 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBattista Biggio
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
May 01, 2024
Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
Living-off-The-Land Reverse-Shell Detection by Informed Data Augmentation
Feb 28, 2024The living-off-the-land (LOTL) offensive methodologies rely on the perpetration of malicious actions through chains of commands executed by legitimate applications, identifiable exclusively by analysis of system logs. LOTL techniques are well hidden inside the stream of events generated by common legitimate activities, moreover threat actors often camouflage activity through obfuscation, making them particularly difficult to detect without incurring in plenty of false alarms, even using machine learning. To improve the performance of models in such an harsh environment, we propose an augmentation framework to enhance and diversify the presence of LOTL malicious activity inside legitimate logs. Guided by threat intelligence, we generate a dataset by injecting attack templates known to be employed in the wild, further enriched by malleable patterns of legitimate activities to replicate the behavior of evasive threat actors. We conduct an extensive ablation study to understand which models better handle our augmented dataset, also manipulated to mimic the presence of model-agnostic evasion and poisoning attacks. Our results suggest that augmentation is needed to maintain high-predictive capabilities, robustness to attack is achieved through specific hardening techniques like adversarial training, and it is possible to deploy near-real-time models with almost-zero false alarms.
Robustness-Congruent Adversarial Training for Secure Machine Learning Model Updates
Feb 27, 2024Machine-learning models demand for periodic updates to improve their average accuracy, exploiting novel architectures and additional data. However, a newly-updated model may commit mistakes that the previous model did not make. Such misclassifications are referred to as negative flips, and experienced by users as a regression of performance. In this work, we show that this problem also affects robustness to adversarial examples, thereby hindering the development of secure model update practices. In particular, when updating a model to improve its adversarial robustness, some previously-ineffective adversarial examples may become misclassified, causing a regression in the perceived security of the system. We propose a novel technique, named robustness-congruent adversarial training, to address this issue. It amounts to fine-tuning a model with adversarial training, while constraining it to retain higher robustness on the adversarial examples that were correctly classified before the update. We show that our algorithm and, more generally, learning with non-regression constraints, provides a theoretically-grounded framework to train consistent estimators. Our experiments on robust models for computer vision confirm that (i) both accuracy and robustness, even if improved after model update, can be affected by negative flips, and (ii) our robustness-congruent adversarial training can mitigate the problem, outperforming competing baseline methods.
$σ$-zero: Gradient-based Optimization of $\ell_0$-norm Adversarial Examples
Feb 02, 2024Evaluating the adversarial robustness of deep networks to gradient-based attacks is challenging. While most attacks consider $\ell_2$- and $\ell_\infty$-norm constraints to craft input perturbations, only a few investigate sparse $\ell_1$- and $\ell_0$-norm attacks. In particular, $\ell_0$-norm attacks remain the least studied due to the inherent complexity of optimizing over a non-convex and non-differentiable constraint. However, evaluating adversarial robustness under these attacks could reveal weaknesses otherwise left untested with more conventional $\ell_2$- and $\ell_\infty$-norm attacks. In this work, we propose a novel $\ell_0$-norm attack, called $\sigma$-zero, which leverages an ad hoc differentiable approximation of the $\ell_0$ norm to facilitate gradient-based optimization, and an adaptive projection operator to dynamically adjust the trade-off between loss minimization and perturbation sparsity. Extensive evaluations using MNIST, CIFAR10, and ImageNet datasets, involving robust and non-robust models, show that $\sigma$-zero finds minimum $\ell_0$-norm adversarial examples without requiring any time-consuming hyperparameter tuning, and that it outperforms all competing sparse attacks in terms of success rate, perturbation size, and scalability.
Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors
Oct 14, 2023Machine-learning phishing webpage detectors (ML-PWD) have been shown to suffer from adversarial manipulations of the HTML code of the input webpage. Nevertheless, the attacks recently proposed have demonstrated limited effectiveness due to their lack of optimizing the usage of the adopted manipulations, and they focus solely on specific elements of the HTML code. In this work, we overcome these limitations by first designing a novel set of fine-grained manipulations which allow to modify the HTML code of the input phishing webpage without compromising its maliciousness and visual appearance, i.e., the manipulations are functionality- and rendering-preserving by design. We then select which manipulations should be applied to bypass the target detector by a query-efficient black-box optimization algorithm. Our experiments show that our attacks are able to raze to the ground the performance of current state-of-the-art ML-PWD using just 30 queries, thus overcoming the weaker attacks developed in previous work, and enabling a much fairer robustness evaluation of ML-PWD.
Samples on Thin Ice: Re-Evaluating Adversarial Pruning of Neural Networks
Oct 12, 2023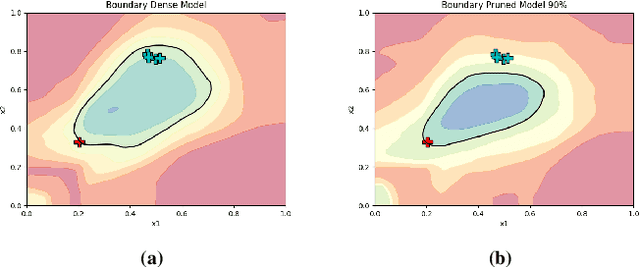
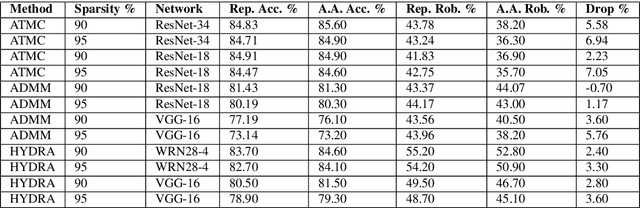
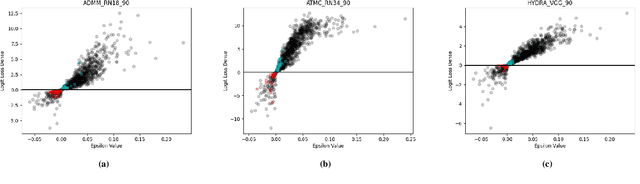

Neural network pruning has shown to be an effective technique for reducing the network size, trading desirable properties like generalization and robustness to adversarial attacks for higher sparsity. Recent work has claimed that adversarial pruning methods can produce sparse networks while also preserving robustness to adversarial examples. In this work, we first re-evaluate three state-of-the-art adversarial pruning methods, showing that their robustness was indeed overestimated. We then compare pruned and dense versions of the same models, discovering that samples on thin ice, i.e., closer to the unpruned model's decision boundary, are typically misclassified after pruning. We conclude by discussing how this intuition may lead to designing more effective adversarial pruning methods in future work.
Improving Fast Minimum-Norm Attacks with Hyperparameter Optimization
Oct 12, 2023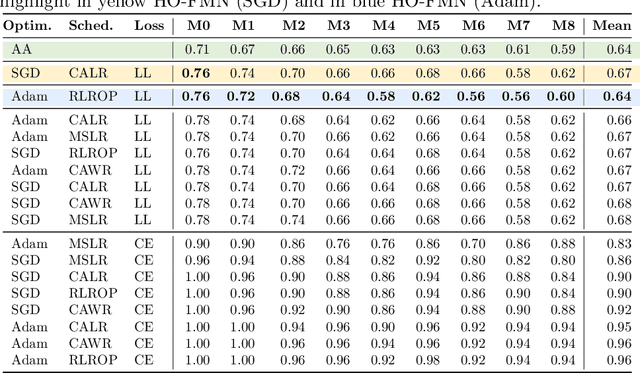

Evaluating the adversarial robustness of machine learning models using gradient-based attacks is challenging. In this work, we show that hyperparameter optimization can improve fast minimum-norm attacks by automating the selection of the loss function, the optimizer and the step-size scheduler, along with the corresponding hyperparameters. Our extensive evaluation involving several robust models demonstrates the improved efficacy of fast minimum-norm attacks when hyper-up with hyperparameter optimization. We release our open-source code at https://github.com/pralab/HO-FMN.
Adversarial Attacks Against Uncertainty Quantification
Sep 19, 2023Machine-learning models can be fooled by adversarial examples, i.e., carefully-crafted input perturbations that force models to output wrong predictions. While uncertainty quantification has been recently proposed to detect adversarial inputs, under the assumption that such attacks exhibit a higher prediction uncertainty than pristine data, it has been shown that adaptive attacks specifically aimed at reducing also the uncertainty estimate can easily bypass this defense mechanism. In this work, we focus on a different adversarial scenario in which the attacker is still interested in manipulating the uncertainty estimate, but regardless of the correctness of the prediction; in particular, the goal is to undermine the use of machine-learning models when their outputs are consumed by a downstream module or by a human operator. Following such direction, we: \textit{(i)} design a threat model for attacks targeting uncertainty quantification; \textit{(ii)} devise different attack strategies on conceptually different UQ techniques spanning for both classification and semantic segmentation problems; \textit{(iii)} conduct a first complete and extensive analysis to compare the differences between some of the most employed UQ approaches under attack. Our extensive experimental analysis shows that our attacks are more effective in manipulating uncertainty quantification measures than attacks aimed to also induce misclassifications.
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023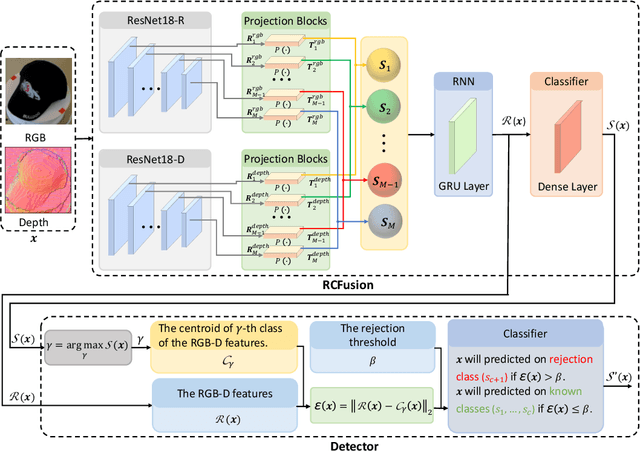
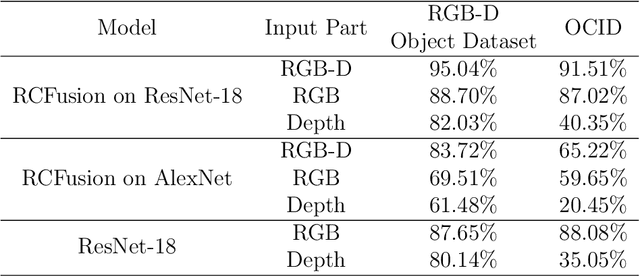
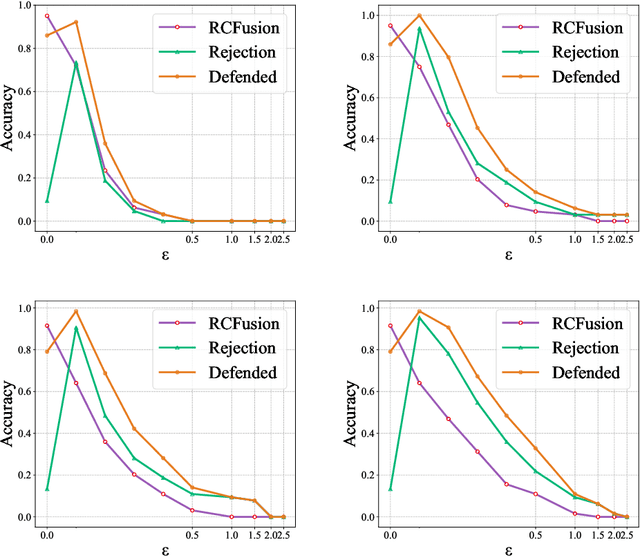
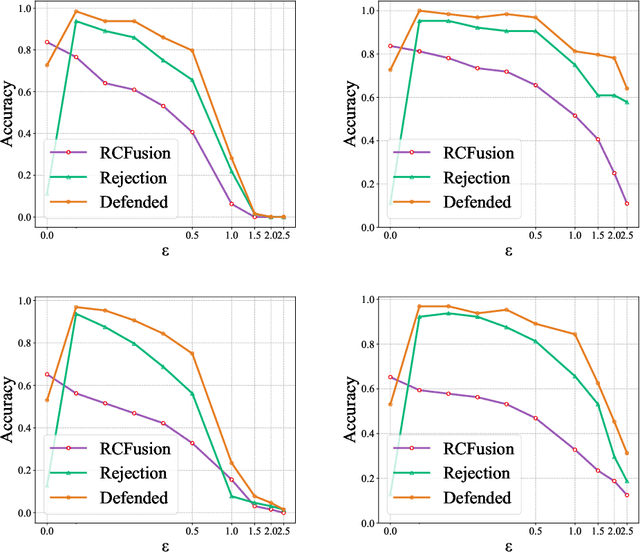
RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.