 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntonio Emanuele Cinà
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024
Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
$σ$-zero: Gradient-based Optimization of $\ell_0$-norm Adversarial Examples
Feb 02, 2024Evaluating the adversarial robustness of deep networks to gradient-based attacks is challenging. While most attacks consider $\ell_2$- and $\ell_\infty$-norm constraints to craft input perturbations, only a few investigate sparse $\ell_1$- and $\ell_0$-norm attacks. In particular, $\ell_0$-norm attacks remain the least studied due to the inherent complexity of optimizing over a non-convex and non-differentiable constraint. However, evaluating adversarial robustness under these attacks could reveal weaknesses otherwise left untested with more conventional $\ell_2$- and $\ell_\infty$-norm attacks. In this work, we propose a novel $\ell_0$-norm attack, called $\sigma$-zero, which leverages an ad hoc differentiable approximation of the $\ell_0$ norm to facilitate gradient-based optimization, and an adaptive projection operator to dynamically adjust the trade-off between loss minimization and perturbation sparsity. Extensive evaluations using MNIST, CIFAR10, and ImageNet datasets, involving robust and non-robust models, show that $\sigma$-zero finds minimum $\ell_0$-norm adversarial examples without requiring any time-consuming hyperparameter tuning, and that it outperforms all competing sparse attacks in terms of success rate, perturbation size, and scalability.
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023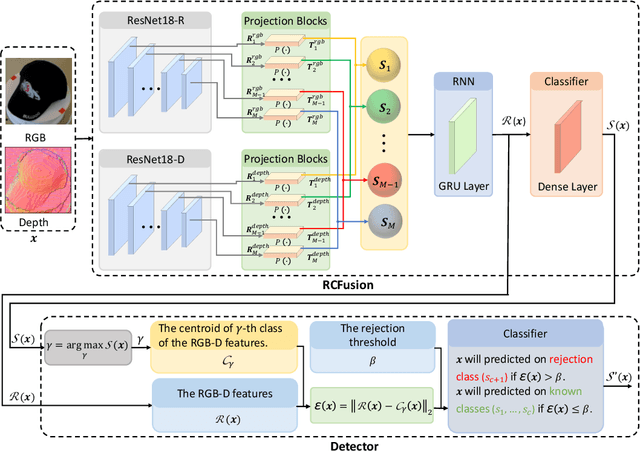
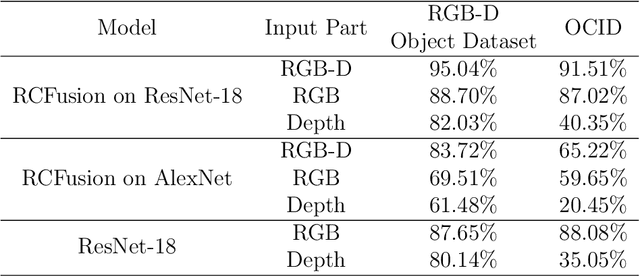
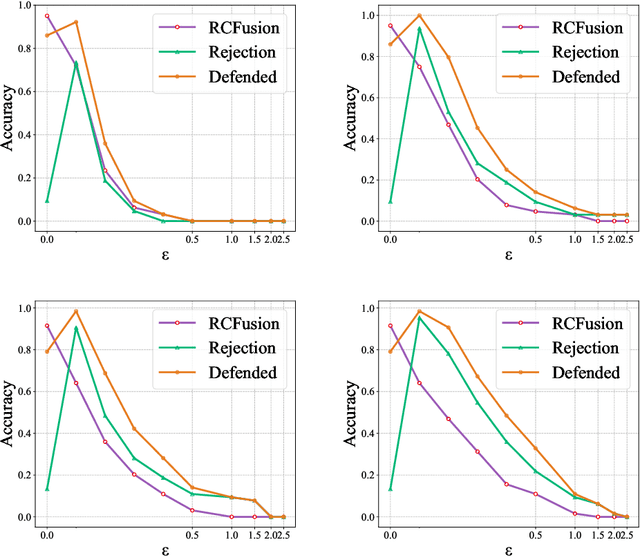
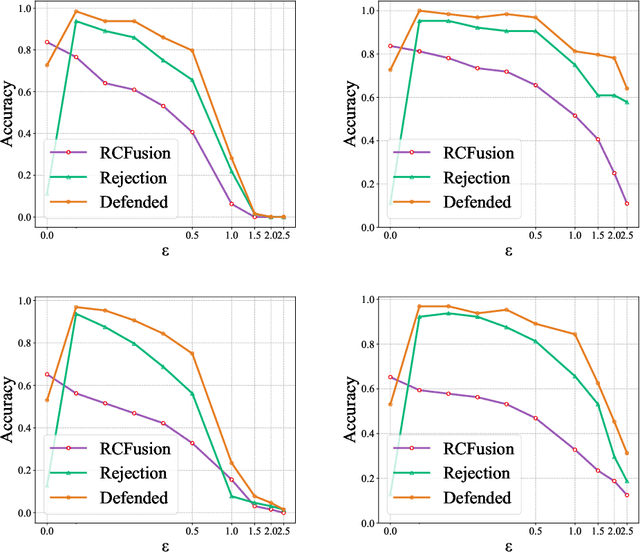
RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.
Minimizing Energy Consumption of Deep Learning Models by Energy-Aware Training
Jul 01, 2023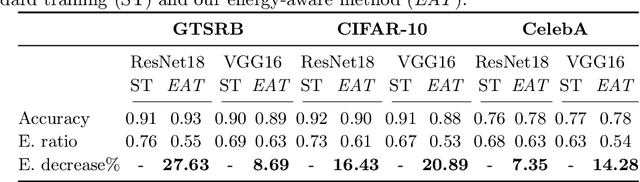
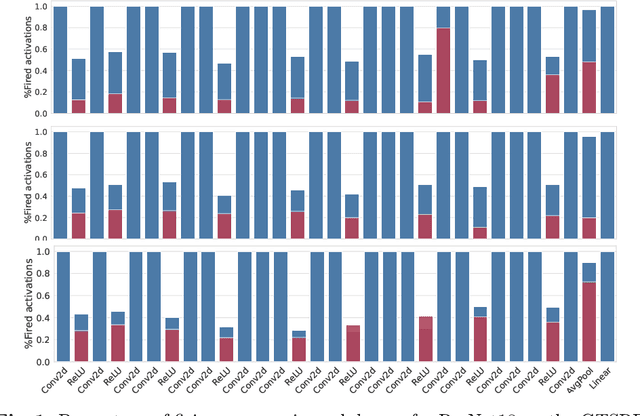
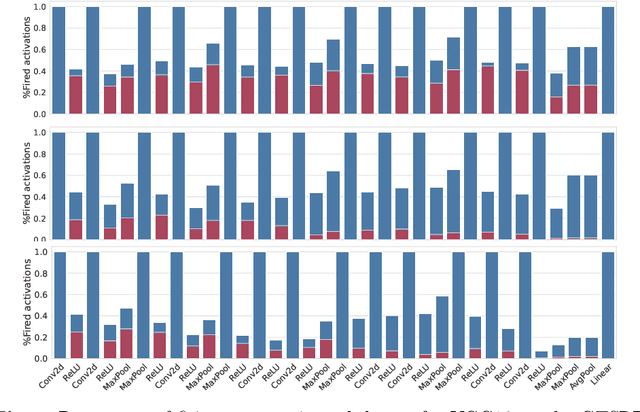
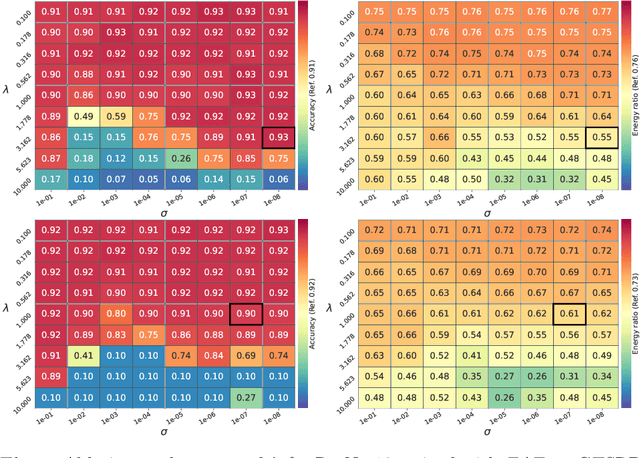
Deep learning models undergo a significant increase in the number of parameters they possess, leading to the execution of a larger number of operations during inference. This expansion significantly contributes to higher energy consumption and prediction latency. In this work, we propose EAT, a gradient-based algorithm that aims to reduce energy consumption during model training. To this end, we leverage a differentiable approximation of the $\ell_0$ norm, and use it as a sparse penalty over the training loss. Through our experimental analysis conducted on three datasets and two deep neural networks, we demonstrate that our energy-aware training algorithm EAT is able to train networks with a better trade-off between classification performance and energy efficiency.
On the Limitations of Model Stealing with Uncertainty Quantification Models
May 09, 2023
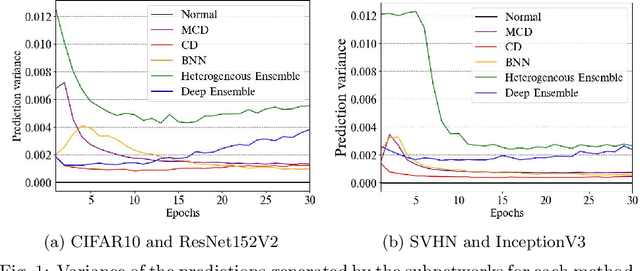

Model stealing aims at inferring a victim model's functionality at a fraction of the original training cost. While the goal is clear, in practice the model's architecture, weight dimension, and original training data can not be determined exactly, leading to mutual uncertainty during stealing. In this work, we explicitly tackle this uncertainty by generating multiple possible networks and combining their predictions to improve the quality of the stolen model. For this, we compare five popular uncertainty quantification models in a model stealing task. Surprisingly, our results indicate that the considered models only lead to marginal improvements in terms of label agreement (i.e., fidelity) to the stolen model. To find the cause of this, we inspect the diversity of the model's prediction by looking at the prediction variance as a function of training iterations. We realize that during training, the models tend to have similar predictions, indicating that the network diversity we wanted to leverage using uncertainty quantification models is not (high) enough for improvements on the model stealing task.
Wild Patterns Reloaded: A Survey of Machine Learning Security against Training Data Poisoning
May 04, 2022
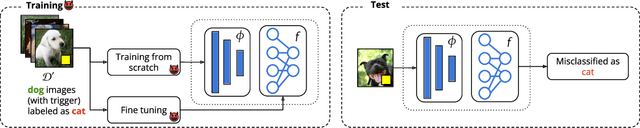

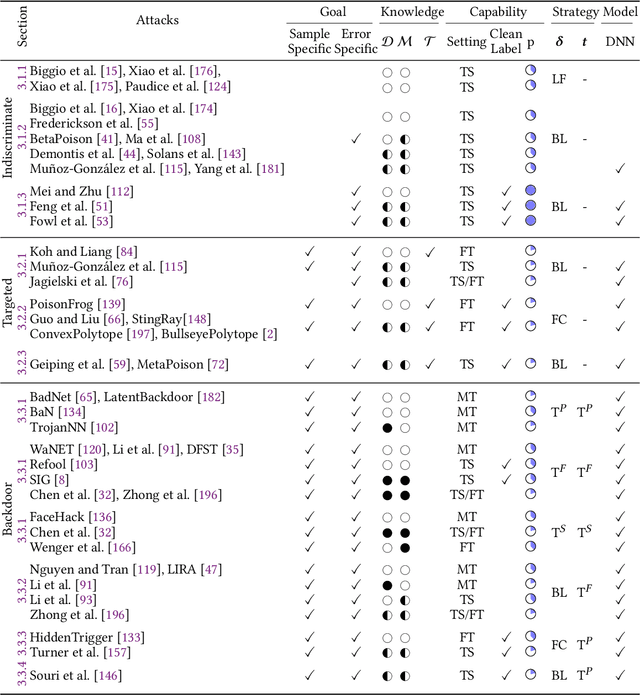
The success of machine learning is fueled by the increasing availability of computing power and large training datasets. The training data is used to learn new models or update existing ones, assuming that it is sufficiently representative of the data that will be encountered at test time. This assumption is challenged by the threat of poisoning, an attack that manipulates the training data to compromise the model's performance at test time. Although poisoning has been acknowledged as a relevant threat in industry applications, and a variety of different attacks and defenses have been proposed so far, a complete systematization and critical review of the field is still missing. In this survey, we provide a comprehensive systematization of poisoning attacks and defenses in machine learning, reviewing more than 200 papers published in the field in the last 15 years. We start by categorizing the current threat models and attacks, and then organize existing defenses accordingly. While we focus mostly on computer-vision applications, we argue that our systematization also encompasses state-of-the-art attacks and defenses for other data modalities. Finally, we discuss existing resources for research in poisoning, and shed light on the current limitations and open research questions in this research field.
Machine Learning Security against Data Poisoning: Are We There Yet?
Apr 12, 2022

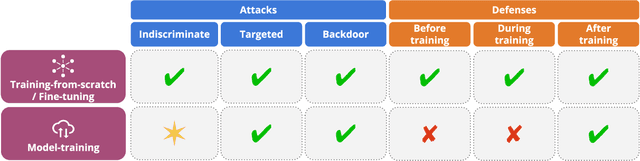
The recent success of machine learning has been fueled by the increasing availability of computing power and large amounts of data in many different applications. However, the trustworthiness of the resulting models can be compromised when such data is maliciously manipulated to mislead the learning process. In this article, we first review poisoning attacks that compromise the training data used to learn machine-learning models, including attacks that aim to reduce the overall performance, manipulate the predictions on specific test samples, and even implant backdoors in the model. We then discuss how to mitigate these attacks before, during, and after model training. We conclude our article by formulating some relevant open challenges which are hindering the development of testing methods and benchmarks suitable for assessing and improving the trustworthiness of machine-learning models against data poisoning attacks.
Energy-Latency Attacks via Sponge Poisoning
Apr 11, 2022
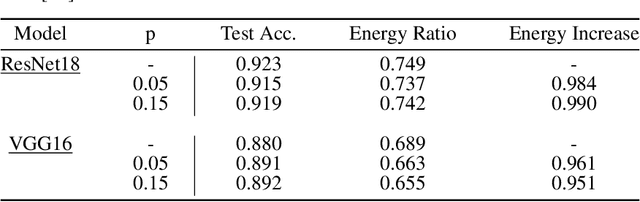
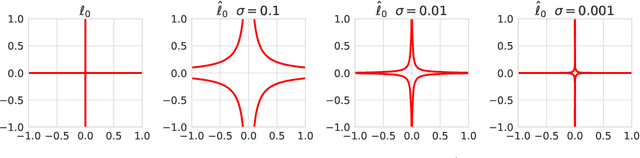
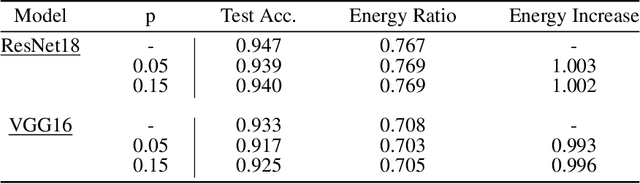
Sponge examples are test-time inputs carefully-optimized to increase energy consumption and latency of neural networks when deployed on hardware accelerators. In this work, we demonstrate that sponge attacks can also be implanted at training time, when model training is outsourced to a third party, via an attack that we call sponge poisoning. This attack allows one to increase the energy consumption and latency of machine-learning models indiscriminately on each test-time input. We present a novel formalization for sponge poisoning, overcoming the limitations related to the optimization of test-time sponge examples, and show that this attack is possible even if the attacker only controls a few poisoning samples and model updates. Our extensive experimental analysis, involving two deep learning architectures and three datasets, shows that sponge poisoning can almost completely vanish the effect of such hardware accelerators. Finally, we analyze activations of the resulting sponge models, identifying the module components that are more sensitive to this vulnerability.
Backdoor Learning Curves: Explaining Backdoor Poisoning Beyond Influence Functions
Jun 14, 2021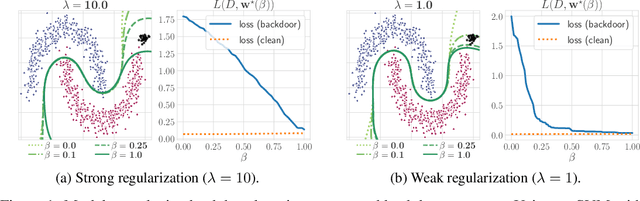
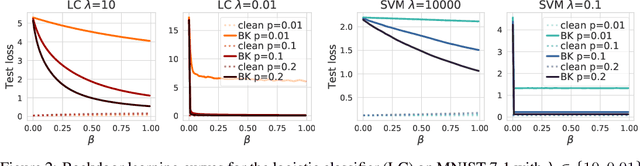
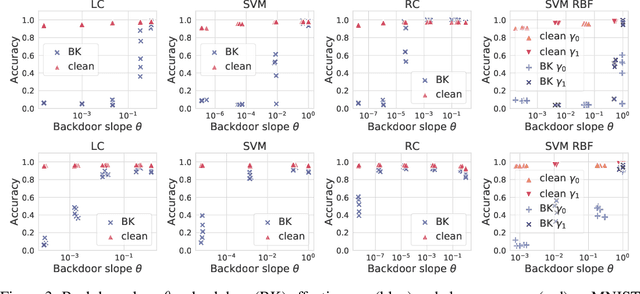
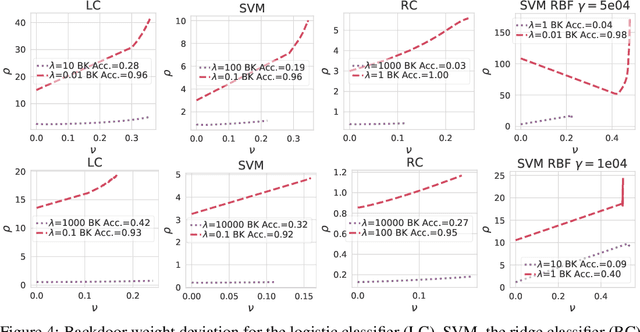
Backdoor attacks inject poisoning samples during training, with the goal of enforcing a machine-learning model to output an attacker-chosen class when presented a specific trigger at test time. Although backdoor attacks have been demonstrated in a variety of settings and against different models, the factors affecting their success are not yet well understood. In this work, we provide a unifying framework to study the process of backdoor learning under the lens of incremental learning and influence functions. We show that the success of backdoor attacks inherently depends on (i) the complexity of the learning algorithm, controlled by its hyperparameters, and (ii) the fraction of backdoor samples injected into the training set. These factors affect how fast a machine-learning model learns to correlate the presence of a backdoor trigger with the target class. Interestingly, our analysis shows that there exists a region in the hyperparameter space in which the accuracy on clean test samples is still high while backdoor attacks become ineffective, thereby suggesting novel criteria to improve existing defenses.
The Hammer and the Nut: Is Bilevel Optimization Really Needed to Poison Linear Classifiers?
Mar 23, 2021



One of the most concerning threats for modern AI systems is data poisoning, where the attacker injects maliciously crafted training data to corrupt the system's behavior at test time. Availability poisoning is a particularly worrisome subset of poisoning attacks where the attacker aims to cause a Denial-of-Service (DoS) attack. However, the state-of-the-art algorithms are computationally expensive because they try to solve a complex bi-level optimization problem (the "hammer"). We observed that in particular conditions, namely, where the target model is linear (the "nut"), the usage of computationally costly procedures can be avoided. We propose a counter-intuitive but efficient heuristic that allows contaminating the training set such that the target system's performance is highly compromised. We further suggest a re-parameterization trick to decrease the number of variables to be optimized. Finally, we demonstrate that, under the considered settings, our framework achieves comparable, or even better, performances in terms of the attacker's objective while being significantly more computationally efficient.