 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrod Razeghi
Discriminative Dimension Reduction based on Mutual Information
Dec 11, 2019
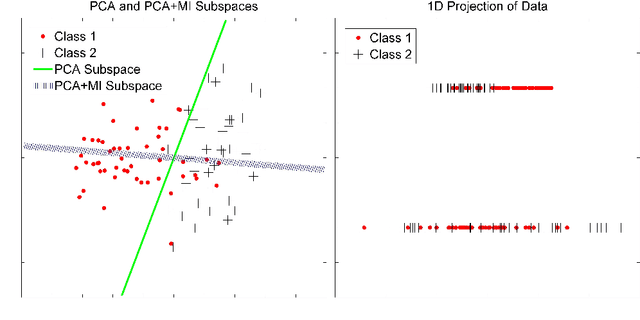
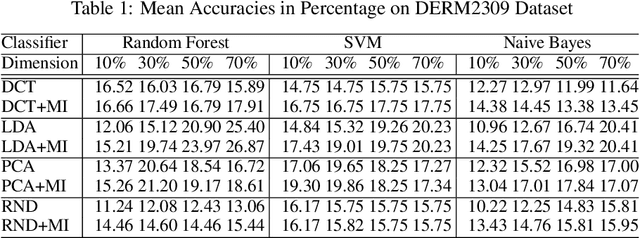
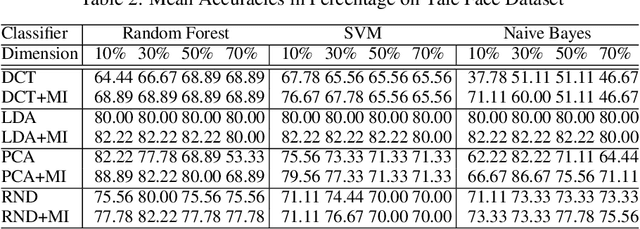
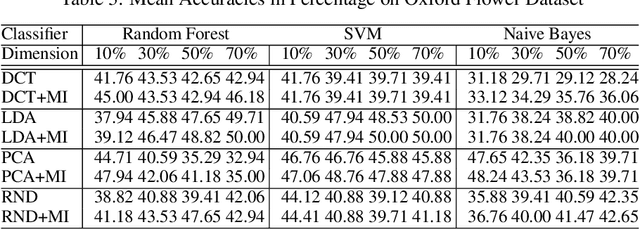
The "curse of dimensionality" is a well-known problem in pattern recognition. A widely used approach to tackling the problem is a group of subspace methods, where the original features are projected onto a new space. The lower dimensional subspace is then used to approximate the original features for classification. However, most subspace methods were not originally developed for classification. We believe that direct adoption of these subspace methods for pattern classification should not be considered best practice. In this paper, we present a new information theory based algorithm for selecting subspaces, which can always result in superior performance over conventional methods. This paper makes the following main contributions: i) it improves a common practice widely used by practitioners in the field of pattern recognition, ii) it develops an information theory based technique for systematically selecting the subspaces that are discriminative and therefore are suitable for pattern recognition/classification purposes, iii) it presents extensive experimental results on a variety of computer vision and pattern recognition tasks to illustrate that the subspaces selected based on maximum mutual information criterion will always enhance performance regardless of the classification techniques used.
Object Recognition with Human in the Loop Intelligent Frameworks
Dec 11, 2019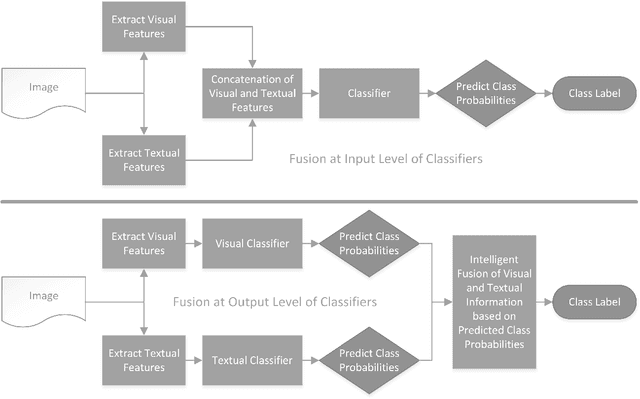
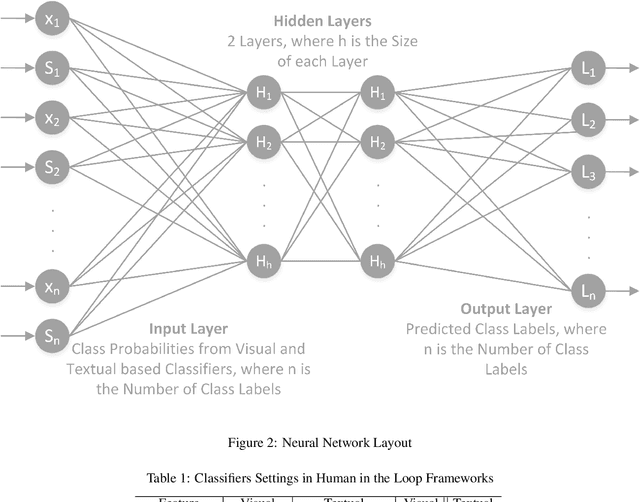
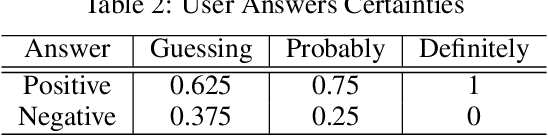
Classifiers embedded within human in the loop visual object recognition frameworks commonly utilise two sources of information: one derived directly from the imagery data of an object, and the other obtained interactively from user interactions. These computer vision frameworks exploit human high-level cognitive power to tackle particularly difficult visual object recognition tasks. In this paper, we present innovative techniques to combine the two sources of information intelligently for the purpose of improving recognition accuracy. We firstly employ standard algorithms to build two classifiers for the two sources independently, and subsequently fuse the outputs from these classifiers to make a conclusive decision. The two fusion techniques proposed are: i) a modified naive Bayes algorithm that adaptively selects an individual classifier's output or combines both to produce a definite answer, and ii) a neural network based algorithm which feeds the outputs of the two classifiers to a 4-layer feedforward network to generate a final output. We present extensive experimental results on 4 challenging visual recognition tasks to illustrate that the new intelligent techniques consistently outperform traditional approaches to fusing the two sources of information.