 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNing Xie
Collective Human Opinions in Semantic Textual Similarity
Aug 08, 2023
Despite the subjective nature of semantic textual similarity (STS) and pervasive disagreements in STS annotation, existing benchmarks have used averaged human ratings as the gold standard. Averaging masks the true distribution of human opinions on examples of low agreement, and prevents models from capturing the semantic vagueness that the individual ratings represent. In this work, we introduce USTS, the first Uncertainty-aware STS dataset with ~15,000 Chinese sentence pairs and 150,000 labels, to study collective human opinions in STS. Analysis reveals that neither a scalar nor a single Gaussian fits a set of observed judgements adequately. We further show that current STS models cannot capture the variance caused by human disagreement on individual instances, but rather reflect the predictive confidence over the aggregate dataset.
* 16 pages, 7 figures
Instance-Variant Loss with Gaussian RBF Kernel for 3D Cross-modal Retriveal
May 07, 2023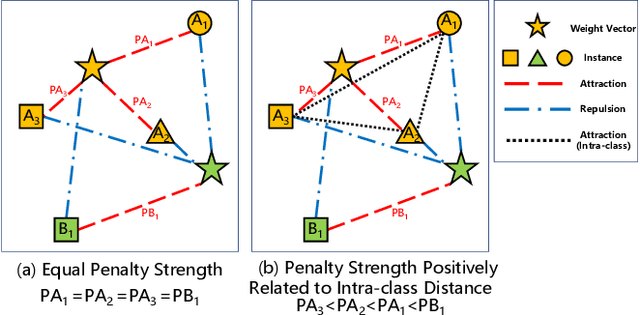


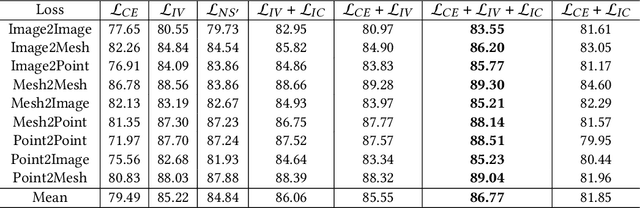
3D cross-modal retrieval is gaining attention in the multimedia community. Central to this topic is learning a joint embedding space to represent data from different modalities, such as images, 3D point clouds, and polygon meshes, to extract modality-invariant and discriminative features. Hence, the performance of cross-modal retrieval methods heavily depends on the representational capacity of this embedding space. Existing methods treat all instances equally, applying the same penalty strength to instances with varying degrees of difficulty, ignoring the differences between instances. This can result in ambiguous convergence or local optima, severely compromising the separability of the feature space. To address this limitation, we propose an Instance-Variant loss to assign different penalty strengths to different instances, improving the space separability. Specifically, we assign different penalty weights to instances positively related to their intra-class distance. Simultaneously, we reduce the cross-modal discrepancy between features by learning a shared weight vector for the same class data from different modalities. By leveraging the Gaussian RBF kernel to evaluate sample similarity, we further propose an Intra-Class loss function that minimizes the intra-class distance among same-class instances. Extensive experiments on three 3D cross-modal datasets show that our proposed method surpasses recent state-of-the-art approaches.
FederatedTrust: A Solution for Trustworthy Federated Learning
Feb 20, 2023
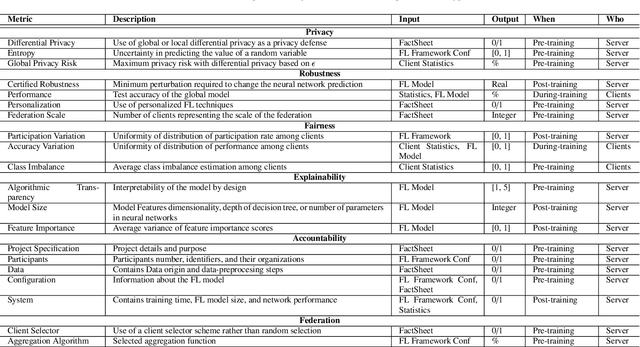
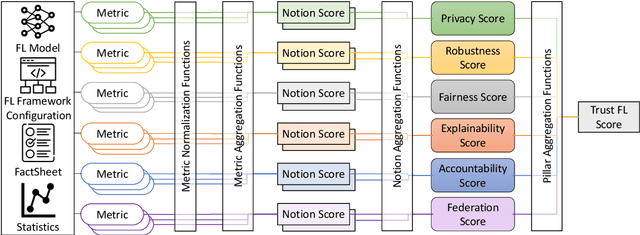
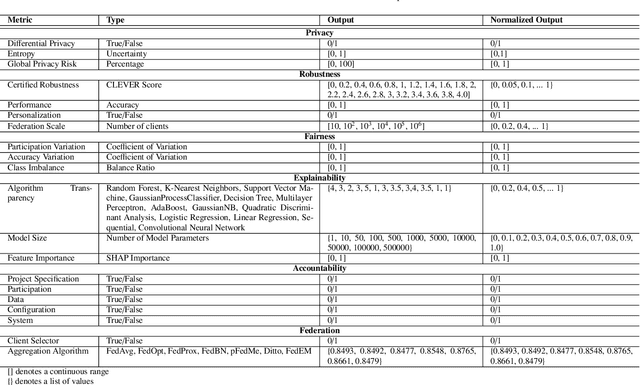
With the ever-widening spread of the Internet of Things (IoT) and Edge Computing paradigms, centralized Machine and Deep Learning (ML/DL) have become challenging due to existing distributed data silos containing sensitive information. The rising concern for data privacy is promoting the development of collaborative and privacy-preserving ML/DL techniques such as Federated Learning (FL). FL enables data privacy by design since the local data of participants are not exposed during the creation of the global and collaborative model. However, data privacy and performance are no longer sufficient, and there is a real necessity to trust model predictions. The literature has proposed some works on trustworthy ML/DL (without data privacy), where robustness, fairness, explainability, and accountability are identified as relevant pillars. However, more efforts are needed to identify trustworthiness pillars and evaluation metrics relevant to FL models and to create solutions computing the trustworthiness level of FL models. Thus, this work analyzes the existing requirements for trustworthiness evaluation in FL and proposes a comprehensive taxonomy of six pillars (privacy, robustness, fairness, explainability, accountability, and federation) with notions and more than 30 metrics for computing the trustworthiness of FL models. Then, an algorithm called FederatedTrust has been designed according to the pillars and metrics identified in the previous taxonomy to compute the trustworthiness score of FL models. A prototype of FederatedTrust has been implemented and deployed into the learning process of FederatedScope, a well-known FL framework. Finally, four experiments performed with different configurations of FederatedScope using the FEMNIST dataset under different federation configurations demonstrated the usefulness of FederatedTrust when computing the trustworthiness of FL models.
Hardness of Maximum Likelihood Learning of DPPs
May 26, 2022
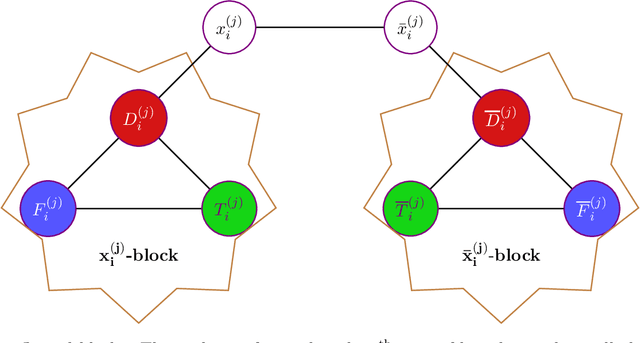

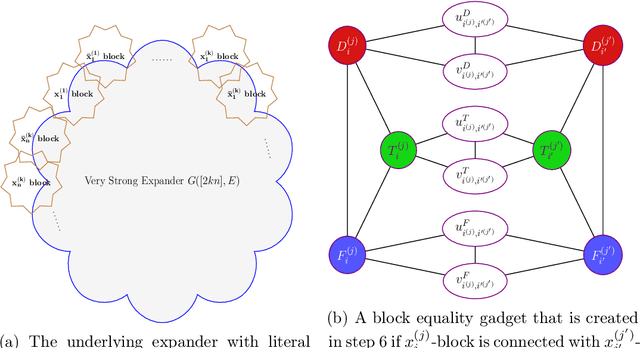
Determinantal Point Processes (DPPs) are a widely used probabilistic model for negatively correlated sets. DPPs have been successfully employed in Machine Learning applications to select a diverse, yet representative subset of data. In seminal work on DPPs in Machine Learning, Kulesza conjectured in his PhD Thesis (2011) that the problem of finding a maximum likelihood DPP model for a given data set is NP-complete. In this work we prove Kulesza's conjecture. In fact, we prove the following stronger hardness of approximation result: even computing a $\left(1-O(\frac{1}{\log^9{N}})\right)$-approximation to the maximum log-likelihood of a DPP on a ground set of $N$ elements is NP-complete. At the same time, we also obtain the first polynomial-time algorithm that achieves a nontrivial worst-case approximation to the optimal log-likelihood: the approximation factor is $\frac{1}{(1+o(1))\log{m}}$ unconditionally (for data sets that consist of $m$ subsets), and can be improved to $1-\frac{1+o(1)}{\log N}$ if all $N$ elements appear in a $O(1/N)$-fraction of the subsets. In terms of techniques, we reduce approximating the maximum log-likelihood of DPPs on a data set to solving a gap instance of a "vector coloring" problem on a hypergraph. Such a hypergraph is built on a bounded-degree graph construction of Bogdanov, Obata and Trevisan (FOCS 2002), and is further enhanced by the strong expanders of Alon and Capalbo (FOCS 2007) to serve our purposes.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 09, 2021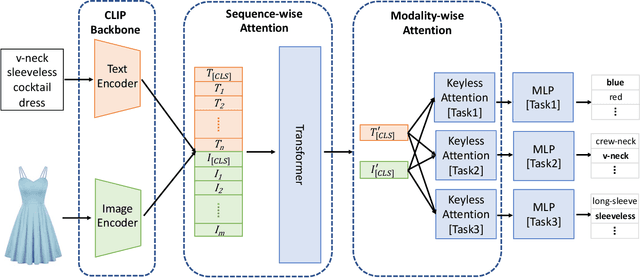

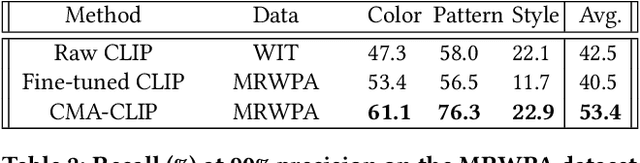

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Application of Deep Self-Attention in Knowledge Tracing
May 23, 2021
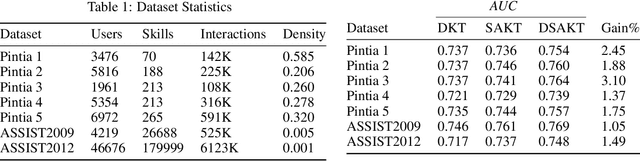


The development of intelligent tutoring system has greatly influenced the way students learn and practice, which increases their learning efficiency. The intelligent tutoring system must model learners' mastery of the knowledge before providing feedback and advices to learners, so one class of algorithm called "knowledge tracing" is surely important. This paper proposed Deep Self-Attentive Knowledge Tracing (DSAKT) based on the data of PTA, an online assessment system used by students in many universities in China, to help these students learn more efficiently. Experimentation on the data of PTA shows that DSAKT outperforms the other models for knowledge tracing an improvement of AUC by 2.1% on average, and this model also has a good performance on the ASSIST dataset.
Deep-VFX: Deep Action Recognition Driven VFX for Short Video
Jul 22, 2020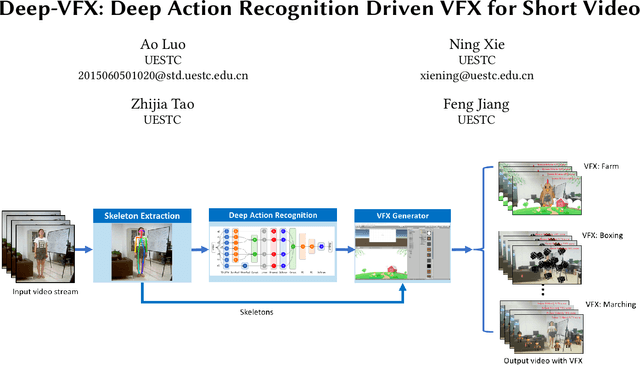
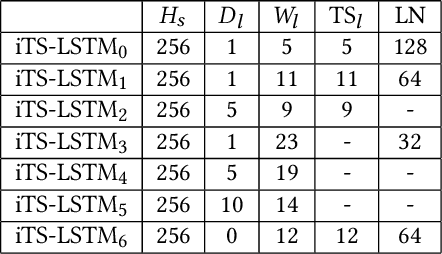
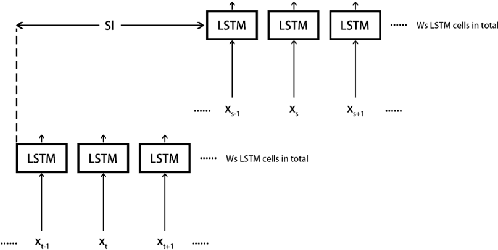
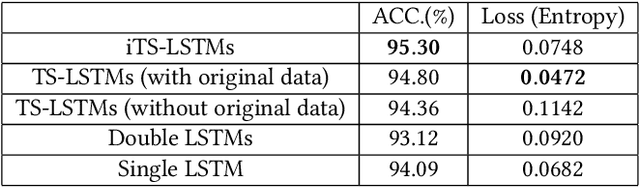
Human motion is a key function to communicate information. In the application, short-form mobile video is so popular all over the world such as Tik Tok. The users would like to add more VFX so as to pursue creativity and personlity. Many special effects are added on the short video platform. These gives the users more possibility to show off these personality. The common and traditional way is to create the template of VFX. However, in order to synthesis the perfect, the users have to tedious attempt to grasp the timing and rhythm of new templates. It is not easy-to-use especially for the mobile app. This paper aims to change the VFX synthesis by motion driven instead of the traditional template matching. We propose the AI method to improve this VFX synthesis. In detail, in order to add the special effect on the human body. The skeleton extraction is essential in this system. We also propose a novel form of LSTM to find out the user's intention by action recognition. The experiment shows that our system enables to generate VFX for short video more easier and efficient.
List Learning with Attribute Noise
Jun 11, 2020We introduce and study the model of list learning with attribute noise. Learning with attribute noise was introduced by Shackelford and Volper (COLT 1988) as a variant of PAC learning, in which the algorithm has access to noisy examples and uncorrupted labels, and the goal is to recover an accurate hypothesis. Sloan (COLT 1988) and Goldman and Sloan (Algorithmica 1995) discovered information-theoretic limits to learning in this model, which have impeded further progress. In this article we extend the model to that of list learning, drawing inspiration from the list-decoding model in coding theory, and its recent variant studied in the context of learning. On the positive side, we show that sparse conjunctions can be efficiently list learned under some assumptions on the underlying ground-truth distribution. On the negative side, our results show that even in the list-learning model, efficient learning of parities and majorities is not possible regardless of the representation used.
Explainable Deep Learning: A Field Guide for the Uninitiated
Apr 30, 2020


Deep neural network (DNN) is an indispensable machine learning tool for achieving human-level performance on many learning tasks. Yet, due to its black-box nature, it is inherently difficult to understand which aspects of the input data drive the decisions of the network. There are various real-world scenarios in which humans need to make actionable decisions based on the output DNNs. Such decision support systems can be found in critical domains, such as legislation, law enforcement, etc. It is important that the humans making high-level decisions can be sure that the DNN decisions are driven by combinations of data features that are appropriate in the context of the deployment of the decision support system and that the decisions made are legally or ethically defensible. Due to the incredible pace at which DNN technology is being developed, the development of new methods and studies on explaining the decision-making process of DNNs has blossomed into an active research field. A practitioner beginning to study explainable deep learning may be intimidated by the plethora of orthogonal directions the field is taking. This complexity is further exacerbated by the general confusion that exists in defining what it means to be able to explain the actions of a deep learning system and to evaluate a system's "ability to explain". To alleviate this problem, this article offers a "field guide" to deep learning explainability for those uninitiated in the field. The field guide: i) Discusses the traits of a deep learning system that researchers enhance in explainability research, ii) places explainability in the context of other related deep learning research areas, and iii) introduces three simple dimensions defining the space of foundational methods that contribute to explainable deep learning. The guide is designed as an easy-to-digest starting point for those just embarking in the field.
Improving Target-driven Visual Navigation with Attention on 3D Spatial Relationships
Apr 29, 2020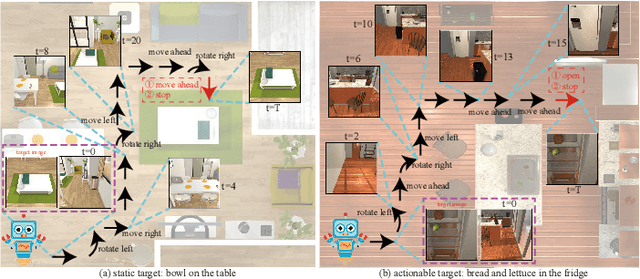
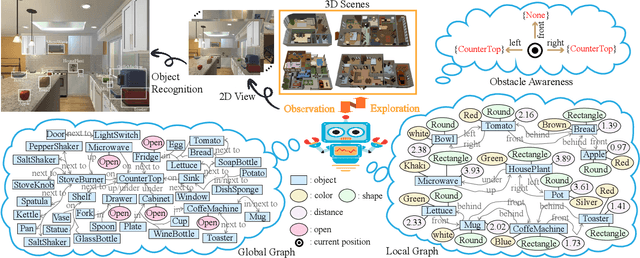
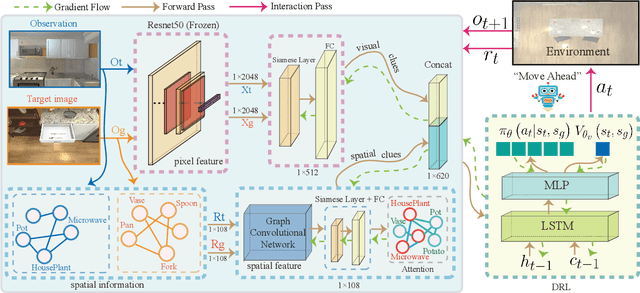
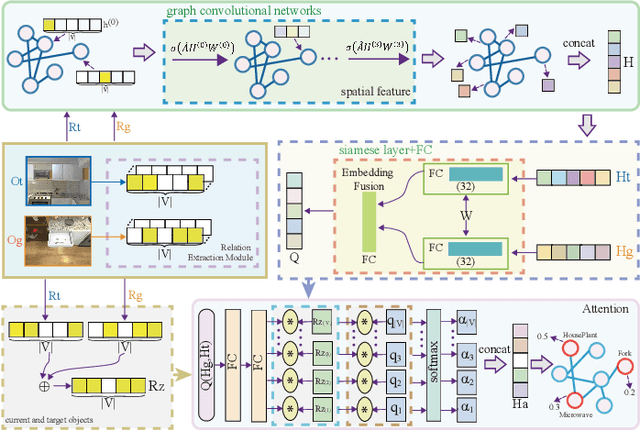
Embodied artificial intelligence (AI) tasks shift from tasks focusing on internet images to active settings involving embodied agents that perceive and act within 3D environments. In this paper, we investigate the target-driven visual navigation using deep reinforcement learning (DRL) in 3D indoor scenes, whose navigation task aims to train an agent that can intelligently make a series of decisions to arrive at a pre-specified target location from any possible starting positions only based on egocentric views. However, most navigation methods currently struggle against several challenging problems, such as data efficiency, automatic obstacle avoidance, and generalization. Generalization problem means that agent does not have the ability to transfer navigation skills learned from previous experience to unseen targets and scenes. To address these issues, we incorporate two designs into classic DRL framework: attention on 3D knowledge graph (KG) and target skill extension (TSE) module. On the one hand, our proposed method combines visual features and 3D spatial representations to learn navigation policy. On the other hand, TSE module is used to generate sub-targets which allow agent to learn from failures. Specifically, our 3D spatial relationships are encoded through recently popular graph convolutional network (GCN). Considering the real world settings, our work also considers open action and adds actionable targets into conventional navigation situations. Those more difficult settings are applied to test whether DRL agent really understand its task, navigating environment, and can carry out reasoning. Our experiments, performed in the AI2-THOR, show that our model outperforms the baselines in both SR and SPL metrics, and improves generalization ability across targets and scenes.