 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYannis Avrithis
A Learning Paradigm for Interpretable Gradients
Apr 23, 2024
This paper studies interpretability of convolutional networks by means of saliency maps. Most approaches based on Class Activation Maps (CAM) combine information from fully connected layers and gradient through variants of backpropagation. However, it is well understood that gradients are noisy and alternatives like guided backpropagation have been proposed to obtain better visualization at inference. In this work, we present a novel training approach to improve the quality of gradients for interpretability. In particular, we introduce a regularization loss such that the gradient with respect to the input image obtained by standard backpropagation is similar to the gradient obtained by guided backpropagation. We find that the resulting gradient is qualitatively less noisy and improves quantitatively the interpretability properties of different networks, using several interpretability methods.
CA-Stream: Attention-based pooling for interpretable image recognition
Apr 23, 2024Explanations obtained from transformer-based architectures in the form of raw attention, can be seen as a class-agnostic saliency map. Additionally, attention-based pooling serves as a form of masking the in feature space. Motivated by this observation, we design an attention-based pooling mechanism intended to replace Global Average Pooling (GAP) at inference. This mechanism, called Cross-Attention Stream (CA-Stream), comprises a stream of cross attention blocks interacting with features at different network depths. CA-Stream enhances interpretability in models, while preserving recognition performance.
On Train-Test Class Overlap and Detection for Image Retrieval
Apr 01, 2024How important is it for training and evaluation sets to not have class overlap in image retrieval? We revisit Google Landmarks v2 clean, the most popular training set, by identifying and removing class overlap with Revisited Oxford and Paris [34], the most popular evaluation set. By comparing the original and the new RGLDv2-clean on a benchmark of reproduced state-of-the-art methods, our findings are striking. Not only is there a dramatic drop in performance, but it is inconsistent across methods, changing the ranking.What does it take to focus on objects or interest and ignore background clutter when indexing? Do we need to train an object detector and the representation separately? Do we need location supervision? We introduce Single-stage Detect-to-Retrieve (CiDeR), an end-to-end, single-stage pipeline to detect objects of interest and extract a global image representation. We outperform previous state-of-the-art on both existing training sets and the new RGLDv2-clean. Our dataset is available at https://github.com/dealicious-inc/RGLDv2-clean.
PowMix: A Versatile Regularizer for Multimodal Sentiment Analysis
Dec 19, 2023Multimodal sentiment analysis (MSA) leverages heterogeneous data sources to interpret the complex nature of human sentiments. Despite significant progress in multimodal architecture design, the field lacks comprehensive regularization methods. This paper introduces PowMix, a versatile embedding space regularizer that builds upon the strengths of unimodal mixing-based regularization approaches and introduces novel algorithmic components that are specifically tailored to multimodal tasks. PowMix is integrated before the fusion stage of multimodal architectures and facilitates intra-modal mixing, such as mixing text with text, to act as a regularizer. PowMix consists of five components: 1) a varying number of generated mixed examples, 2) mixing factor reweighting, 3) anisotropic mixing, 4) dynamic mixing, and 5) cross-modal label mixing. Extensive experimentation across benchmark MSA datasets and a broad spectrum of diverse architectural designs demonstrate the efficacy of PowMix, as evidenced by consistent performance improvements over baselines and existing mixing methods. An in-depth ablation study highlights the critical contribution of each PowMix component and how they synergistically enhance performance. Furthermore, algorithmic analysis demonstrates how PowMix behaves in different scenarios, particularly comparing early versus late fusion architectures. Notably, PowMix enhances overall performance without sacrificing model robustness or magnifying text dominance. It also retains its strong performance in situations of limited data. Our findings position PowMix as a promising versatile regularization strategy for MSA. Code will be made available.
Embedding Space Interpolation Beyond Mini-Batch, Beyond Pairs and Beyond Examples
Nov 09, 2023Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Its extensions mostly focus on the definition of interpolation and the space (input or feature) where it takes place, while the augmentation process itself is less studied. In most methods, the number of generated examples is limited to the mini-batch size and the number of examples being interpolated is limited to two (pairs), in the input space. We make progress in this direction by introducing MultiMix, which generates an arbitrarily large number of interpolated examples beyond the mini-batch size and interpolates the entire mini-batch in the embedding space. Effectively, we sample on the entire convex hull of the mini-batch rather than along linear segments between pairs of examples. On sequence data, we further extend to Dense MultiMix. We densely interpolate features and target labels at each spatial location and also apply the loss densely. To mitigate the lack of dense labels, we inherit labels from examples and weight interpolation factors by attention as a measure of confidence. Overall, we increase the number of loss terms per mini-batch by orders of magnitude at little additional cost. This is only possible because of interpolating in the embedding space. We empirically show that our solutions yield significant improvement over state-of-the-art mixup methods on four different benchmarks, despite interpolation being only linear. By analyzing the embedding space, we show that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
Adaptive Anchor Label Propagation for Transductive Few-Shot Learning
Oct 30, 2023Few-shot learning addresses the issue of classifying images using limited labeled data. Exploiting unlabeled data through the use of transductive inference methods such as label propagation has been shown to improve the performance of few-shot learning significantly. Label propagation infers pseudo-labels for unlabeled data by utilizing a constructed graph that exploits the underlying manifold structure of the data. However, a limitation of the existing label propagation approaches is that the positions of all data points are fixed and might be sub-optimal so that the algorithm is not as effective as possible. In this work, we propose a novel algorithm that adapts the feature embeddings of the labeled data by minimizing a differentiable loss function optimizing their positions in the manifold in the process. Our novel algorithm, Adaptive Anchor Label Propagation}, outperforms the standard label propagation algorithm by as much as 7% and 2% in the 1-shot and 5-shot settings respectively. We provide experimental results highlighting the merits of our algorithm on four widely used few-shot benchmark datasets, namely miniImageNet, tieredImageNet, CUB and CIFAR-FS and two commonly used backbones, ResNet12 and WideResNet-28-10. The source code can be found at https://github.com/MichalisLazarou/A2LP.
Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
Oct 12, 2023
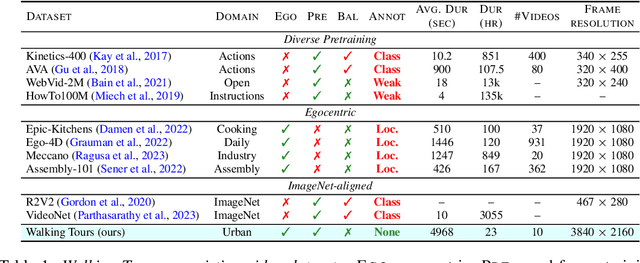
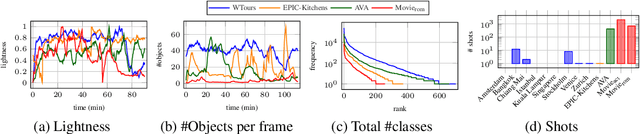
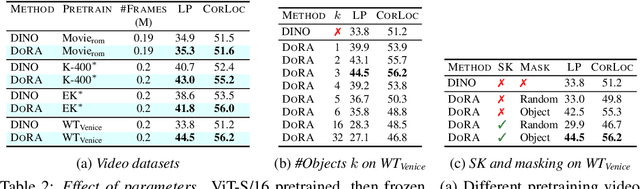
Self-supervised learning has unlocked the potential of scaling up pretraining to billions of images, since annotation is unnecessary. But are we making the best use of data? How more economical can we be? In this work, we attempt to answer this question by making two contributions. First, we investigate first-person videos and introduce a "Walking Tours" dataset. These videos are high-resolution, hours-long, captured in a single uninterrupted take, depicting a large number of objects and actions with natural scene transitions. They are unlabeled and uncurated, thus realistic for self-supervision and comparable with human learning. Second, we introduce a novel self-supervised image pretraining method tailored for learning from continuous videos. Existing methods typically adapt image-based pretraining approaches to incorporate more frames. Instead, we advocate a "tracking to learn to recognize" approach. Our method called DoRA, leads to attention maps that Discover and tRAck objects over time in an end-to-end manner, using transformer cross-attention. We derive multiple views from the tracks and use them in a classical self-supervised distillation loss. Using our novel approach, a single Walking Tours video remarkably becomes a strong competitor to ImageNet for several image and video downstream tasks.
Zero-Shot and Few-Shot Video Question Answering with Multi-Modal Prompts
Sep 27, 2023Recent vision-language models are driven by large-scale pretrained models. However, adapting pretrained models on limited data presents challenges such as overfitting, catastrophic forgetting, and the cross-modal gap between vision and language. We introduce a parameter-efficient method to address these challenges, combining multimodal prompt learning and a transformer-based mapping network, while keeping the pretrained models frozen. Our experiments on several video question answering benchmarks demonstrate the superiority of our approach in terms of performance and parameter efficiency on both zero-shot and few-shot settings. Our code is available at https://engindeniz.github.io/vitis.
Keep It SimPool: Who Said Supervised Transformers Suffer from Attention Deficit?
Sep 13, 2023



Convolutional networks and vision transformers have different forms of pairwise interactions, pooling across layers and pooling at the end of the network. Does the latter really need to be different? As a by-product of pooling, vision transformers provide spatial attention for free, but this is most often of low quality unless self-supervised, which is not well studied. Is supervision really the problem? In this work, we develop a generic pooling framework and then we formulate a number of existing methods as instantiations. By discussing the properties of each group of methods, we derive SimPool, a simple attention-based pooling mechanism as a replacement of the default one for both convolutional and transformer encoders. We find that, whether supervised or self-supervised, this improves performance on pre-training and downstream tasks and provides attention maps delineating object boundaries in all cases. One could thus call SimPool universal. To our knowledge, we are the first to obtain attention maps in supervised transformers of at least as good quality as self-supervised, without explicit losses or modifying the architecture. Code at: https://github.com/billpsomas/simpool.
* ICCV 2023. Code and models: https://github.com/billpsomas/simpool
Adaptive manifold for imbalanced transductive few-shot learning
Apr 27, 2023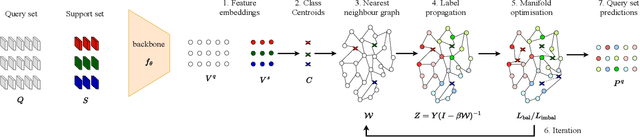
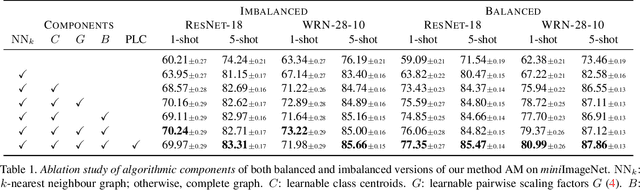
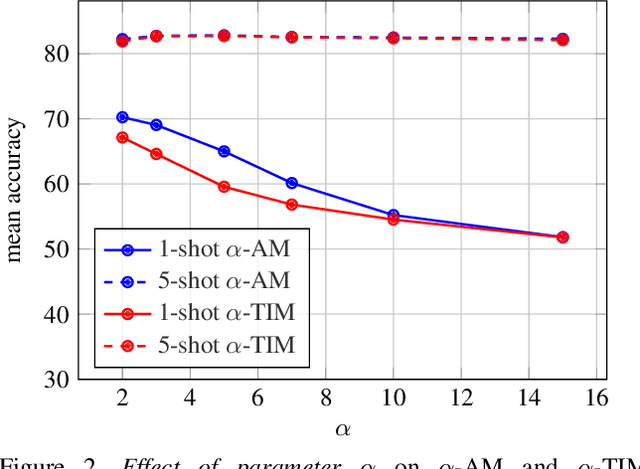
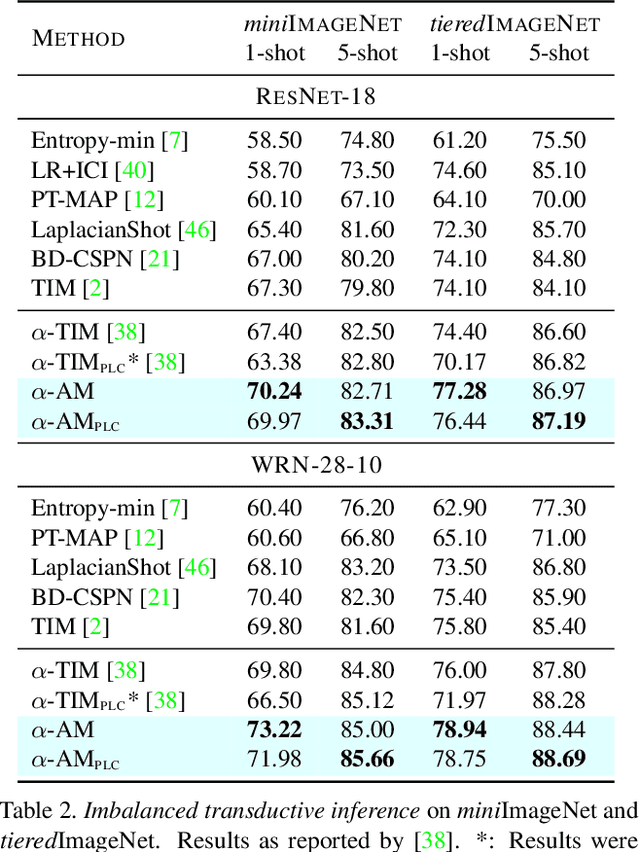
Transductive few-shot learning algorithms have showed substantially superior performance over their inductive counterparts by leveraging the unlabeled queries. However, the vast majority of such methods are evaluated on perfectly class-balanced benchmarks. It has been shown that they undergo remarkable drop in performance under a more realistic, imbalanced setting. To this end, we propose a novel algorithm to address imbalanced transductive few-shot learning, named Adaptive Manifold. Our method exploits the underlying manifold of the labeled support examples and unlabeled queries by using manifold similarity to predict the class probability distribution per query. It is parameterized by one centroid per class as well as a set of graph-specific parameters that determine the manifold. All parameters are optimized through a loss function that can be tuned towards class-balanced or imbalanced distributions. The manifold similarity shows substantial improvement over Euclidean distance, especially in the 1-shot setting. Our algorithm outperforms or is on par with other state of the art methods in three benchmark datasets, namely miniImageNet, tieredImageNet and CUB, and three different backbones, namely ResNet-18, WideResNet-28-10 and DenseNet-121. In certain cases, our algorithm outperforms the previous state of the art by as much as 4.2%.