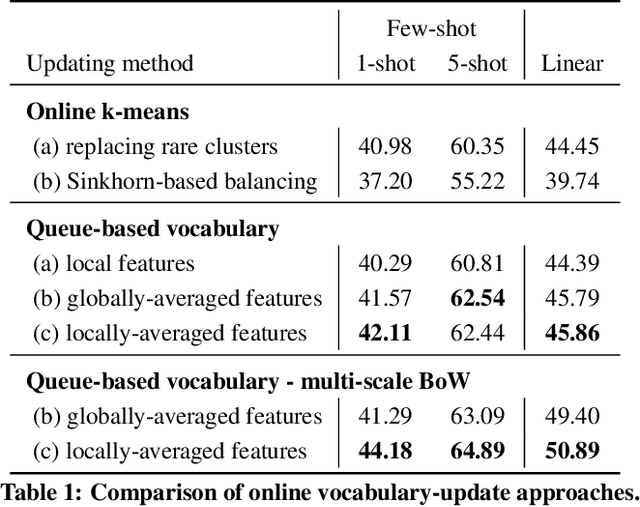
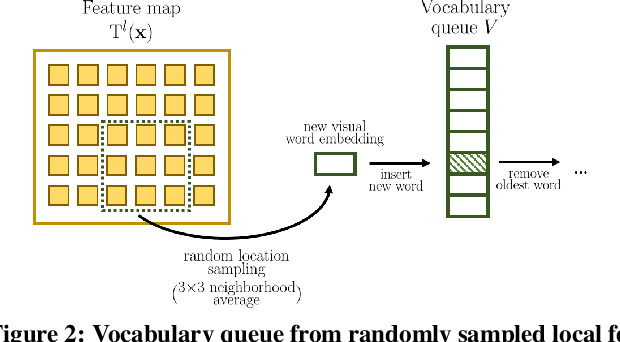
Learning image representations without human supervision is an important and active research field. Several recent approaches have successfully leveraged the idea of making such a representation invariant under different types of perturbations, especially via contrastive-based instance discrimination training. Although effective visual representations should indeed exhibit such invariances, there are other important characteristics, such as encoding contextual reasoning skills, for which alternative reconstruction-based approaches might be better suited. With this in mind, we propose a teacher-student scheme to learn representations by training a convnet to reconstruct a bag-of-visual-words (BoW) representation of an image, given as input a perturbed version of that same image. Our strategy performs an online training of both the teacher network (whose role is to generate the BoW targets) and the student network (whose role is to learn representations), along with an online update of the visual-words vocabulary (used for the BoW targets). This idea effectively enables fully online BoW-guided unsupervised learning. Extensive experiments demonstrate the interest of our BoW-based strategy which surpasses previous state-of-the-art methods (including contrastive-based ones) in several applications. For instance, in downstream tasks such Pascal object detection, Pascal classification and Places205 classification, our method improves over all prior unsupervised approaches, thus establishing new state-of-the-art results that are also significantly better even than those of supervised pre-training. We provide the implementation code at https://github.com/valeoai/obow.
Learning Representations by Predicting Bags of Visual Words
Feb 27, 2020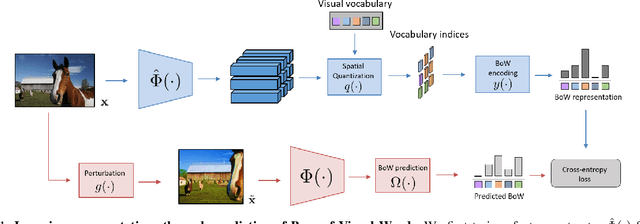
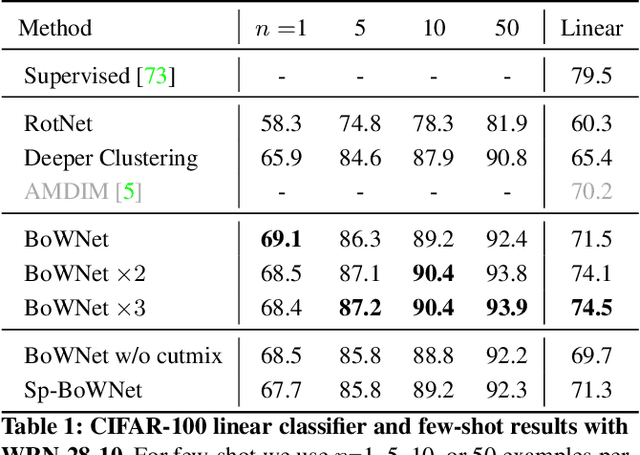
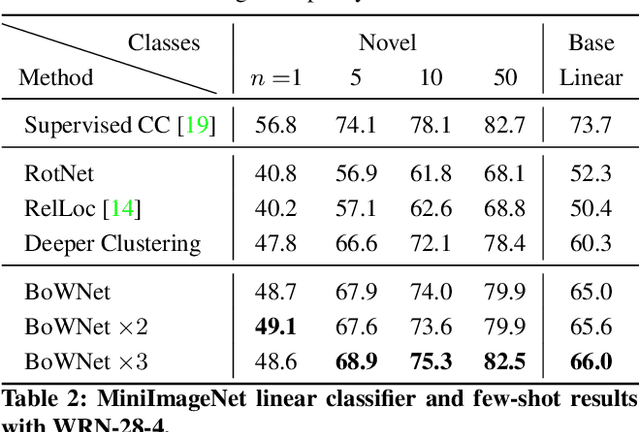

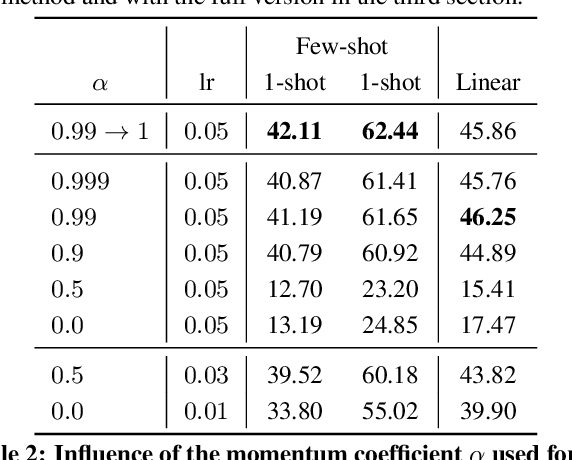
Self-supervised representation learning targets to learn convnet-based image representations from unlabeled data. Inspired by the success of NLP methods in this area, in this work we propose a self-supervised approach based on spatially dense image descriptions that encode discrete visual concepts, here called visual words. To build such discrete representations, we quantize the feature maps of a first pre-trained self-supervised convnet, over a k-means based vocabulary. Then, as a self-supervised task, we train another convnet to predict the histogram of visual words of an image (i.e., its Bag-of-Words representation) given as input a perturbed version of that image. The proposed task forces the convnet to learn perturbation-invariant and context-aware image features, useful for downstream image understanding tasks. We extensively evaluate our method and demonstrate very strong empirical results, e.g., our pre-trained self-supervised representations transfer better on detection task and similarly on classification over classes "unseen" during pre-training, when compared to the supervised case. This also shows that the process of image discretization into visual words can provide the basis for very powerful self-supervised approaches in the image domain, thus allowing further connections to be made to related methods from the NLP domain that have been extremely successful so far.
QUEST: Quantized embedding space for transferring knowledge
Dec 03, 2019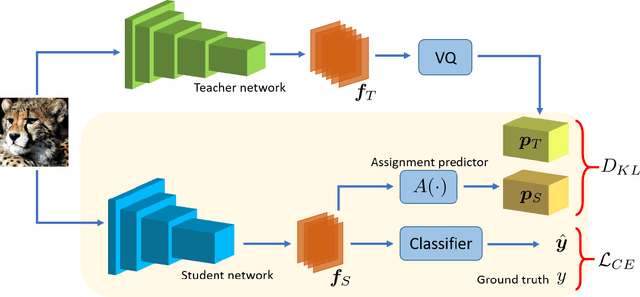

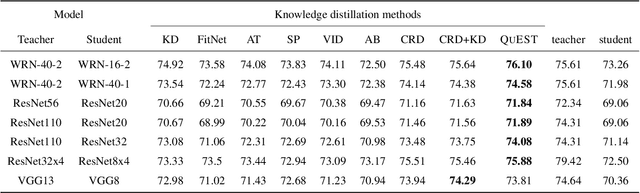
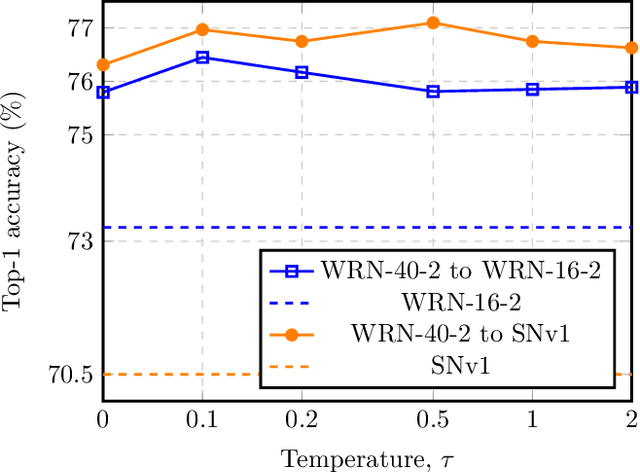
Knowledge distillation refers to the process of training a compact student network to achieve better accuracy by learning from a high capacity teacher network. Most of the existing knowledge distillation methods direct the student to follow the teacher by matching the teacher's output, feature maps or their distribution. In this work, we propose a novel way to achieve this goal: by distilling the knowledge through a quantized space. According to our method, the teacher's feature maps are quantized to represent the main visual concepts encompassed in the feature maps. The student is then asked to predict the quantized representation, which thus forms the task that the student uses to learn from the teacher. Despite its simplicity, we show that our approach is able to yield results that improve the state of the art on knowledge distillation. To that end, we provide an extensive evaluation across several network architectures and most commonly used benchmark datasets.
Deep Tone Mapping Operator for High Dynamic Range Images
Aug 12, 2019
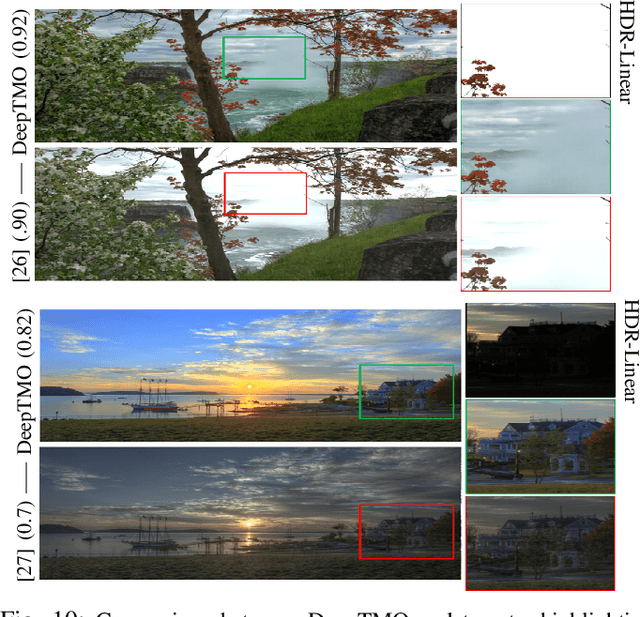
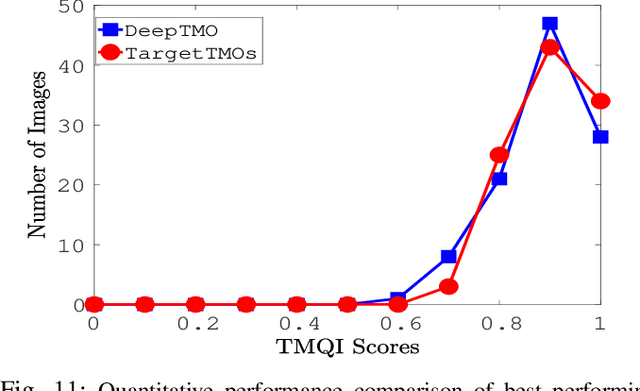
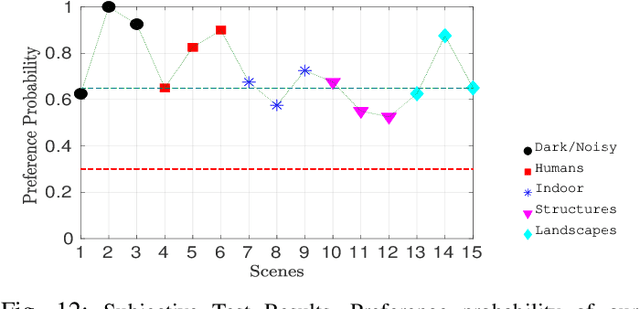
A computationally fast tone mapping operator (TMO) that can quickly adapt to a wide spectrum of high dynamic range (HDR) content is quintessential for visualization on varied low dynamic range (LDR) output devices such as movie screens or standard displays. Existing TMOs can successfully tone-map only a limited number of HDR content and require an extensive parameter tuning to yield the best subjective-quality tone-mapped output. In this paper, we address this problem by proposing a fast, parameter-free and scene-adaptable deep tone mapping operator (DeepTMO) that yields a high-resolution and high-subjective quality tone mapped output. Based on conditional generative adversarial network (cGAN), DeepTMO not only learns to adapt to vast scenic-content (e.g., outdoor, indoor, human, structures, etc.) but also tackles the HDR related scene-specific challenges such as contrast and brightness, while preserving the fine-grained details. We explore 4 possible combinations of Generator-Discriminator architectural designs to specifically address some prominent issues in HDR related deep-learning frameworks like blurring, tiling patterns and saturation artifacts. By exploring different influences of scales, loss-functions and normalization layers under a cGAN setting, we conclude with adopting a multi-scale model for our task. To further leverage on the large-scale availability of unlabeled HDR data, we train our network by generating targets using an objective HDR quality metric, namely Tone Mapping Image Quality Index (TMQI). We demonstrate results both quantitatively and qualitatively, and showcase that our DeepTMO generates high-resolution, high-quality output images over a large spectrum of real-world scenes. Finally, we evaluate the perceived quality of our results by conducting a pair-wise subjective study which confirms the versatility of our method.
Boosting Few-Shot Visual Learning with Self-Supervision
Jun 12, 2019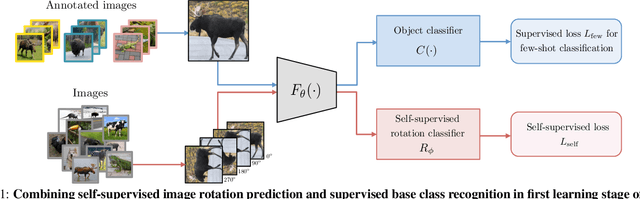
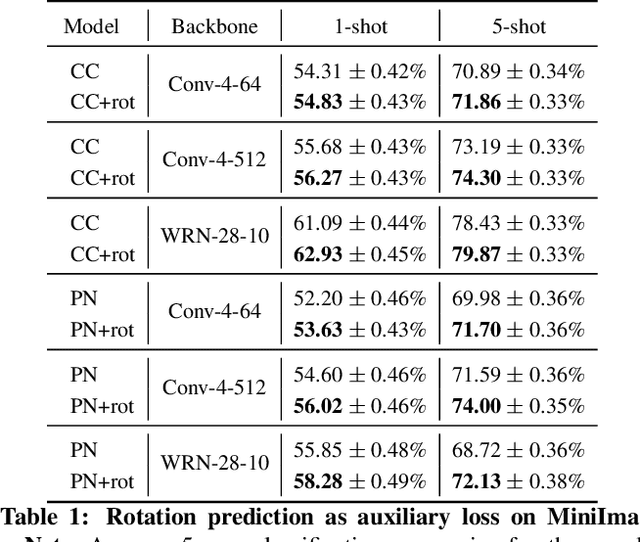
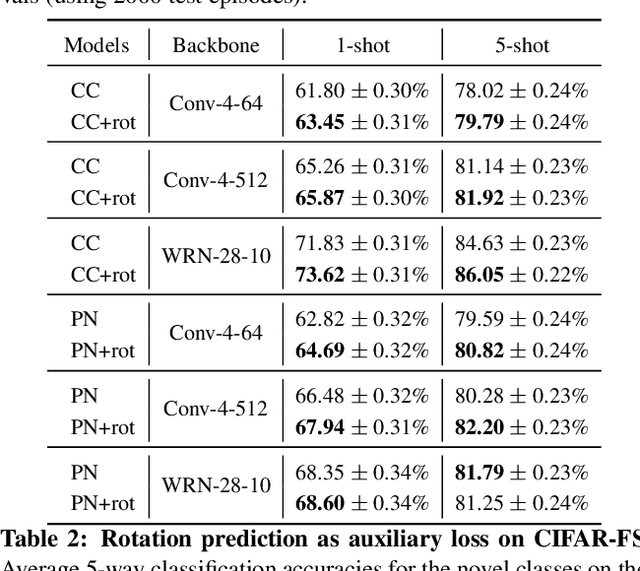
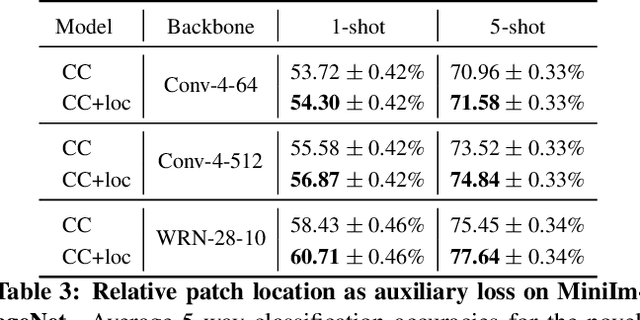
Few-shot learning and self-supervised learning address different facets of the same problem: how to train a model with little or no labeled data. Few-shot learning aims for optimization methods and models that can learn efficiently to recognize patterns in the low data regime. Self-supervised learning focuses instead on unlabeled data and looks into it for the supervisory signal to feed high capacity deep neural networks. In this work we exploit the complementarity of these two domains and propose an approach for improving few-shot learning through self-supervision. We use self-supervision as an auxiliary task in a few-shot learning pipeline, enabling feature extractors to learn richer and more transferable visual representations while still using few annotated samples. Through self-supervision, our approach can be naturally extended towards using diverse unlabeled data from other datasets in the few-shot setting. We report consistent improvements across an array of architectures, datasets and self-supervision techniques.
Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning
May 03, 2019
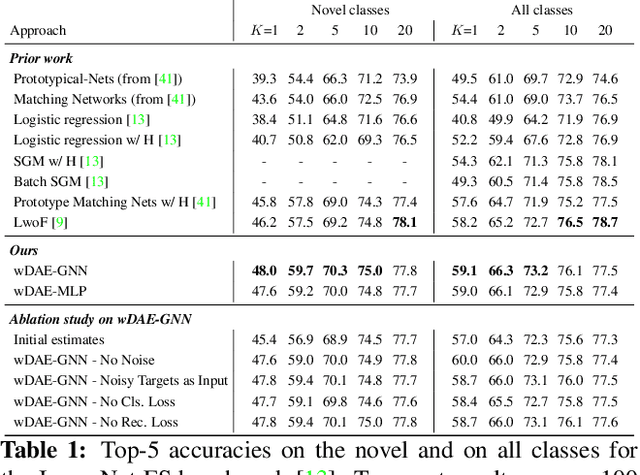
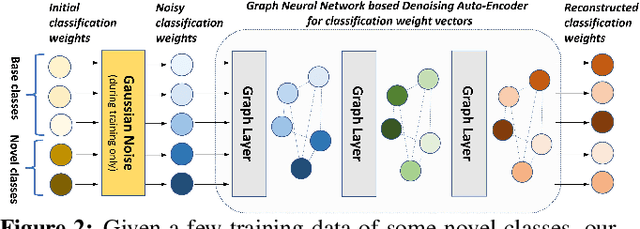
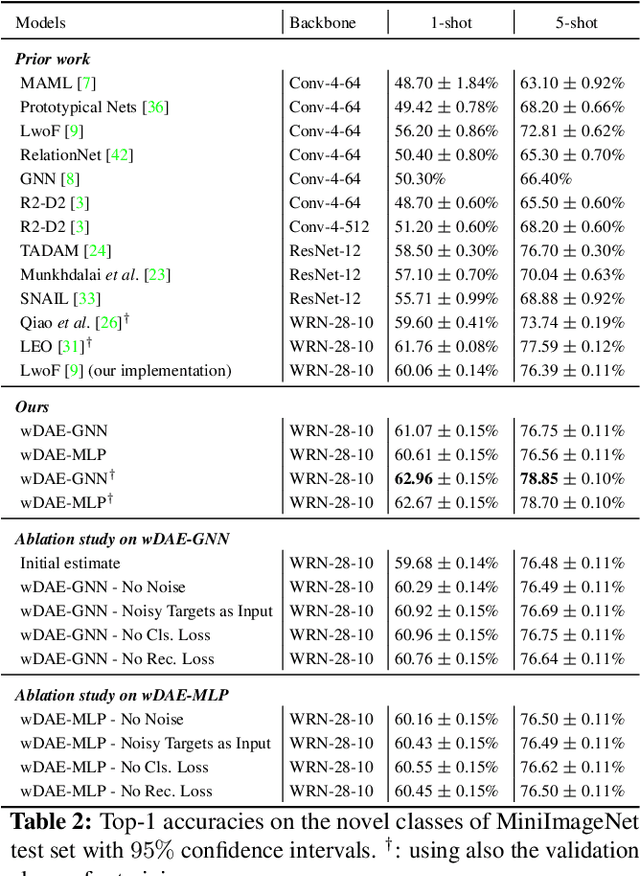
Given an initial recognition model already trained on a set of base classes, the goal of this work is to develop a meta-model for few-shot learning. The meta-model, given as input some novel classes with few training examples per class, must properly adapt the existing recognition model into a new model that can correctly classify in a unified way both the novel and the base classes. To accomplish this goal it must learn to output the appropriate classification weight vectors for those two types of classes. To build our meta-model we make use of two main innovations: we propose the use of a Denoising Autoencoder network (DAE) that (during training) takes as input a set of classification weights corrupted with Gaussian noise and learns to reconstruct the target-discriminative classification weights. In this case, the injected noise on the classification weights serves the role of regularizing the weight generating meta-model. Furthermore, in order to capture the co-dependencies between different classes in a given task instance of our meta-model, we propose to implement the DAE model as a Graph Neural Network (GNN). In order to verify the efficacy of our approach, we extensively evaluate it on ImageNet based few-shot benchmarks and we report strong results that surpass prior approaches. The code and models of our paper will be published on: https://github.com/gidariss/wDAE_GNN_FewShot
Exploring Weight Symmetry in Deep Neural Networks
Jan 10, 2019
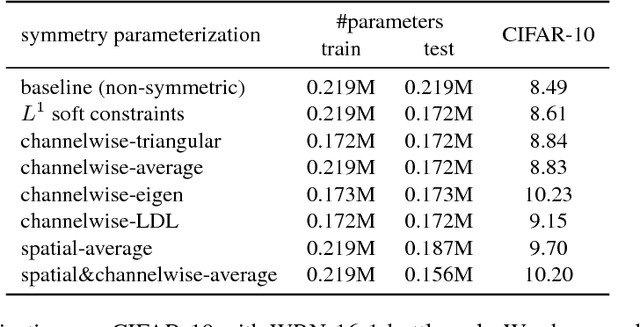
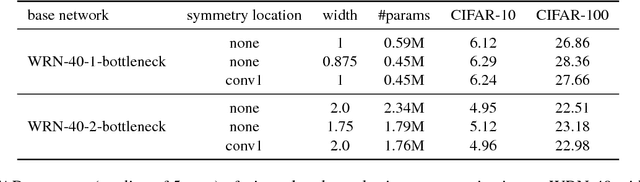
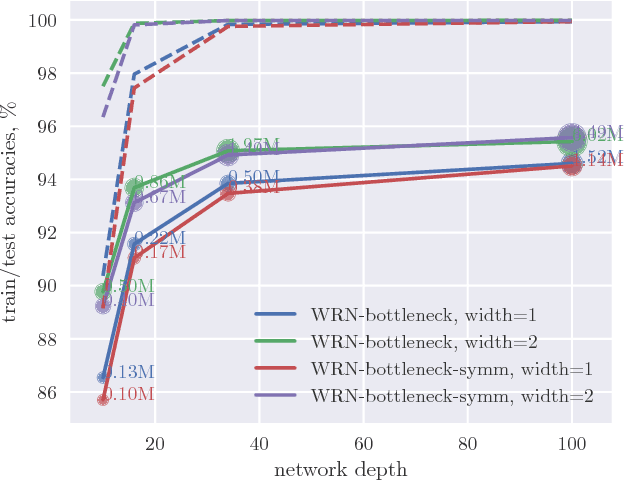
We propose to impose symmetry in neural network parameters to improve parameter usage and make use of dedicated convolution and matrix multiplication routines. Due to significant reduction in the number of parameters as a result of the symmetry constraints, one would expect a dramatic drop in accuracy. Surprisingly, we show that this is not the case, and, depending on network size, symmetry can have little or no negative effect on network accuracy, especially in deep overparameterized networks. We propose several ways to impose local symmetry in recurrent and convolutional neural networks, and show that our symmetry parameterizations satisfy universal approximation property for single hidden layer networks. We extensively evaluate these parameterizations on CIFAR, ImageNet and language modeling datasets, showing significant benefits from the use of symmetry. For instance, our ResNet-101 with channel-wise symmetry has almost 25% less parameters and only 0.2% accuracy loss on ImageNet. Code for our experiments is available at https://github.com/hushell/deep-symmetry