 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePablo Piantanida
Is Meta-training Really Necessary for Molecular Few-Shot Learning ?
Apr 02, 2024
Few-shot learning has recently attracted significant interest in drug discovery, with a recent, fast-growing literature mostly involving convoluted meta-learning strategies. We revisit the more straightforward fine-tuning approach for molecular data, and propose a regularized quadratic-probe loss based on the the Mahalanobis distance. We design a dedicated block-coordinate descent optimizer, which avoid the degenerate solutions of our loss. Interestingly, our simple fine-tuning approach achieves highly competitive performances in comparison to state-of-the-art methods, while being applicable to black-box settings and removing the need for specific episodic pre-training strategies. Furthermore, we introduce a new benchmark to assess the robustness of the competing methods to domain shifts. In this setting, our fine-tuning baseline obtains consistently better results than meta-learning methods.
$\texttt{COSMIC}$: Mutual Information for Task-Agnostic Summarization Evaluation
Mar 01, 2024Assessing the quality of summarizers poses significant challenges. In response, we propose a novel task-oriented evaluation approach that assesses summarizers based on their capacity to produce summaries that are useful for downstream tasks, while preserving task outcomes. We theoretically establish a direct relationship between the resulting error probability of these tasks and the mutual information between source texts and generated summaries. We introduce $\texttt{COSMIC}$ as a practical implementation of this metric, demonstrating its strong correlation with human judgment-based metrics and its effectiveness in predicting downstream task performance. Comparative analyses against established metrics like $\texttt{BERTScore}$ and $\texttt{ROUGE}$ highlight the competitive performance of $\texttt{COSMIC}$.
Optimal Zero-Shot Detector for Multi-Armed Attacks
Feb 27, 2024This paper explores a scenario in which a malicious actor employs a multi-armed attack strategy to manipulate data samples, offering them various avenues to introduce noise into the dataset. Our central objective is to protect the data by detecting any alterations to the input. We approach this defensive strategy with utmost caution, operating in an environment where the defender possesses significantly less information compared to the attacker. Specifically, the defender is unable to utilize any data samples for training a defense model or verifying the integrity of the channel. Instead, the defender relies exclusively on a set of pre-existing detectors readily available "off the shelf". To tackle this challenge, we derive an innovative information-theoretic defense approach that optimally aggregates the decisions made by these detectors, eliminating the need for any training data. We further explore a practical use-case scenario for empirical evaluation, where the attacker possesses a pre-trained classifier and launches well-known adversarial attacks against it. Our experiments highlight the effectiveness of our proposed solution, even in scenarios that deviate from the optimal setup.
On the Convergence of Semi Unsupervised Calibration through Prior Adaptation Algorithm
Jan 05, 2024Calibration is an essential key in machine leaning. Semi Unsupervised Calibration through Prior Adaptation (SUCPA) is a calibration algorithm used in (but not limited to) large-scale language models defined by a {system of first-order difference equation. The map derived by this system} has the peculiarity of being non-hyperbolic {with a non-bounded set of non-isolated fixed points}. In this work, we prove several convergence properties of this algorithm from the perspective of dynamical systems. For a binary classification problem, it can be shown that the algorithm always converges, {more precisely, the map is globally asymptotically stable, and the orbits converge} to a single line of fixed points. Finally, we perform numerical experiments on real-world application to support the presented results. Experiment codes are available online.
Preserving Privacy in GANs Against Membership Inference Attack
Nov 06, 2023Generative Adversarial Networks (GANs) have been widely used for generating synthetic data for cases where there is a limited size real-world dataset or when data holders are unwilling to share their data samples. Recent works showed that GANs, due to overfitting and memorization, might leak information regarding their training data samples. This makes GANs vulnerable to Membership Inference Attacks (MIAs). Several defense strategies have been proposed in the literature to mitigate this privacy issue. Unfortunately, defense strategies based on differential privacy are proven to reduce extensively the quality of the synthetic data points. On the other hand, more recent frameworks such as PrivGAN and PAR-GAN are not suitable for small-size training datasets. In the present work, the overfitting in GANs is studied in terms of the discriminator, and a more general measure of overfitting based on the Bhattacharyya coefficient is defined. Then, inspired by Fano's inequality, our first defense mechanism against MIAs is proposed. This framework, which requires only a simple modification in the loss function of GANs, is referred to as the maximum entropy GAN or MEGAN and significantly improves the robustness of GANs to MIAs. As a second defense strategy, a more heuristic model based on minimizing the information leaked from generated samples about the training data points is presented. This approach is referred to as mutual information minimization GAN (MIMGAN) and uses a variational representation of the mutual information to minimize the information that a synthetic sample might leak about the whole training data set. Applying the proposed frameworks to some commonly used data sets against state-of-the-art MIAs reveals that the proposed methods can reduce the accuracy of the adversaries to the level of random guessing accuracy with a small reduction in the quality of the synthetic data samples.
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Oct 27, 2023Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article explores the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. Then, we investigate several situations for which we provide bounds on this quantity of interest. This allows us to infer the accuracy of potential attacks as a function of the number of samples and other structural parameters of learning models, which in some cases can be directly estimated from the dataset.
Transductive Learning for Textual Few-Shot Classification in API-based Embedding Models
Oct 21, 2023



Proprietary and closed APIs are becoming increasingly common to process natural language, and are impacting the practical applications of natural language processing, including few-shot classification. Few-shot classification involves training a model to perform a new classification task with a handful of labeled data. This paper presents three contributions. First, we introduce a scenario where the embedding of a pre-trained model is served through a gated API with compute-cost and data-privacy constraints. Second, we propose a transductive inference, a learning paradigm that has been overlooked by the NLP community. Transductive inference, unlike traditional inductive learning, leverages the statistics of unlabeled data. We also introduce a new parameter-free transductive regularizer based on the Fisher-Rao loss, which can be used on top of the gated API embeddings. This method fully utilizes unlabeled data, does not share any label with the third-party API provider and could serve as a baseline for future research. Third, we propose an improved experimental setting and compile a benchmark of eight datasets involving multiclass classification in four different languages, with up to 151 classes. We evaluate our methods using eight backbone models, along with an episodic evaluation over 1,000 episodes, which demonstrate the superiority of transductive inference over the standard inductive setting.
Toward Stronger Textual Attack Detectors
Oct 21, 2023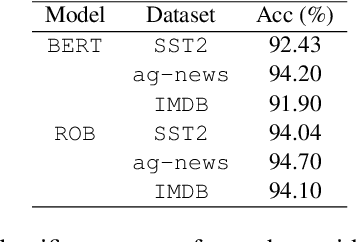
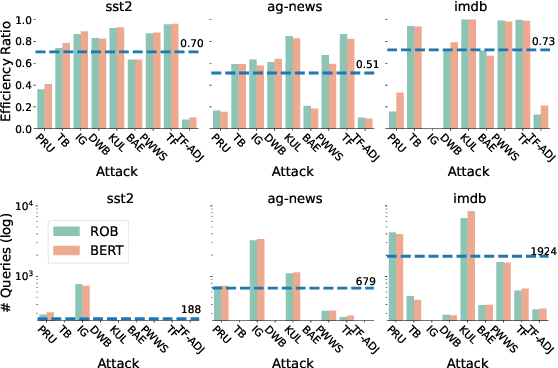
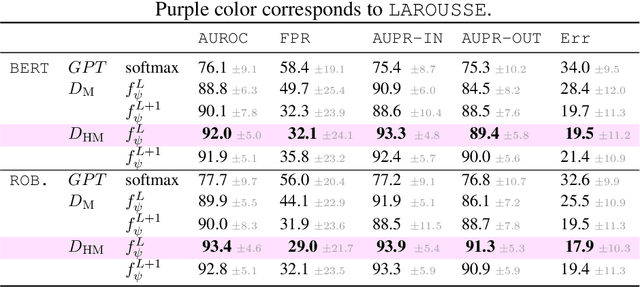
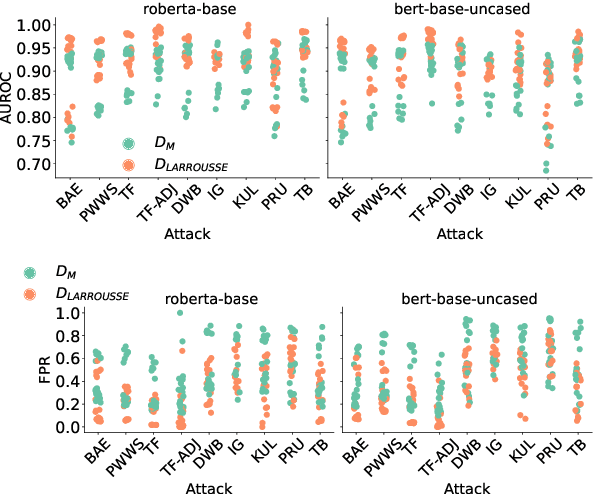
The landscape of available textual adversarial attacks keeps growing, posing severe threats and raising concerns regarding the deep NLP system's integrity. However, the crucial problem of defending against malicious attacks has only drawn the attention of the NLP community. The latter is nonetheless instrumental in developing robust and trustworthy systems. This paper makes two important contributions in this line of search: (i) we introduce LAROUSSE, a new framework to detect textual adversarial attacks and (ii) we introduce STAKEOUT, a new benchmark composed of nine popular attack methods, three datasets, and two pre-trained models. LAROUSSE is ready-to-use in production as it is unsupervised, hyperparameter-free, and non-differentiable, protecting it against gradient-based methods. Our new benchmark STAKEOUT allows for a robust evaluation framework: we conduct extensive numerical experiments which demonstrate that LAROUSSE outperforms previous methods, and which allows to identify interesting factors of detection rate variations.
A Novel Information-Theoretic Objective to Disentangle Representations for Fair Classification
Oct 21, 2023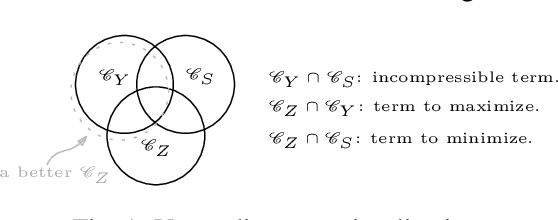
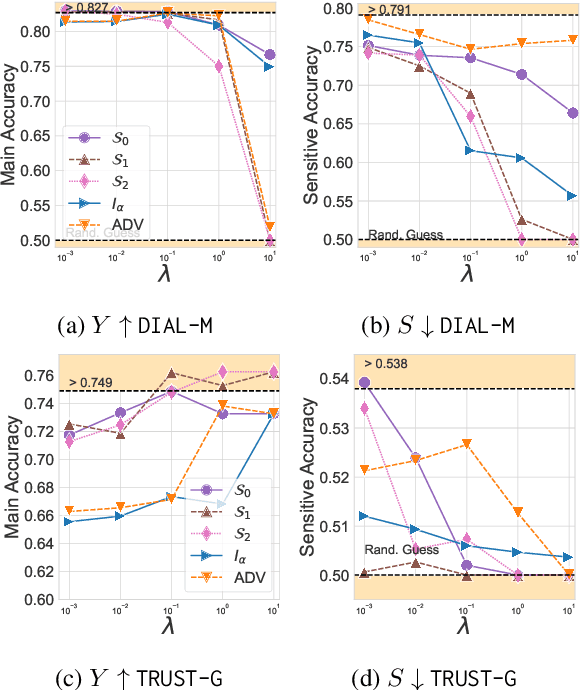
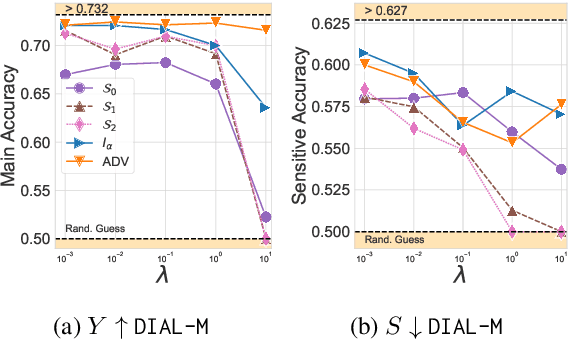
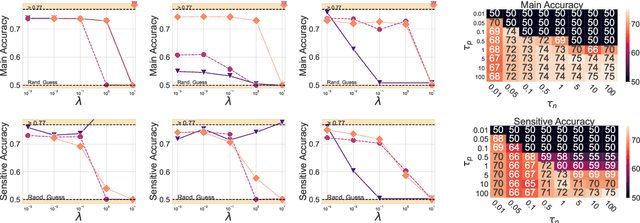
One of the pursued objectives of deep learning is to provide tools that learn abstract representations of reality from the observation of multiple contextual situations. More precisely, one wishes to extract disentangled representations which are (i) low dimensional and (ii) whose components are independent and correspond to concepts capturing the essence of the objects under consideration (Locatello et al., 2019b). One step towards this ambitious project consists in learning disentangled representations with respect to a predefined (sensitive) attribute, e.g., the gender or age of the writer. Perhaps one of the main application for such disentangled representations is fair classification. Existing methods extract the last layer of a neural network trained with a loss that is composed of a cross-entropy objective and a disentanglement regularizer. In this work, we adopt an information-theoretic view of this problem which motivates a novel family of regularizers that minimizes the mutual information between the latent representation and the sensitive attribute conditional to the target. The resulting set of losses, called CLINIC, is parameter free and thus, it is easier and faster to train. CLINIC losses are studied through extensive numerical experiments by training over 2k neural networks. We demonstrate that our methods offer a better disentanglement/accuracy trade-off than previous techniques, and generalize better than training with cross-entropy loss solely provided that the disentanglement task is not too constraining.
A Functional Data Perspective and Baseline On Multi-Layer Out-of-Distribution Detection
Jun 06, 2023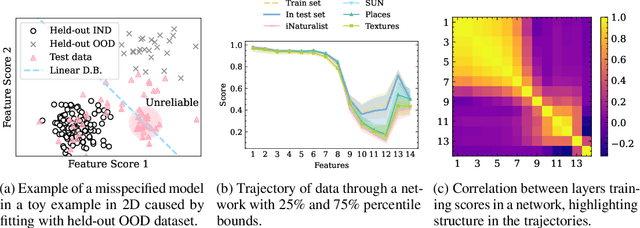
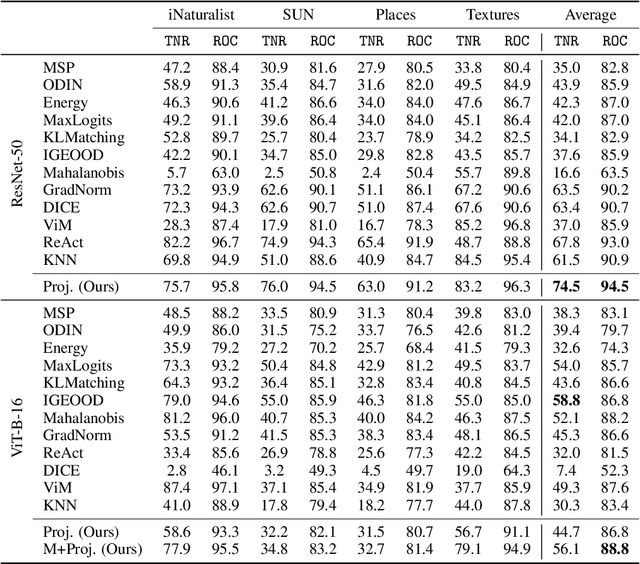

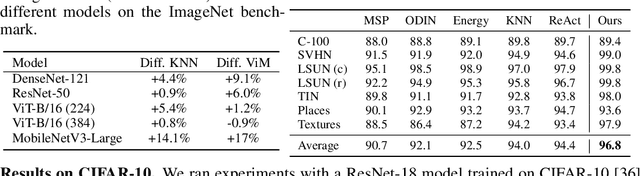
A key feature of out-of-distribution (OOD) detection is to exploit a trained neural network by extracting statistical patterns and relationships through the multi-layer classifier to detect shifts in the expected input data distribution. Despite achieving solid results, several state-of-the-art methods rely on the penultimate or last layer outputs only, leaving behind valuable information for OOD detection. Methods that explore the multiple layers either require a special architecture or a supervised objective to do so. This work adopts an original approach based on a functional view of the network that exploits the sample's trajectories through the various layers and their statistical dependencies. It goes beyond multivariate features aggregation and introduces a baseline rooted in functional anomaly detection. In this new framework, OOD detection translates into detecting samples whose trajectories differ from the typical behavior characterized by the training set. We validate our method and empirically demonstrate its effectiveness in OOD detection compared to strong state-of-the-art baselines on computer vision benchmarks.