 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanwei Zhang
A Survey on Visual Mamba
Apr 26, 2024
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
DP-Net: Learning Discriminative Parts for image recognition
Apr 23, 2024This paper presents Discriminative Part Network (DP-Net), a deep architecture with strong interpretation capabilities, which exploits a pretrained Convolutional Neural Network (CNN) combined with a part-based recognition module. This system learns and detects parts in the images that are discriminative among categories, without the need for fine-tuning the CNN, making it more scalable than other part-based models. While part-based approaches naturally offer interpretable representations, we propose explanations at image and category levels and introduce specific constraints on the part learning process to make them more discrimative.
CA-Stream: Attention-based pooling for interpretable image recognition
Apr 23, 2024Explanations obtained from transformer-based architectures in the form of raw attention, can be seen as a class-agnostic saliency map. Additionally, attention-based pooling serves as a form of masking the in feature space. Motivated by this observation, we design an attention-based pooling mechanism intended to replace Global Average Pooling (GAP) at inference. This mechanism, called Cross-Attention Stream (CA-Stream), comprises a stream of cross attention blocks interacting with features at different network depths. CA-Stream enhances interpretability in models, while preserving recognition performance.
A Learning Paradigm for Interpretable Gradients
Apr 23, 2024This paper studies interpretability of convolutional networks by means of saliency maps. Most approaches based on Class Activation Maps (CAM) combine information from fully connected layers and gradient through variants of backpropagation. However, it is well understood that gradients are noisy and alternatives like guided backpropagation have been proposed to obtain better visualization at inference. In this work, we present a novel training approach to improve the quality of gradients for interpretability. In particular, we introduce a regularization loss such that the gradient with respect to the input image obtained by standard backpropagation is similar to the gradient obtained by guided backpropagation. We find that the resulting gradient is qualitatively less noisy and improves quantitatively the interpretability properties of different networks, using several interpretability methods.
Revisiting Transferable Adversarial Image Examples: Attack Categorization, Evaluation Guidelines, and New Insights
Oct 18, 2023Transferable adversarial examples raise critical security concerns in real-world, black-box attack scenarios. However, in this work, we identify two main problems in common evaluation practices: (1) For attack transferability, lack of systematic, one-to-one attack comparison and fair hyperparameter settings. (2) For attack stealthiness, simply no comparisons. To address these problems, we establish new evaluation guidelines by (1) proposing a novel attack categorization strategy and conducting systematic and fair intra-category analyses on transferability, and (2) considering diverse imperceptibility metrics and finer-grained stealthiness characteristics from the perspective of attack traceback. To this end, we provide the first large-scale evaluation of transferable adversarial examples on ImageNet, involving 23 representative attacks against 9 representative defenses. Our evaluation leads to a number of new insights, including consensus-challenging ones: (1) Under a fair attack hyperparameter setting, one early attack method, DI, actually outperforms all the follow-up methods. (2) A state-of-the-art defense, DiffPure, actually gives a false sense of (white-box) security since it is indeed largely bypassed by our (black-box) transferable attacks. (3) Even when all attacks are bounded by the same $L_p$ norm, they lead to dramatically different stealthiness performance, which negatively correlates with their transferability performance. Overall, our work demonstrates that existing problematic evaluations have indeed caused misleading conclusions and missing points, and as a result, hindered the assessment of the actual progress in this field.
A Stochastic Online Forecast-and-Optimize Framework for Real-Time Energy Dispatch in Virtual Power Plants under Uncertainty
Sep 15, 2023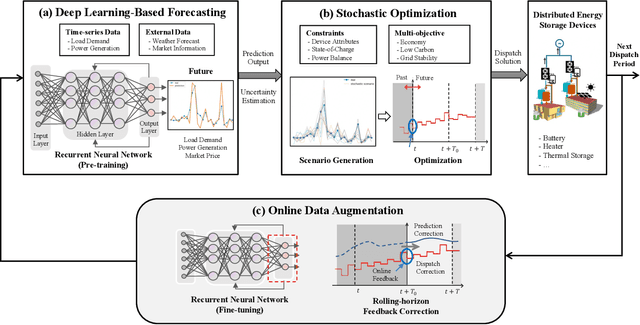
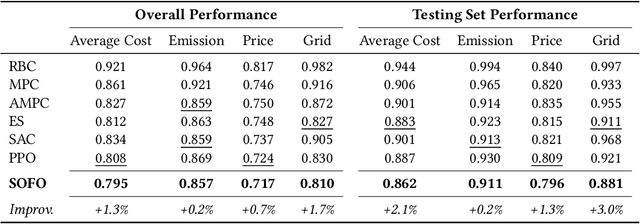

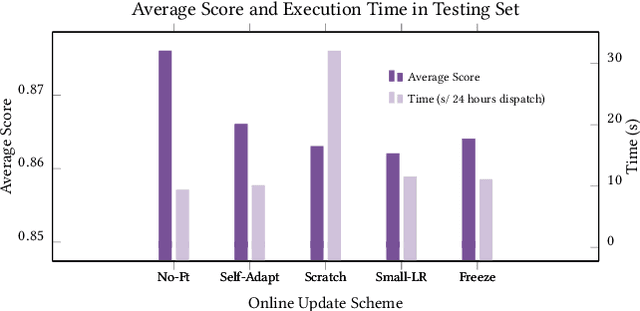
Aggregating distributed energy resources in power systems significantly increases uncertainties, in particular caused by the fluctuation of renewable energy generation. This issue has driven the necessity of widely exploiting advanced predictive control techniques under uncertainty to ensure long-term economics and decarbonization. In this paper, we propose a real-time uncertainty-aware energy dispatch framework, which is composed of two key elements: (i) A hybrid forecast-and-optimize sequential task, integrating deep learning-based forecasting and stochastic optimization, where these two stages are connected by the uncertainty estimation at multiple temporal resolutions; (ii) An efficient online data augmentation scheme, jointly involving model pre-training and online fine-tuning stages. In this way, the proposed framework is capable to rapidly adapt to the real-time data distribution, as well as to target on uncertainties caused by data drift, model discrepancy and environment perturbations in the control process, and finally to realize an optimal and robust dispatch solution. The proposed framework won the championship in CityLearn Challenge 2022, which provided an influential opportunity to investigate the potential of AI application in the energy domain. In addition, comprehensive experiments are conducted to interpret its effectiveness in the real-life scenario of smart building energy management.
Opti-CAM: Optimizing saliency maps for interpretability
Jan 17, 2023
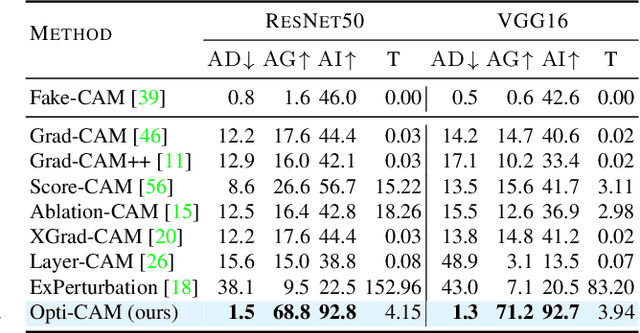

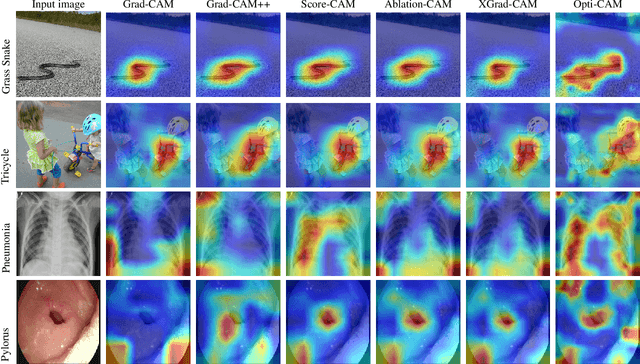
Methods based on class activation maps (CAM) provide a simple mechanism to interpret predictions of convolutional neural networks by using linear combinations of feature maps as saliency maps. By contrast, masking-based methods optimize a saliency map directly in the image space or learn it by training another network on additional data. In this work we introduce Opti-CAM, combining ideas from CAM-based and masking-based approaches. Our saliency map is a linear combination of feature maps, where weights are optimized per image such that the logit of the masked image for a given class is maximized. We also fix a fundamental flaw in two of the most common evaluation metrics of attribution methods. On several datasets, Opti-CAM largely outperforms other CAM-based approaches according to the most relevant classification metrics. We provide empirical evidence supporting that localization and classifier interpretability are not necessarily aligned.
Towards Good Practices in Evaluating Transfer Adversarial Attacks
Nov 17, 2022
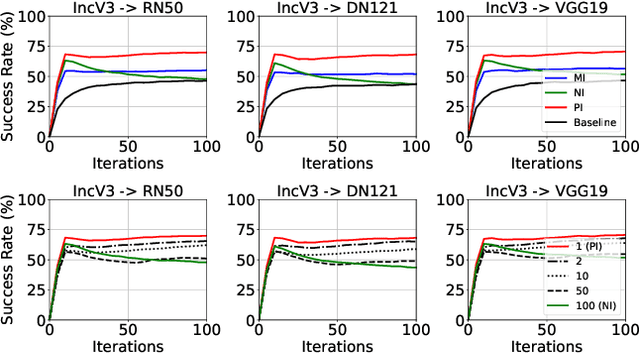

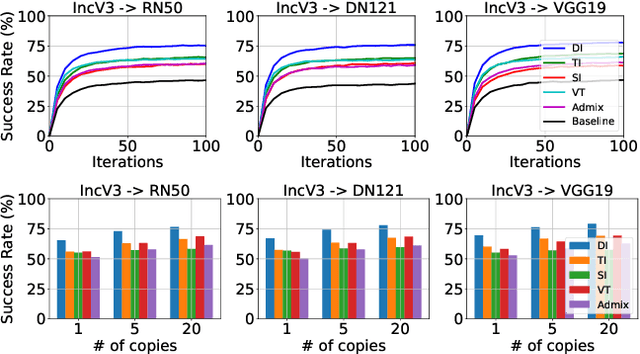
Transfer adversarial attacks raise critical security concerns in real-world, black-box scenarios. However, the actual progress of attack methods is difficult to assess due to two main limitations in existing evaluations. First, existing evaluations are unsystematic and sometimes unfair since new methods are often directly added to old ones without complete comparisons to similar methods. Second, existing evaluations mainly focus on transferability but overlook another key attack property: stealthiness. In this work, we design good practices to address these limitations. We first introduce a new attack categorization, which enables our systematic analyses of similar attacks in each specific category. Our analyses lead to new findings that complement or even challenge existing knowledge. Furthermore, we comprehensively evaluate 23 representative attacks against 9 defenses on ImageNet. We pay particular attention to stealthiness, by adopting diverse imperceptibility metrics and looking into new, finer-grained characteristics. Our evaluation reveals new important insights: 1) Transferability is highly contextual, and some white-box defenses may give a false sense of security since they are actually vulnerable to (black-box) transfer attacks; 2) All transfer attacks are less stealthy, and their stealthiness can vary dramatically under the same $L_{\infty}$ bound.
MOTSLAM: MOT-assisted monocular dynamic SLAM using single-view depth estimation
Oct 05, 2022



Visual SLAM systems targeting static scenes have been developed with satisfactory accuracy and robustness. Dynamic 3D object tracking has then become a significant capability in visual SLAM with the requirement of understanding dynamic surroundings in various scenarios including autonomous driving, augmented and virtual reality. However, performing dynamic SLAM solely with monocular images remains a challenging problem due to the difficulty of associating dynamic features and estimating their positions. In this paper, we present MOTSLAM, a dynamic visual SLAM system with the monocular configuration that tracks both poses and bounding boxes of dynamic objects. MOTSLAM first performs multiple object tracking (MOT) with associated both 2D and 3D bounding box detection to create initial 3D objects. Then, neural-network-based monocular depth estimation is applied to fetch the depth of dynamic features. Finally, camera poses, object poses, and both static, as well as dynamic map points, are jointly optimized using a novel bundle adjustment. Our experiments on the KITTI dataset demonstrate that our system has reached best performance on both camera ego-motion and object tracking on monocular dynamic SLAM.
KDD CUP 2022 Wind Power Forecasting Team 88VIP Solution
Aug 18, 2022



KDD CUP 2022 proposes a time-series forecasting task on spatial dynamic wind power dataset, in which the participants are required to predict the future generation given the historical context factors. The evaluation metrics contain RMSE and MAE. This paper describes the solution of Team 88VIP, which mainly comprises two types of models: a gradient boosting decision tree to memorize the basic data patterns and a recurrent neural network to capture the deep and latent probabilistic transitions. Ensembling these models contributes to tackle the fluctuation of wind power, and training submodels targets on the distinguished properties in heterogeneous timescales of forecasting, from minutes to days. In addition, feature engineering, imputation techniques and the design of offline evaluation are also described in details. The proposed solution achieves an overall online score of -45.213 in Phase 3.