 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePengcheng Jiang
TriSum: Learning Summarization Ability from Large Language Models with Structured Rationale
Mar 15, 2024
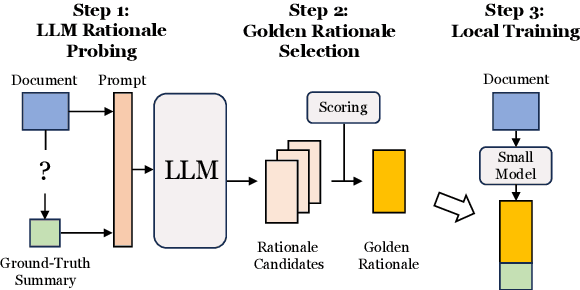
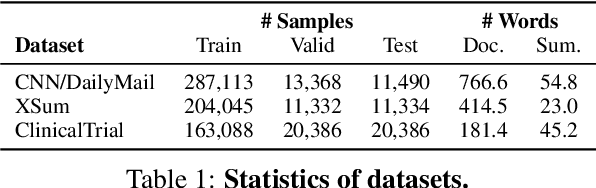
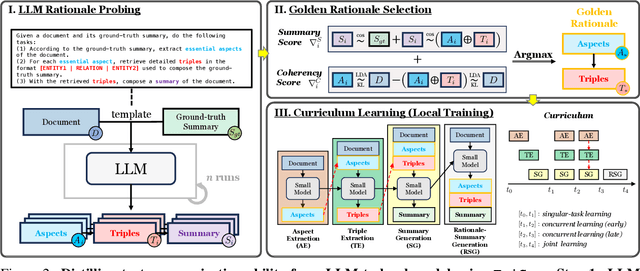
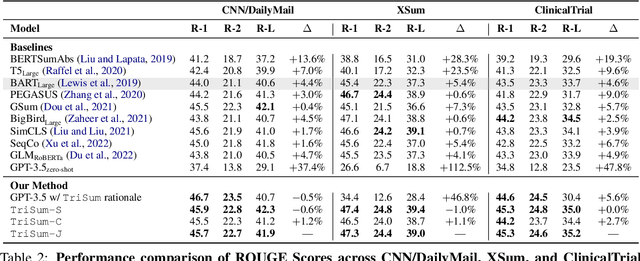
The advent of large language models (LLMs) has significantly advanced natural language processing tasks like text summarization. However, their large size and computational demands, coupled with privacy concerns in data transmission, limit their use in resource-constrained and privacy-centric settings. To overcome this, we introduce TriSum, a framework for distilling LLMs' text summarization abilities into a compact, local model. Initially, LLMs extract a set of aspect-triple rationales and summaries, which are refined using a dual-scoring method for quality. Next, a smaller local model is trained with these tasks, employing a curriculum learning strategy that evolves from simple to complex tasks. Our method enhances local model performance on various benchmarks (CNN/DailyMail, XSum, and ClinicalTrial), outperforming baselines by 4.5%, 8.5%, and 7.4%, respectively. It also improves interpretability by providing insights into the summarization rationale.
GenRES: Rethinking Evaluation for Generative Relation Extraction in the Era of Large Language Models
Feb 16, 2024The field of relation extraction (RE) is experiencing a notable shift towards generative relation extraction (GRE), leveraging the capabilities of large language models (LLMs). However, we discovered that traditional relation extraction (RE) metrics like precision and recall fall short in evaluating GRE methods. This shortfall arises because these metrics rely on exact matching with human-annotated reference relations, while GRE methods often produce diverse and semantically accurate relations that differ from the references. To fill this gap, we introduce GenRES for a multi-dimensional assessment in terms of the topic similarity, uniqueness, granularity, factualness, and completeness of the GRE results. With GenRES, we empirically identified that (1) precision/recall fails to justify the performance of GRE methods; (2) human-annotated referential relations can be incomplete; (3) prompting LLMs with a fixed set of relations or entities can cause hallucinations. Next, we conducted a human evaluation of GRE methods that shows GenRES is consistent with human preferences for RE quality. Last, we made a comprehensive evaluation of fourteen leading LLMs using GenRES across document, bag, and sentence level RE datasets, respectively, to set the benchmark for future research in GRE
Gode -- Integrating Biochemical Knowledge Graph into Pre-training Molecule Graph Neural Network
Jun 02, 2023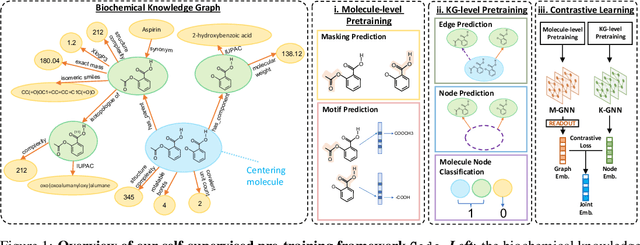

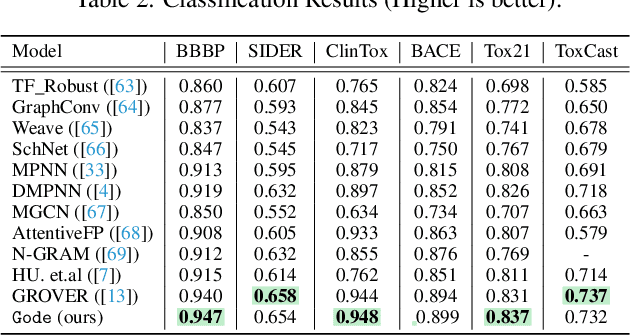
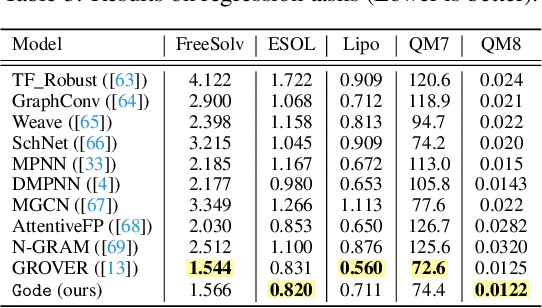
The precise prediction of molecular properties holds paramount importance in facilitating the development of innovative treatments and comprehending the intricate interplay between chemicals and biological systems. In this study, we propose a novel approach that integrates graph representations of individual molecular structures with multi-domain information from biomedical knowledge graphs (KGs). Integrating information from both levels, we can pre-train a more extensive and robust representation for both molecule-level and KG-level prediction tasks with our novel self-supervision strategy. For performance evaluation, we fine-tune our pre-trained model on 11 challenging chemical property prediction tasks. Results from our framework demonstrate our fine-tuned models outperform existing state-of-the-art models.
Text-Augmented Open Knowledge Graph Completion via Pre-Trained Language Models
May 24, 2023



The mission of open knowledge graph (KG) completion is to draw new findings from known facts. Existing works that augment KG completion require either (1) factual triples to enlarge the graph reasoning space or (2) manually designed prompts to extract knowledge from a pre-trained language model (PLM), exhibiting limited performance and requiring expensive efforts from experts. To this end, we propose TAGREAL that automatically generates quality query prompts and retrieves support information from large text corpora to probe knowledge from PLM for KG completion. The results show that TAGREAL achieves state-of-the-art performance on two benchmark datasets. We find that TAGREAL has superb performance even with limited training data, outperforming existing embedding-based, graph-based, and PLM-based methods.
GraphCare: Enhancing Healthcare Predictions with Open-World Personalized Knowledge Graphs
May 22, 2023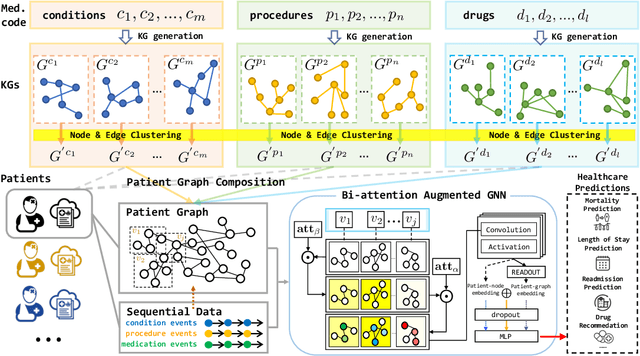
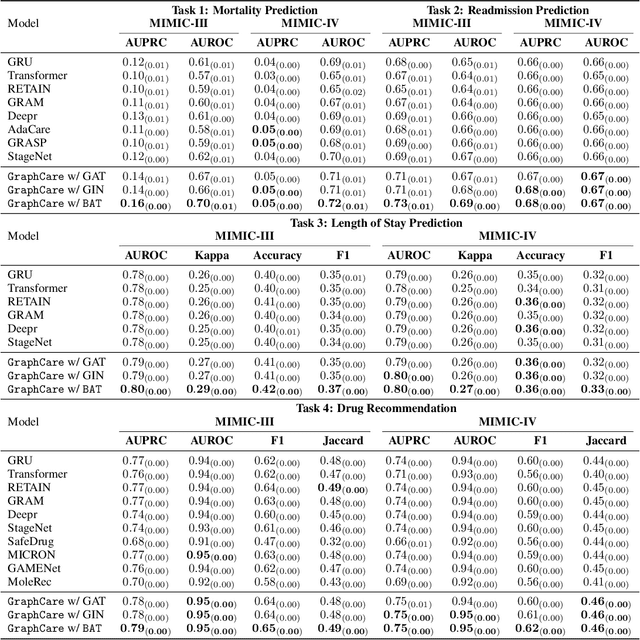
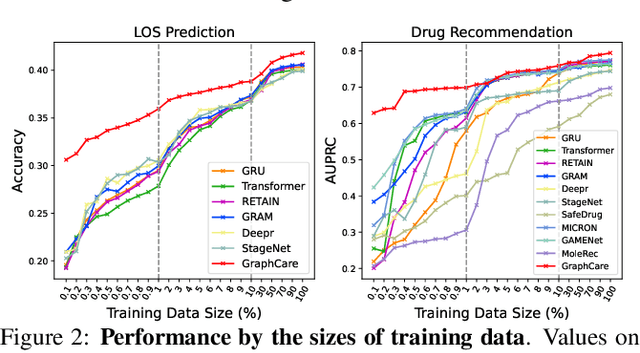

Clinical predictive models often rely on patients electronic health records (EHR), but integrating medical knowledge to enhance predictions and decision-making is challenging. This is because personalized predictions require personalized knowledge graphs (KGs), which are difficult to generate from patient EHR data. To address this, we propose GraphCare, an open-world framework that leverages external KGs to improve EHR-based predictions. Our method extracts knowledge from large language models (LLMs) and external biomedical KGs to generate patient-specific KGs, which are then used to train our proposed Bi-attention AugmenTed BAT graph neural network GNN for healthcare predictions. We evaluate GraphCare on two public datasets: MIMIC-III and MIMIC-IV. Our method outperforms baseline models in four vital healthcare prediction tasks: mortality, readmission, length-of-stay, and drug recommendation, improving AUROC on MIMIC-III by average margins of 10.4%, 3.8%, 2.0%, and 1.5%, respectively. Notably, GraphCare demonstrates a substantial edge in scenarios with limited data availability. Our findings highlight the potential of using external KGs in healthcare prediction tasks and demonstrate the promise of GraphCare in generating personalized KGs for promoting personalized medicine.
OACAL: Finding Module-consistent Specifications to Secure Systems from Weakened User Obligations
Aug 19, 2021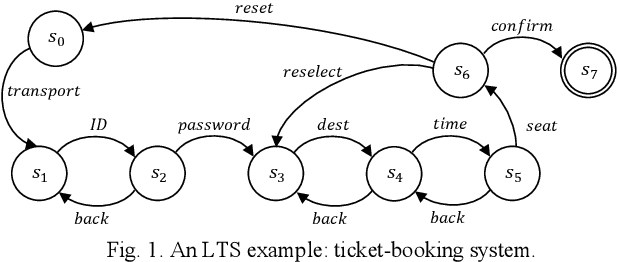
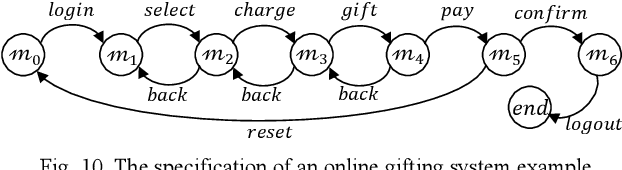
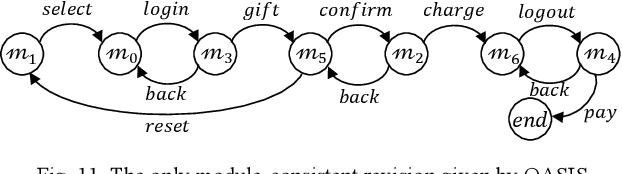

Users interacting with a system through UI are typically obliged to perform their actions in a pre-determined order, to successfully achieve certain functional goals. However, such obligations are often not followed strictly by users, which may lead to the violation to security properties, especially in security-critical systems. To improve the security with the awareness of unexpected user behaviors, a system can be redesigned to a more robust one by changing the order of actions in its specification. Meanwhile, we anticipate that the functionalities would remain consistent following the modifications. In this paper, we propose an efficient algorithm to automatically produce specification revisions tackling the attack scenarios caused by weakened user obligations. By our algorithm, all the revisions would be generated to maintain the integrity of the functionalities using a novel recomposition approach. Then, the eligible revisions that can satisfy the security requirements would be efficiently spotted by a hybrid approach combining model checking and machine learning techniques. We evaluate our algorithm by comparing its performance with a state-of-the-art approach regarding their coverage and searching speed of the desirable revisions.