 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeng Jiang
Humans or LLMs as the Judge? A Study on Judgement Biases
Feb 20, 2024
Adopting human and large language models (LLM) as judges (\textit{a.k.a} human- and LLM-as-a-judge) for evaluating the performance of existing LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLM judges, questioning the reliability of the evaluation results. In this paper, we propose a novel framework for investigating 5 types of biases for LLM and human judges. We curate a dataset with 142 samples referring to the revised Bloom's Taxonomy and conduct thousands of human and LLM evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the most cutting-edge judges possess considerable biases. We further exploit their weakness and conduct attacks on LLM judges. We hope that our work can notify the community of the vulnerability of human- and LLM-as-a-judge against perturbations, as well as the urgency of developing robust evaluation systems.
SQL-CRAFT: Text-to-SQL through Interactive Refinement and Enhanced Reasoning
Feb 20, 2024Modern LLMs have become increasingly powerful, but they are still facing challenges in specialized tasks such as Text-to-SQL. We propose SQL-CRAFT, a framework to advance LLMs' SQL generation Capabilities through inteRActive reFinemenT and enhanced reasoning. We leverage an Interactive Correction Loop (IC-Loop) for LLMs to interact with databases automatically, as well as Python-enhanced reasoning. We conduct experiments on two Text-to-SQL datasets, Spider and Bird, with performance improvements of up to 5.7% compared to the naive prompting method. Moreover, our method surpasses the current state-of-the-art on the Spider Leaderboard, demonstrating the effectiveness of our framework.
Segment Any Cell: A SAM-based Auto-prompting Fine-tuning Framework for Nuclei Segmentation
Jan 24, 2024In the rapidly evolving field of AI research, foundational models like BERT and GPT have significantly advanced language and vision tasks. The advent of pretrain-prompting models such as ChatGPT and Segmentation Anything Model (SAM) has further revolutionized image segmentation. However, their applications in specialized areas, particularly in nuclei segmentation within medical imaging, reveal a key challenge: the generation of high-quality, informative prompts is as crucial as applying state-of-the-art (SOTA) fine-tuning techniques on foundation models. To address this, we introduce Segment Any Cell (SAC), an innovative framework that enhances SAM specifically for nuclei segmentation. SAC integrates a Low-Rank Adaptation (LoRA) within the attention layer of the Transformer to improve the fine-tuning process, outperforming existing SOTA methods. It also introduces an innovative auto-prompt generator that produces effective prompts to guide segmentation, a critical factor in handling the complexities of nuclei segmentation in biomedical imaging. Our extensive experiments demonstrate the superiority of SAC in nuclei segmentation tasks, proving its effectiveness as a tool for pathologists and researchers. Our contributions include a novel prompt generation strategy, automated adaptability for diverse segmentation tasks, the innovative application of Low-Rank Attention Adaptation in SAM, and a versatile framework for semantic segmentation challenges.
Bridging Research and Readers: A Multi-Modal Automated Academic Papers Interpretation System
Jan 17, 2024In the contemporary information era, significantly accelerated by the advent of Large-scale Language Models, the proliferation of scientific literature is reaching unprecedented levels. Researchers urgently require efficient tools for reading and summarizing academic papers, uncovering significant scientific literature, and employing diverse interpretative methodologies. To address this burgeoning demand, the role of automated scientific literature interpretation systems has become paramount. However, prevailing models, both commercial and open-source, confront notable challenges: they often overlook multimodal data, grapple with summarizing over-length texts, and lack diverse user interfaces. In response, we introduce an open-source multi-modal automated academic paper interpretation system (MMAPIS) with three-step process stages, incorporating LLMs to augment its functionality. Our system first employs the hybrid modality preprocessing and alignment module to extract plain text, and tables or figures from documents separately. It then aligns this information based on the section names they belong to, ensuring that data with identical section names are categorized under the same section. Following this, we introduce a hierarchical discourse-aware summarization method. It utilizes the extracted section names to divide the article into shorter text segments, facilitating specific summarizations both within and between sections via LLMs with specific prompts. Finally, we have designed four types of diversified user interfaces, including paper recommendation, multimodal Q\&A, audio broadcasting, and interpretation blog, which can be widely applied across various scenarios. Our qualitative and quantitative evaluations underscore the system's superiority, especially in scientific summarization, where it outperforms solutions relying solely on GPT-4.
HuatuoGPT-II, One-stage Training for Medical Adaption of LLMs
Nov 16, 2023Adapting a language model into a specific domain, a.k.a `domain adaption', is a common practice when specialized knowledge, e.g. medicine, is not encapsulated in a general language model like Llama2. The challenge lies in the heterogeneity of data across the two training stages, as it varies in languages, genres, or formats. To tackle this and simplify the learning protocol, we propose to transform heterogeneous data, from the both pre-training and supervised stages, into a unified, simple input-output pair format. We validate the new protocol in the domains where proprietary LLMs like ChatGPT perform relatively poorly, such as Traditional Chinese Medicine. The developed model, HuatuoGPT-II, has shown state-of-the-art performance in Chinese medicine domain on a number of benchmarks, e.g. medical licensing exams. It even outperforms proprietary models like ChatGPT and GPT-4 in some aspects, especially in Traditional Chinese Medicine. Expert manual evaluations further validate HuatuoGPT-II's advantages over existing LLMs. Notably, HuatuoGPT-II was benchmarked in a fresh Chinese National Medical Licensing Examination where it achieved the best performance, showcasing not only its effectiveness but also its generalization capabilities.
Quantify Health-Related Atomic Knowledge in Chinese Medical Large Language Models: A Computational Analysis
Oct 18, 2023Large Language Models (LLMs) have the potential to revolutionize the way users self-diagnose through search engines by offering direct and efficient suggestions. Recent studies primarily focused on the quality of LLMs evaluated by GPT-4 or their ability to pass medical exams, no studies have quantified the extent of health-related atomic knowledge stored in LLMs' memory, which is the basis of LLMs to provide more factual suggestions. In this paper, we first constructed a benchmark, including the most common types of atomic knowledge in user self-diagnosis queries, with 17 atomic types and a total of 14, 048 pieces of atomic knowledge. Then, we evaluated both generic and specialized LLMs on the benchmark. The experimental results showcased that generic LLMs perform better than specialized LLMs in terms of atomic knowledge and instruction-following ability. Error analysis revealed that both generic and specialized LLMs are sycophantic, e.g., always catering to users' claims when it comes to unknown knowledge. Besides, generic LLMs showed stronger safety, which can be learned by specialized LLMs through distilled data. We further explored different types of data commonly adopted for fine-tuning specialized LLMs, i.e., real-world, semi-distilled, and distilled data, and found that distilled data can benefit LLMs most.
Revisiting Multi-modal 3D Semantic Segmentation in Real-world Autonomous Driving
Oct 13, 2023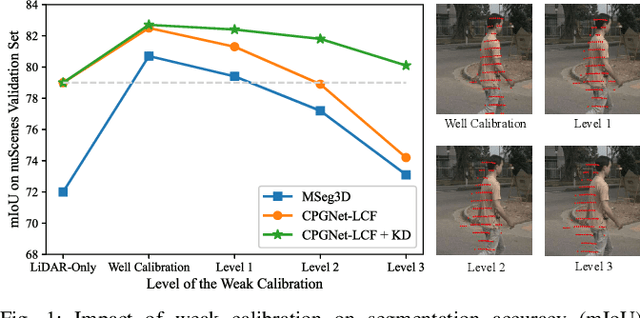
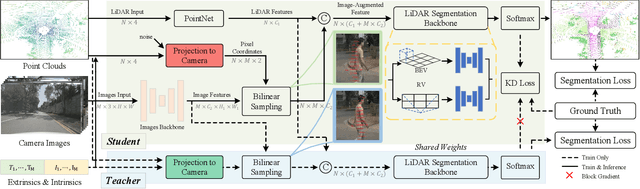
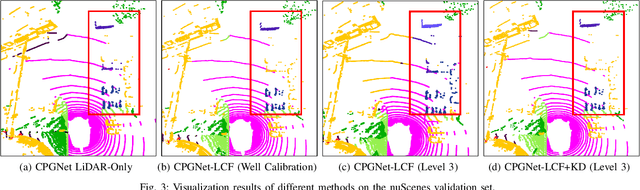
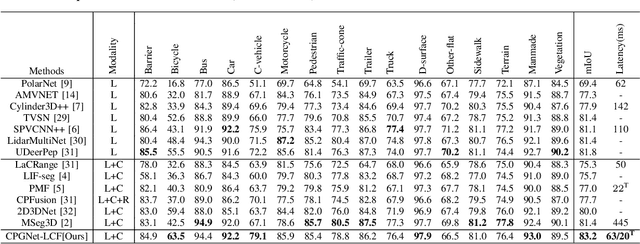
LiDAR and camera are two critical sensors for multi-modal 3D semantic segmentation and are supposed to be fused efficiently and robustly to promise safety in various real-world scenarios. However, existing multi-modal methods face two key challenges: 1) difficulty with efficient deployment and real-time execution; and 2) drastic performance degradation under weak calibration between LiDAR and cameras. To address these challenges, we propose CPGNet-LCF, a new multi-modal fusion framework extending the LiDAR-only CPGNet. CPGNet-LCF solves the first challenge by inheriting the easy deployment and real-time capabilities of CPGNet. For the second challenge, we introduce a novel weak calibration knowledge distillation strategy during training to improve the robustness against the weak calibration. CPGNet-LCF achieves state-of-the-art performance on the nuScenes and SemanticKITTI benchmarks. Remarkably, it can be easily deployed to run in 20ms per frame on a single Tesla V100 GPU using TensorRT TF16 mode. Furthermore, we benchmark performance over four weak calibration levels, demonstrating the robustness of our proposed approach.
BDEC:Brain Deep Embedded Clustering model
Sep 12, 2023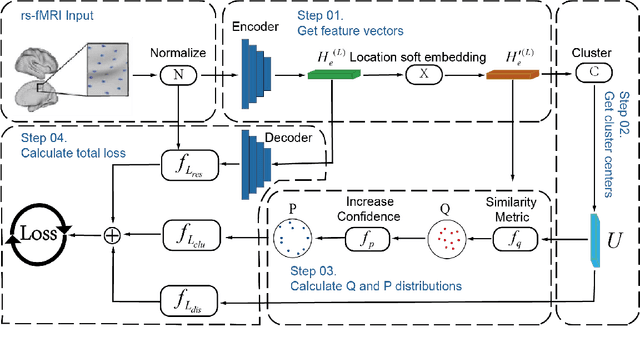
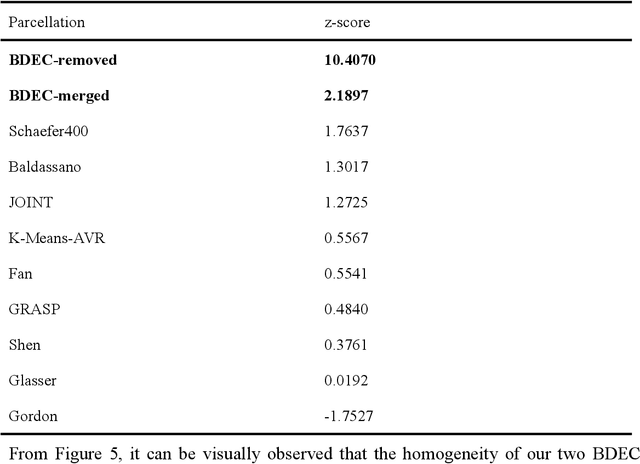
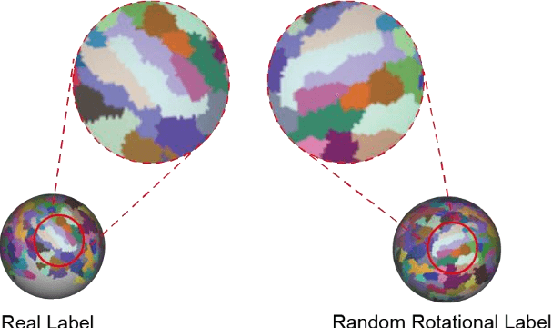
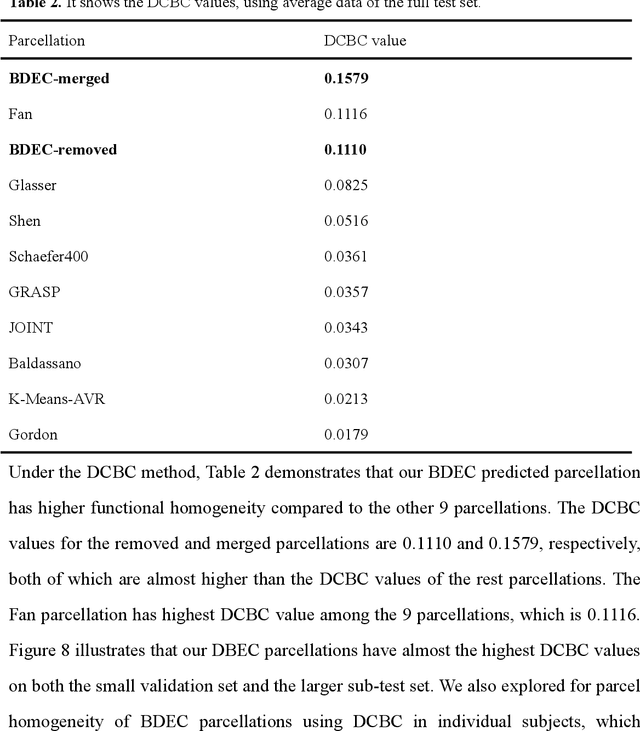
An essential premise for neuroscience brain network analysis is the successful segmentation of the cerebral cortex into functionally homogeneous regions. Resting-state functional magnetic resonance imaging (rs-fMRI), capturing the spontaneous activities of the brain, provides the potential for cortical parcellation. Previous parcellation methods can be roughly categorized into three groups, mainly employing either local gradient, global similarity, or a combination of both. The traditional clustering algorithms, such as "K-means" and "Spectral clustering" may affect the reproducibility or the biological interpretation of parcellations; The region growing-based methods influence the expression of functional homogeneity in the brain at a large scale; The parcellation method based on probabilistic graph models inevitably introduce model assumption biases. In this work, we develop an assumption-free model called as BDEC, which leverages the robust data fitting capability of deep learning. To the best of our knowledge, this is the first study that uses deep learning algorithm for rs-fMRI-based parcellation. By comparing with nine commonly used brain parcellation methods, the BDEC model demonstrates significantly superior performance in various functional homogeneity indicators. Furthermore, it exhibits favorable results in terms of validity, network analysis, task homogeneity, and generalization capability. These results suggest that the BDEC parcellation captures the functional characteristics of the brain and holds promise for future voxel-wise brain network analysis in the dimensionality reduction of fMRI data.
Large Language Model as a User Simulator
Aug 23, 2023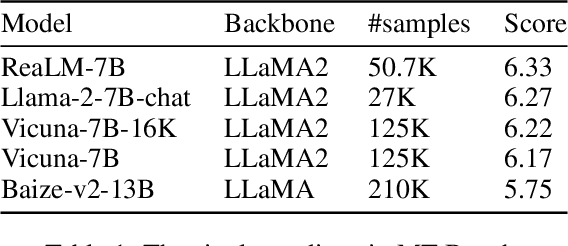
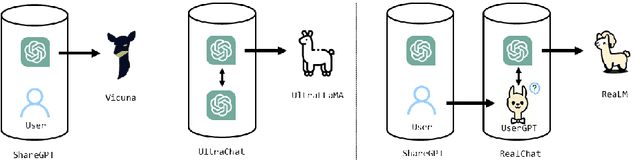

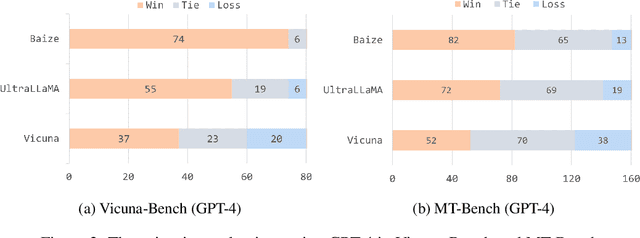
The unparalleled performance of closed-sourced ChatGPT has sparked efforts towards its democratization, with notable strides made by leveraging real user and ChatGPT conversations, as evidenced by Vicuna. However, while current endeavors like Baize and UltraChat aim to auto-generate conversational data due to challenges in gathering human participation, they primarily rely on ChatGPT to simulate human behaviors based on directives rather than genuine human learning. This results in a limited scope, diminished diversity, and an absence of genuine multi-round conversational dynamics. To address the above issues, we innovatively target human questions extracted from genuine human-machine conversations as a learning goal and train a user simulator, UserGPT, to produce a high-quality human-centric synthetic conversation dataset, RealChat. Subsequently, this dataset trains our assistant model, ReaLM. Experimentally, ReaLM outpaces baseline models in both Vicuna-Bench and MT-Bench by pairwise comparison when considering equivalent training set sizes, and manual evaluation also shows that our model is highly competitive. Impressively, when fine-tuned with the latest LLaMA 2 model, ReaLM secured a leading score of 6.33 in the MT-Bench, outshining the contemporary same-scale models, including the LLaMA-2-7B-chat model. Further in-depth analysis demonstrates the scalability and transferability of our approach. A preliminary exploration into the interplay between training set data quality and resultant model performance is also undertaken, laying a robust groundwork for future investigations. The code is available at https://github.com/FreedomIntelligence/ReaLM.