 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNingli Wang
Diagnosis of Multiple Fundus Disorders Amidst a Scarcity of Medical Experts Via Self-supervised Machine Learning
Apr 23, 2024
Fundus diseases are major causes of visual impairment and blindness worldwide, especially in underdeveloped regions, where the shortage of ophthalmologists hinders timely diagnosis. AI-assisted fundus image analysis has several advantages, such as high accuracy, reduced workload, and improved accessibility, but it requires a large amount of expert-annotated data to build reliable models. To address this dilemma, we propose a general self-supervised machine learning framework that can handle diverse fundus diseases from unlabeled fundus images. Our method's AUC surpasses existing supervised approaches by 15.7%, and even exceeds performance of a single human expert. Furthermore, our model adapts well to various datasets from different regions, races, and heterogeneous image sources or qualities from multiple cameras or devices. Our method offers a label-free general framework to diagnose fundus diseases, which could potentially benefit telehealth programs for early screening of people at risk of vision loss.
SSVT: Self-Supervised Vision Transformer For Eye Disease Diagnosis Based On Fundus Images
Apr 20, 2024Machine learning-based fundus image diagnosis technologies trigger worldwide interest owing to their benefits such as reducing medical resource power and providing objective evaluation results. However, current methods are commonly based on supervised methods, bringing in a heavy workload to biomedical staff and hence suffering in expanding effective databases. To address this issue, in this article, we established a label-free method, name 'SSVT',which can automatically analyze un-labeled fundus images and generate high evaluation accuracy of 97.0% of four main eye diseases based on six public datasets and two datasets collected by Beijing Tongren Hospital. The promising results showcased the effectiveness of the proposed unsupervised learning method, and the strong application potential in biomedical resource shortage regions to improve global eye health.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023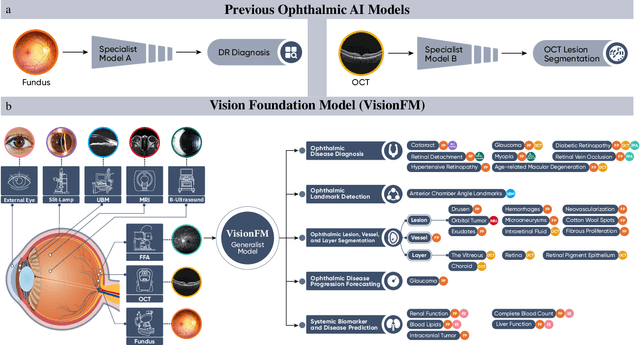
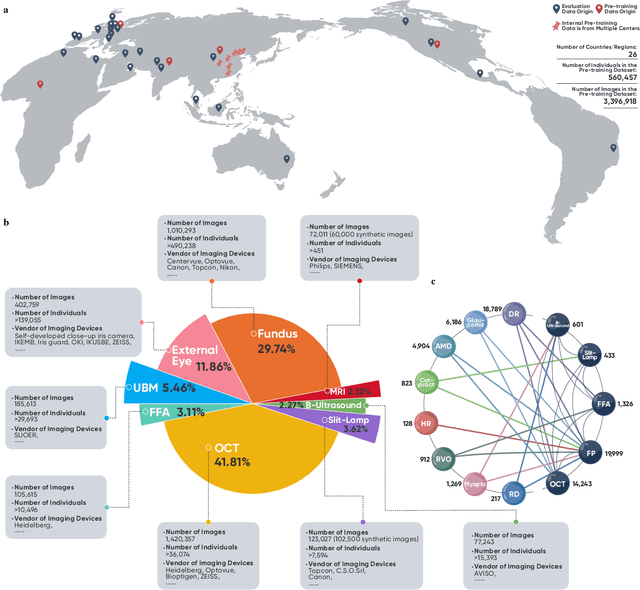
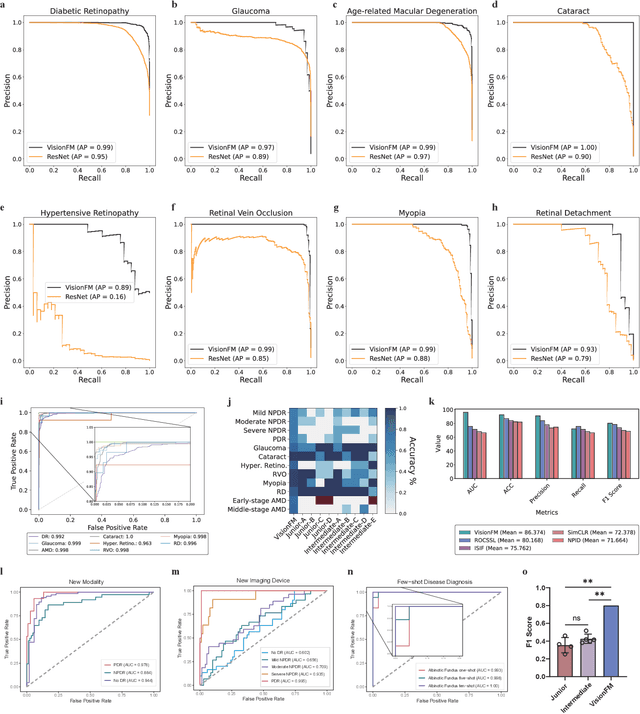
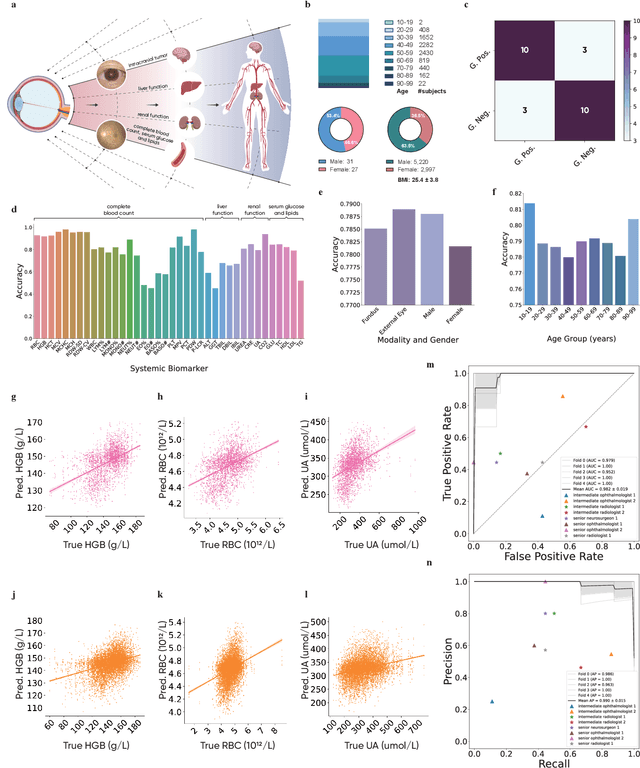
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.