 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaul Resnick
Spot Check Equivalence: an Interpretable Metric for Information Elicitation Mechanisms
Feb 21, 2024
Because high-quality data is like oxygen for AI systems, effectively eliciting information from crowdsourcing workers has become a first-order problem for developing high-performance machine learning algorithms. Two prevalent paradigms, spot-checking and peer prediction, enable the design of mechanisms to evaluate and incentivize high-quality data from human labelers. So far, at least three metrics have been proposed to compare the performances of these techniques [33, 8, 3]. However, different metrics lead to divergent and even contradictory results in various contexts. In this paper, we harmonize these divergent stories, showing that two of these metrics are actually the same within certain contexts and explain the divergence of the third. Moreover, we unify these different contexts by introducing \textit{Spot Check Equivalence}, which offers an interpretable metric for the effectiveness of a peer prediction mechanism. Finally, we present two approaches to compute spot check equivalence in various contexts, where simulation results verify the effectiveness of our proposed metric.
Survey Equivalence: A Procedure for Measuring Classifier Accuracy Against Human Labels
Jun 02, 2021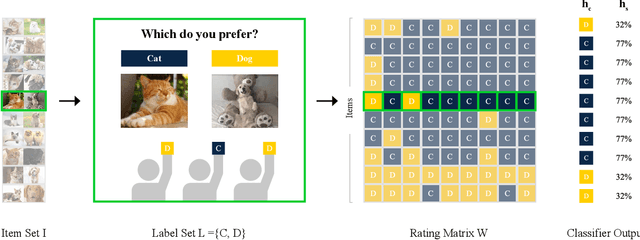

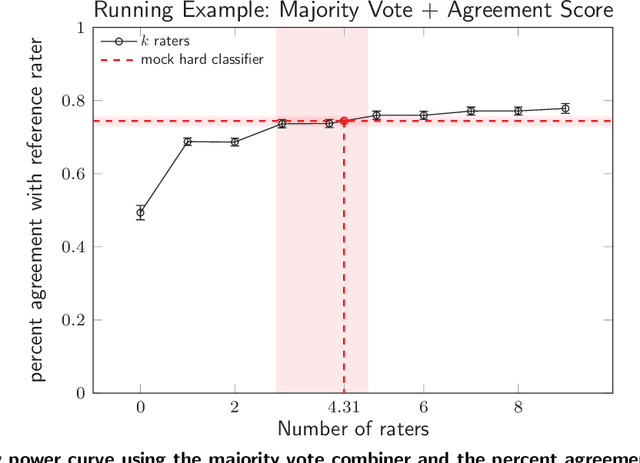
In many classification tasks, the ground truth is either noisy or subjective. Examples include: which of two alternative paper titles is better? is this comment toxic? what is the political leaning of this news article? We refer to such tasks as survey settings because the ground truth is defined through a survey of one or more human raters. In survey settings, conventional measurements of classifier accuracy such as precision, recall, and cross-entropy confound the quality of the classifier with the level of agreement among human raters. Thus, they have no meaningful interpretation on their own. We describe a procedure that, given a dataset with predictions from a classifier and K ratings per item, rescales any accuracy measure into one that has an intuitive interpretation. The key insight is to score the classifier not against the best proxy for the ground truth, such as a majority vote of the raters, but against a single human rater at a time. That score can be compared to other predictors' scores, in particular predictors created by combining labels from several other human raters. The survey equivalence of any classifier is the minimum number of raters needed to produce the same expected score as that found for the classifier.
Extractive Adversarial Networks: High-Recall Explanations for Identifying Personal Attacks in Social Media Posts
Oct 19, 2018



We introduce an adversarial method for producing high-recall explanations of neural text classifier decisions. Building on an existing architecture for extractive explanations via hard attention, we add an adversarial layer which scans the residual of the attention for remaining predictive signal. Motivated by the important domain of detecting personal attacks in social media comments, we additionally demonstrate the importance of manually setting a semantically appropriate `default' behavior for the model by explicitly manipulating its bias term. We develop a validation set of human-annotated personal attacks to evaluate the impact of these changes.