 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatrick Mannion
Demonstration Guided Multi-Objective Reinforcement Learning
Apr 05, 2024
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning
Feb 11, 2024A significant challenge in multi-objective reinforcement learning is obtaining a Pareto front of policies that attain optimal performance under different preferences. We introduce Iterated Pareto Referent Optimisation (IPRO), a principled algorithm that decomposes the task of finding the Pareto front into a sequence of single-objective problems for which various solution methods exist. This enables us to establish convergence guarantees while providing an upper bound on the distance to undiscovered Pareto optimal solutions at each step. Empirical evaluations demonstrate that IPRO matches or outperforms methods that require additional domain knowledge. By leveraging problem-specific single-objective solvers, our approach also holds promise for applications beyond multi-objective reinforcement learning, such as in pathfinding and optimisation.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
Go-Explore for Residential Energy Management
Jan 15, 2024Reinforcement learning is commonly applied in residential energy management, particularly for optimizing energy costs. However, RL agents often face challenges when dealing with deceptive and sparse rewards in the energy control domain, especially with stochastic rewards. In such situations, thorough exploration becomes crucial for learning an optimal policy. Unfortunately, the exploration mechanism can be misled by deceptive reward signals, making thorough exploration difficult. Go-Explore is a family of algorithms which combines planning methods and reinforcement learning methods to achieve efficient exploration. We use the Go-Explore algorithm to solve the cost-saving task in residential energy management problems and achieve an improvement of up to 19.84\% compared to the well-known reinforcement learning algorithms.
Inferring Preferences from Demonstrations in Multi-Objective Residential Energy Management
Jan 15, 2024It is often challenging for a user to articulate their preferences accurately in multi-objective decision-making problems. Demonstration-based preference inference (DemoPI) is a promising approach to mitigate this problem. Understanding the behaviours and values of energy customers is an example of a scenario where preference inference can be used to gain insights into the values of energy customers with multiple objectives, e.g. cost and comfort. In this work, we applied the state-of-art DemoPI method, i.e., the dynamic weight-based preference inference (DWPI) algorithm in a multi-objective residential energy consumption setting to infer preferences from energy consumption demonstrations by simulated users following a rule-based approach. According to our experimental results, the DWPI model achieves accurate demonstration-based preference inferring in three scenarios. These advancements enhance the usability and effectiveness of multi-objective reinforcement learning (MORL) in energy management, enabling more intuitive and user-friendly preference specifications, and opening the door for DWPI to be applied in real-world settings.
Evolutionary Strategy Guided Reinforcement Learning via MultiBuffer Communication
Jun 20, 2023Evolutionary Algorithms and Deep Reinforcement Learning have both successfully solved control problems across a variety of domains. Recently, algorithms have been proposed which combine these two methods, aiming to leverage the strengths and mitigate the weaknesses of both approaches. In this paper we introduce a new Evolutionary Reinforcement Learning model which combines a particular family of Evolutionary algorithm called Evolutionary Strategies with the off-policy Deep Reinforcement Learning algorithm TD3. The framework utilises a multi-buffer system instead of using a single shared replay buffer. The multi-buffer system allows for the Evolutionary Strategy to search freely in the search space of policies, without running the risk of overpopulating the replay buffer with poorly performing trajectories which limit the number of desirable policy behaviour examples thus negatively impacting the potential of the Deep Reinforcement Learning within the shared framework. The proposed algorithm is demonstrated to perform competitively with current Evolutionary Reinforcement Learning algorithms on MuJoCo control tasks, outperforming the well known state-of-the-art CEM-RL on 3 of the 4 environments tested.
Distributional Multi-Objective Decision Making
May 19, 2023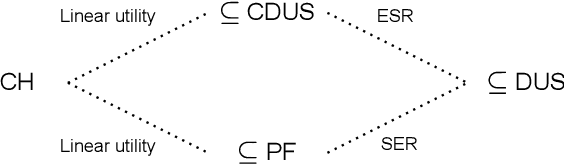

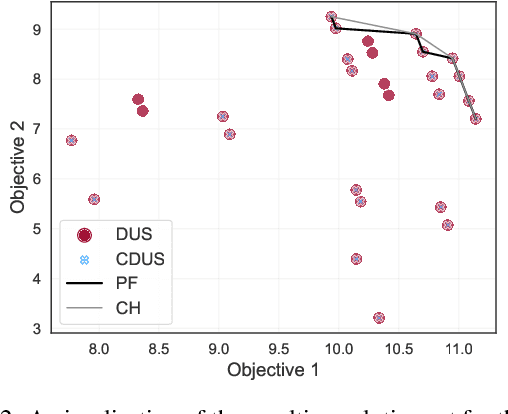
For effective decision support in scenarios with conflicting objectives, sets of potentially optimal solutions can be presented to the decision maker. We explore both what policies these sets should contain and how such sets can be computed efficiently. With this in mind, we take a distributional approach and introduce a novel dominance criterion relating return distributions of policies directly. Based on this criterion, we present the distributional undominated set and show that it contains optimal policies otherwise ignored by the Pareto front. In addition, we propose the convex distributional undominated set and prove that it comprises all policies that maximise expected utility for multivariate risk-averse decision makers. We propose a novel algorithm to learn the distributional undominated set and further contribute pruning operators to reduce the set to the convex distributional undominated set. Through experiments, we demonstrate the feasibility and effectiveness of these methods, making this a valuable new approach for decision support in real-world problems.
Inferring Preferences from Demonstrations in Multi-objective Reinforcement Learning: A Dynamic Weight-based Approach
Apr 27, 2023



Many decision-making problems feature multiple objectives. In such problems, it is not always possible to know the preferences of a decision-maker for different objectives. However, it is often possible to observe the behavior of decision-makers. In multi-objective decision-making, preference inference is the process of inferring the preferences of a decision-maker for different objectives. This research proposes a Dynamic Weight-based Preference Inference (DWPI) algorithm that can infer the preferences of agents acting in multi-objective decision-making problems, based on observed behavior trajectories in the environment. The proposed method is evaluated on three multi-objective Markov decision processes: Deep Sea Treasure, Traffic, and Item Gathering. The performance of the proposed DWPI approach is compared to two existing preference inference methods from the literature, and empirical results demonstrate significant improvements compared to the baseline algorithms, in terms of both time requirements and accuracy of the inferred preferences. The Dynamic Weight-based Preference Inference algorithm also maintains its performance when inferring preferences for sub-optimal behavior demonstrations. In addition to its impressive performance, the Dynamic Weight-based Preference Inference algorithm does not require any interactions during training with the agent whose preferences are inferred, all that is required is a trajectory of observed behavior.
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Dec 06, 2022
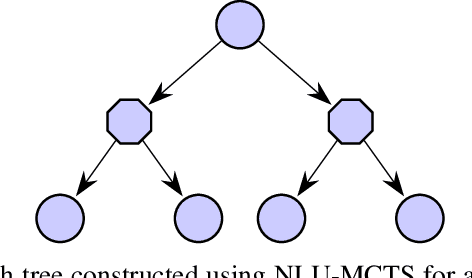
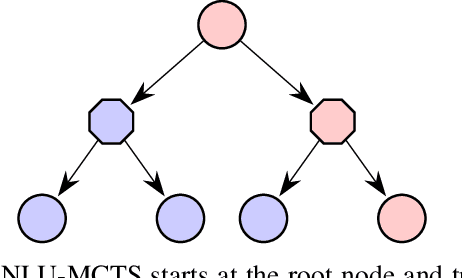
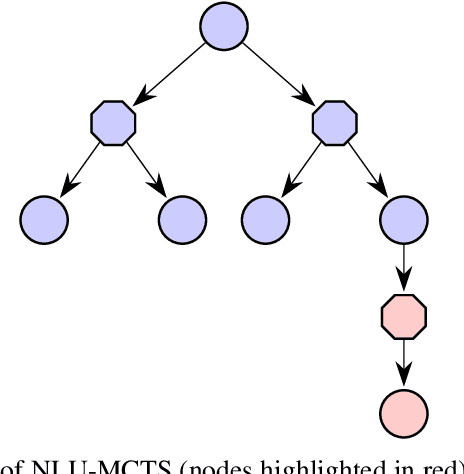
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Multi-Objective Coordination Graphs for the Expected Scalarised Returns with Generative Flow Models
Jul 01, 2022



Many real-world problems contain multiple objectives and agents, where a trade-off exists between objectives. Key to solving such problems is to exploit sparse dependency structures that exist between agents. For example, in wind farm control a trade-off exists between maximising power and minimising stress on the systems components. Dependencies between turbines arise due to the wake effect. We model such sparse dependencies between agents as a multi-objective coordination graph (MO-CoG). In multi-objective reinforcement learning a utility function is typically used to model a users preferences over objectives, which may be unknown a priori. In such settings a set of optimal policies must be computed. Which policies are optimal depends on which optimality criterion applies. If the utility function of a user is derived from multiple executions of a policy, the scalarised expected returns (SER) must be optimised. If the utility of a user is derived from a single execution of a policy, the expected scalarised returns (ESR) criterion must be optimised. For example, wind farms are subjected to constraints and regulations that must be adhered to at all times, therefore the ESR criterion must be optimised. For MO-CoGs, the state-of-the-art algorithms can only compute a set of optimal policies for the SER criterion, leaving the ESR criterion understudied. To compute a set of optimal polices under the ESR criterion, also known as the ESR set, distributions over the returns must be maintained. Therefore, to compute a set of optimal policies under the ESR criterion for MO-CoGs, we present a novel distributional multi-objective variable elimination (DMOVE) algorithm. We evaluate DMOVE in realistic wind farm simulations. Given the returns in real-world wind farm settings are continuous, we utilise a model known as real-NVP to learn the continuous return distributions to calculate the ESR set.