 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWillem Röpke
Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning
Feb 11, 2024
A significant challenge in multi-objective reinforcement learning is obtaining a Pareto front of policies that attain optimal performance under different preferences. We introduce Iterated Pareto Referent Optimisation (IPRO), a principled algorithm that decomposes the task of finding the Pareto front into a sequence of single-objective problems for which various solution methods exist. This enables us to establish convergence guarantees while providing an upper bound on the distance to undiscovered Pareto optimal solutions at each step. Empirical evaluations demonstrate that IPRO matches or outperforms methods that require additional domain knowledge. By leveraging problem-specific single-objective solvers, our approach also holds promise for applications beyond multi-objective reinforcement learning, such as in pathfinding and optimisation.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
Distributional Multi-Objective Decision Making
May 19, 2023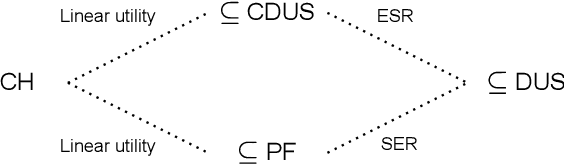

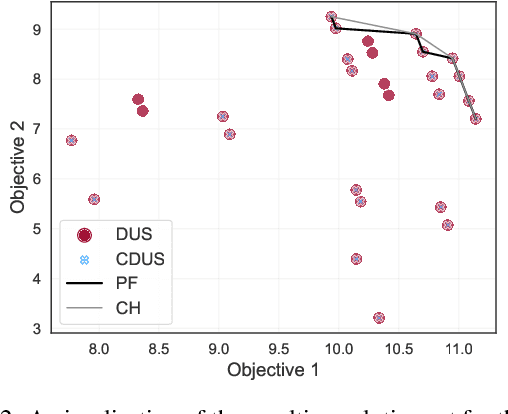
For effective decision support in scenarios with conflicting objectives, sets of potentially optimal solutions can be presented to the decision maker. We explore both what policies these sets should contain and how such sets can be computed efficiently. With this in mind, we take a distributional approach and introduce a novel dominance criterion relating return distributions of policies directly. Based on this criterion, we present the distributional undominated set and show that it contains optimal policies otherwise ignored by the Pareto front. In addition, we propose the convex distributional undominated set and prove that it comprises all policies that maximise expected utility for multivariate risk-averse decision makers. We propose a novel algorithm to learn the distributional undominated set and further contribute pruning operators to reduce the set to the convex distributional undominated set. Through experiments, we demonstrate the feasibility and effectiveness of these methods, making this a valuable new approach for decision support in real-world problems.
Preference Communication in Multi-Objective Normal-Form Games
Nov 17, 2021



We study the problem of multiple agents learning concurrently in a multi-objective environment. Specifically, we consider two agents that repeatedly play a multi-objective normal-form game. In such games, the payoffs resulting from joint actions are vector valued. Taking a utility-based approach, we assume a utility function exists that maps vectors to scalar utilities and consider agents that aim to maximise the utility of expected payoff vectors. As agents do not necessarily know their opponent's utility function or strategy, they must learn optimal policies to interact with each other. To aid agents in arriving at adequate solutions, we introduce four novel preference communication protocols for both cooperative as well as self-interested communication. Each approach describes a specific protocol for one agent communicating preferences over their actions and how another agent responds. These protocols are subsequently evaluated on a set of five benchmark games against baseline agents that do not communicate. We find that preference communication can drastically alter the learning process and lead to the emergence of cyclic Nash equilibria which had not been previously observed in this setting. Additionally, we introduce a communication scheme where agents must learn when to communicate. For agents in games with Nash equilibria, we find that communication can be beneficial but difficult to learn when agents have different preferred equilibria. When this is not the case, agents become indifferent to communication. In games without Nash equilibria, our results show differences across learning rates. When using faster learners, we observe that explicit communication becomes more prevalent at around 50% of the time, as it helps them in learning a compromise joint policy. Slower learners retain this pattern to a lesser degree, but show increased indifference.