 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsmail Ben Ayed
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning?
May 03, 2024
The development of large vision-language models, notably CLIP, has catalyzed research into effective adaptation techniques, with a particular focus on soft prompt tuning. Conjointly, test-time augmentation, which utilizes multiple augmented views of a single image to enhance zero-shot generalization, is emerging as a significant area of interest. This has predominantly directed research efforts toward test-time prompt tuning. In contrast, we introduce a robust MeanShift for Test-time Augmentation (MTA), which surpasses prompt-based methods without requiring this intensive training procedure. This positions MTA as an ideal solution for both standalone and API-based applications. Additionally, our method does not rely on ad hoc rules (e.g., confidence threshold) used in some previous test-time augmentation techniques to filter the augmented views. Instead, MTA incorporates a quality assessment variable for each view directly into its optimization process, termed as the inlierness score. This score is jointly optimized with a density mode seeking process, leading to an efficient training- and hyperparameter-free approach. We extensively benchmark our method on 15 datasets and demonstrate MTA's superiority and computational efficiency. Deployed easily as plug-and-play module on top of zero-shot models and state-of-the-art few-shot methods, MTA shows systematic and consistent improvements.
CLIPArTT: Light-weight Adaptation of CLIP to New Domains at Test Time
May 01, 2024Pre-trained vision-language models (VLMs), exemplified by CLIP, demonstrate remarkable adaptability across zero-shot classification tasks without additional training. However, their performance diminishes in the presence of domain shifts. In this study, we introduce CLIP Adaptation duRing Test-Time (CLIPArTT), a fully test-time adaptation (TTA) approach for CLIP, which involves automatic text prompts construction during inference for their use as text supervision. Our method employs a unique, minimally invasive text prompt tuning process, wherein multiple predicted classes are aggregated into a single new text prompt, used as pseudo label to re-classify inputs in a transductive manner. Additionally, we pioneer the standardization of TTA benchmarks (e.g., TENT) in the realm of VLMs. Our findings demonstrate that, without requiring additional transformations nor new trainable modules, CLIPArTT enhances performance dynamically across non-corrupted datasets such as CIFAR-10, corrupted datasets like CIFAR-10-C and CIFAR-10.1, alongside synthetic datasets such as VisDA-C. This research underscores the potential for improving VLMs' adaptability through novel test-time strategies, offering insights for robust performance across varied datasets and environments. The code can be found at: https://github.com/dosowiechi/CLIPArTT.git
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Apr 12, 2024Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
NC-TTT: A Noise Contrastive Approach for Test-Time Training
Apr 12, 2024Despite their exceptional performance in vision tasks, deep learning models often struggle when faced with domain shifts during testing. Test-Time Training (TTT) methods have recently gained popularity by their ability to enhance the robustness of models through the addition of an auxiliary objective that is jointly optimized with the main task. Being strictly unsupervised, this auxiliary objective is used at test time to adapt the model without any access to labels. In this work, we propose Noise-Contrastive Test-Time Training (NC-TTT), a novel unsupervised TTT technique based on the discrimination of noisy feature maps. By learning to classify noisy views of projected feature maps, and then adapting the model accordingly on new domains, classification performance can be recovered by an important margin. Experiments on several popular test-time adaptation baselines demonstrate the advantages of our method compared to recent approaches for this task. The code can be found at:https://github.com/GustavoVargasHakim/NCTTT.git
Is Meta-training Really Necessary for Molecular Few-Shot Learning ?
Apr 02, 2024Few-shot learning has recently attracted significant interest in drug discovery, with a recent, fast-growing literature mostly involving convoluted meta-learning strategies. We revisit the more straightforward fine-tuning approach for molecular data, and propose a regularized quadratic-probe loss based on the the Mahalanobis distance. We design a dedicated block-coordinate descent optimizer, which avoid the degenerate solutions of our loss. Interestingly, our simple fine-tuning approach achieves highly competitive performances in comparison to state-of-the-art methods, while being applicable to black-box settings and removing the need for specific episodic pre-training strategies. Furthermore, we introduce a new benchmark to assess the robustness of the competing methods to domain shifts. In this setting, our fine-tuning baseline obtains consistently better results than meta-learning methods.
LP++: A Surprisingly Strong Linear Probe for Few-Shot CLIP
Apr 02, 2024In a recent, strongly emergent literature on few-shot CLIP adaptation, Linear Probe (LP) has been often reported as a weak baseline. This has motivated intensive research building convoluted prompt learning or feature adaptation strategies. In this work, we propose and examine from convex-optimization perspectives a generalization of the standard LP baseline, in which the linear classifier weights are learnable functions of the text embedding, with class-wise multipliers blending image and text knowledge. As our objective function depends on two types of variables, i.e., the class visual prototypes and the learnable blending parameters, we propose a computationally efficient block coordinate Majorize-Minimize (MM) descent algorithm. In our full-batch MM optimizer, which we coin LP++, step sizes are implicit, unlike standard gradient descent practices where learning rates are intensively searched over validation sets. By examining the mathematical properties of our loss (e.g., Lipschitz gradient continuity), we build majorizing functions yielding data-driven learning rates and derive approximations of the loss's minima, which provide data-informed initialization of the variables. Our image-language objective function, along with these non-trivial optimization insights and ingredients, yields, surprisingly, highly competitive few-shot CLIP performances. Furthermore, LP++ operates in black-box, relaxes intensive validation searches for the optimization hyper-parameters, and runs orders-of-magnitudes faster than state-of-the-art few-shot CLIP adaptation methods. Our code is available at: \url{https://github.com/FereshteShakeri/FewShot-CLIP-Strong-Baseline.git}.
Do not trust what you trust: Miscalibration in Semi-supervised Learning
Mar 22, 2024State-of-the-art semi-supervised learning (SSL) approaches rely on highly confident predictions to serve as pseudo-labels that guide the training on unlabeled samples. An inherent drawback of this strategy stems from the quality of the uncertainty estimates, as pseudo-labels are filtered only based on their degree of uncertainty, regardless of the correctness of their predictions. Thus, assessing and enhancing the uncertainty of network predictions is of paramount importance in the pseudo-labeling process. In this work, we empirically demonstrate that SSL methods based on pseudo-labels are significantly miscalibrated, and formally demonstrate the minimization of the min-entropy, a lower bound of the Shannon entropy, as a potential cause for miscalibration. To alleviate this issue, we integrate a simple penalty term, which enforces the logit distances of the predictions on unlabeled samples to remain low, preventing the network predictions to become overconfident. Comprehensive experiments on a variety of SSL image classification benchmarks demonstrate that the proposed solution systematically improves the calibration performance of relevant SSL models, while also enhancing their discriminative power, being an appealing addition to tackle SSL tasks.
Class and Region-Adaptive Constraints for Network Calibration
Mar 19, 2024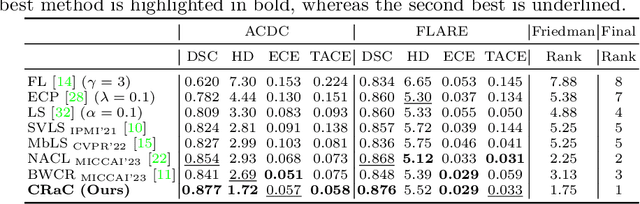
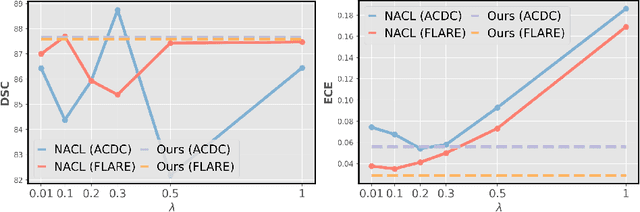
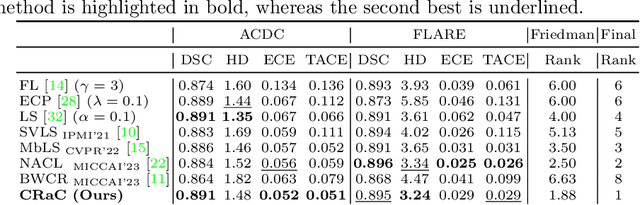
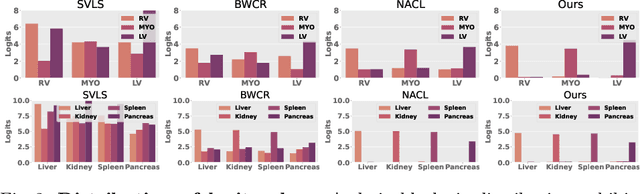
In this work, we present a novel approach to calibrate segmentation networks that considers the inherent challenges posed by different categories and object regions. In particular, we present a formulation that integrates class and region-wise constraints into the learning objective, with multiple penalty weights to account for class and region differences. Finding the optimal penalty weights manually, however, might be unfeasible, and potentially hinder the optimization process. To overcome this limitation, we propose an approach based on Class and Region-Adaptive constraints (CRaC), which allows to learn the class and region-wise penalty weights during training. CRaC is based on a general Augmented Lagrangian method, a well-established technique in constrained optimization. Experimental results on two popular segmentation benchmarks, and two well-known segmentation networks, demonstrate the superiority of CRaC compared to existing approaches. The code is available at: https://github.com/Bala93/CRac/
Exploring the Transferability of a Foundation Model for Fundus Images: Application to Hypertensive Retinopathy
Jan 27, 2024Using deep learning models pre-trained on Imagenet is the traditional solution for medical image classification to deal with data scarcity. Nevertheless, relevant literature supports that this strategy may offer limited gains due to the high dissimilarity between domains. Currently, the paradigm of adapting domain-specialized foundation models is proving to be a promising alternative. However, how to perform such knowledge transfer, and the benefits and limitations it presents, are under study. The CGI-HRDC challenge for Hypertensive Retinopathy diagnosis on fundus images introduces an appealing opportunity to evaluate the transferability of a recently released vision-language foundation model of the retina, FLAIR. In this work, we explore the potential of using FLAIR features as starting point for fundus image classification, and we compare its performance with regard to Imagenet initialization on two popular transfer learning methods: Linear Probing (LP) and Fine-Tuning (FP). Our empirical observations suggest that, in any case, the use of the traditional strategy provides performance gains. In contrast, direct transferability from FLAIR model allows gains of 2.5%. When fine-tuning the whole network, the performance gap increases up to 4%. In this case, we show that avoiding feature deterioration via LP initialization of the classifier allows the best re-use of the rich pre-trained features. Although direct transferability using LP still offers limited performance, we believe that foundation models such as FLAIR will drive the evolution of deep-learning-based fundus image analysis.