 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePieter Delobelle
Tik-to-Tok: Translating Language Models One Token at a Time: An Embedding Initialization Strategy for Efficient Language Adaptation
Oct 05, 2023
Training monolingual language models for low and mid-resource languages is made challenging by limited and often inadequate pretraining data. In this study, we propose a novel model conversion strategy to address this issue, adapting high-resources monolingual language models to a new target language. By generalizing over a word translation dictionary encompassing both the source and target languages, we map tokens from the target tokenizer to semantically similar tokens from the source language tokenizer. This one-to-many token mapping improves tremendously the initialization of the embedding table for the target language. We conduct experiments to convert high-resource models to mid- and low-resource languages, namely Dutch and Frisian. These converted models achieve a new state-of-the-art performance on these languages across all sorts of downstream tasks. By reducing significantly the amount of data and time required for training state-of-the-art models, our novel model conversion strategy has the potential to benefit many languages worldwide.
How Far Can It Go?: On Intrinsic Gender Bias Mitigation for Text Classification
Jan 30, 2023

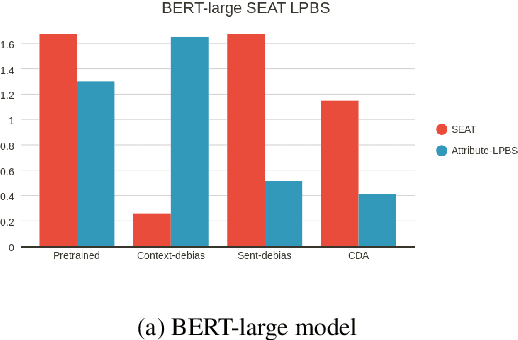
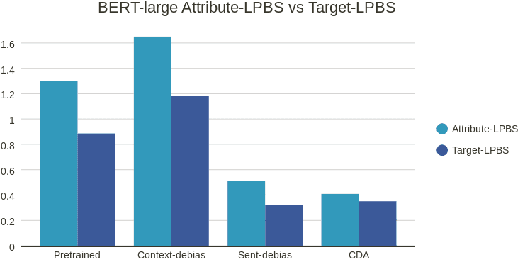
To mitigate gender bias in contextualized language models, different intrinsic mitigation strategies have been proposed, alongside many bias metrics. Considering that the end use of these language models is for downstream tasks like text classification, it is important to understand how these intrinsic bias mitigation strategies actually translate to fairness in downstream tasks and the extent of this. In this work, we design a probe to investigate the effects that some of the major intrinsic gender bias mitigation strategies have on downstream text classification tasks. We discover that instead of resolving gender bias, intrinsic mitigation techniques and metrics are able to hide it in such a way that significant gender information is retained in the embeddings. Furthermore, we show that each mitigation technique is able to hide the bias from some of the intrinsic bias measures but not all, and each intrinsic bias measure can be fooled by some mitigation techniques, but not all. We confirm experimentally, that none of the intrinsic mitigation techniques used without any other fairness intervention is able to consistently impact extrinsic bias. We recommend that intrinsic bias mitigation techniques should be combined with other fairness interventions for downstream tasks.
RobBERT-2022: Updating a Dutch Language Model to Account for Evolving Language Use
Nov 15, 2022


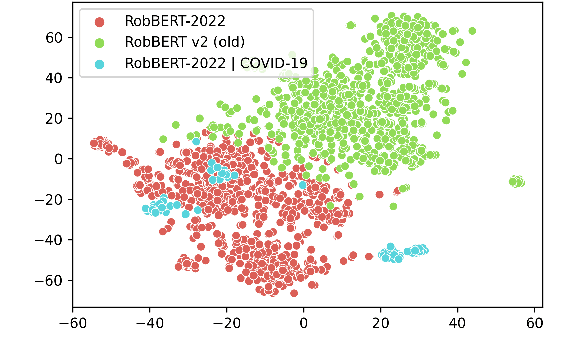
Large transformer-based language models, e.g. BERT and GPT-3, outperform previous architectures on most natural language processing tasks. Such language models are first pre-trained on gigantic corpora of text and later used as base-model for finetuning on a particular task. Since the pre-training step is usually not repeated, base models are not up-to-date with the latest information. In this paper, we update RobBERT, a RoBERTa-based state-of-the-art Dutch language model, which was trained in 2019. First, the tokenizer of RobBERT is updated to include new high-frequent tokens present in the latest Dutch OSCAR corpus, e.g. corona-related words. Then we further pre-train the RobBERT model using this dataset. To evaluate if our new model is a plug-in replacement for RobBERT, we introduce two additional criteria based on concept drift of existing tokens and alignment for novel tokens.We found that for certain language tasks this update results in a significant performance increase. These results highlight the benefit of continually updating a language model to account for evolving language use.
FairDistillation: Mitigating Stereotyping in Language Models
Jul 10, 2022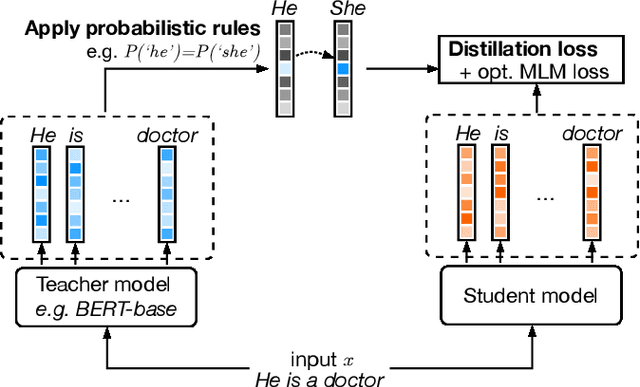

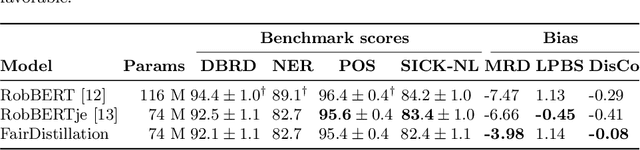
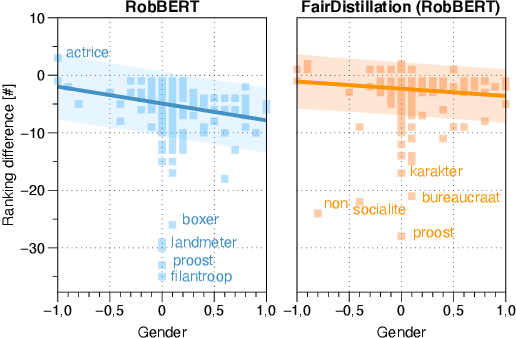
Large pre-trained language models are successfully being used in a variety of tasks, across many languages. With this ever-increasing usage, the risk of harmful side effects also rises, for example by reproducing and reinforcing stereotypes. However, detecting and mitigating these harms is difficult to do in general and becomes computationally expensive when tackling multiple languages or when considering different biases. To address this, we present FairDistillation: a cross-lingual method based on knowledge distillation to construct smaller language models while controlling for specific biases. We found that our distillation method does not negatively affect the downstream performance on most tasks and successfully mitigates stereotyping and representational harms. We demonstrate that FairDistillation can create fairer language models at a considerably lower cost than alternative approaches.
RobBERTje: a Distilled Dutch BERT Model
Apr 28, 2022
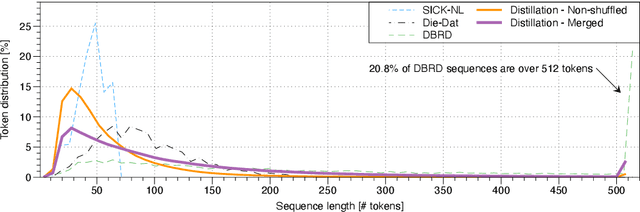


Pre-trained large-scale language models such as BERT have gained a lot of attention thanks to their outstanding performance on a wide range of natural language tasks. However, due to their large number of parameters, they are resource-intensive both to deploy and to fine-tune. Researchers have created several methods for distilling language models into smaller ones to increase efficiency, with a small performance trade-off. In this paper, we create several different distilled versions of the state-of-the-art Dutch RobBERT model and call them RobBERTje. The distillations differ in their distillation corpus, namely whether or not they are shuffled and whether they are merged with subsequent sentences. We found that the performance of the models using the shuffled versus non-shuffled datasets is similar for most tasks and that randomly merging subsequent sentences in a corpus creates models that train faster and perform better on tasks with long sequences. Upon comparing distillation architectures, we found that the larger DistilBERT architecture worked significantly better than the Bort hyperparametrization. Interestingly, we also found that the distilled models exhibit less gender-stereotypical bias than its teacher model. Since smaller architectures decrease the time to fine-tune, these models allow for more efficient training and more lightweight deployment of many Dutch downstream language tasks.
* Published in CLIN journal
Measuring Fairness with Biased Rulers: A Survey on Quantifying Biases in Pretrained Language Models
Dec 14, 2021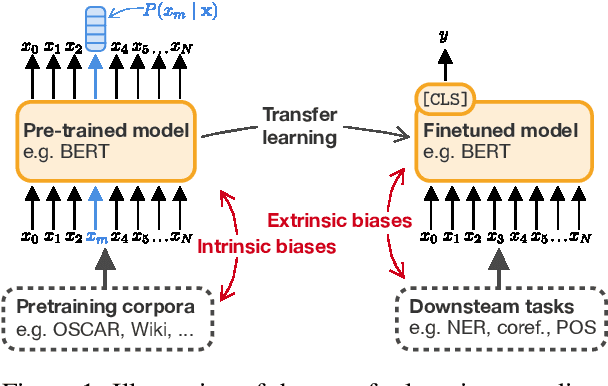

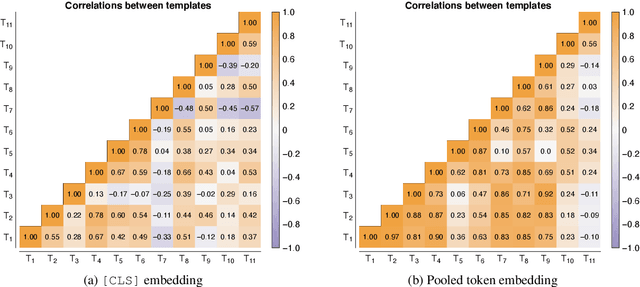

An increasing awareness of biased patterns in natural language processing resources, like BERT, has motivated many metrics to quantify `bias' and `fairness'. But comparing the results of different metrics and the works that evaluate with such metrics remains difficult, if not outright impossible. We survey the existing literature on fairness metrics for pretrained language models and experimentally evaluate compatibility, including both biases in language models as in their downstream tasks. We do this by a mixture of traditional literature survey and correlation analysis, as well as by running empirical evaluations. We find that many metrics are not compatible and highly depend on (i) templates, (ii) attribute and target seeds and (iii) the choice of embeddings. These results indicate that fairness or bias evaluation remains challenging for contextualized language models, if not at least highly subjective. To improve future comparisons and fairness evaluations, we recommend avoiding embedding-based metrics and focusing on fairness evaluations in downstream tasks.
Measuring Shifts in Attitudes Towards COVID-19 Measures in Belgium Using Multilingual BERT
Apr 20, 2021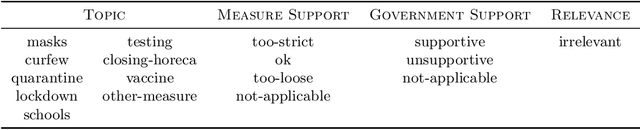
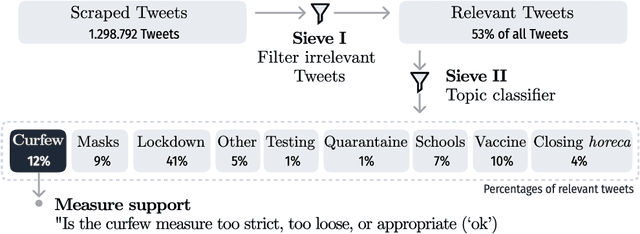
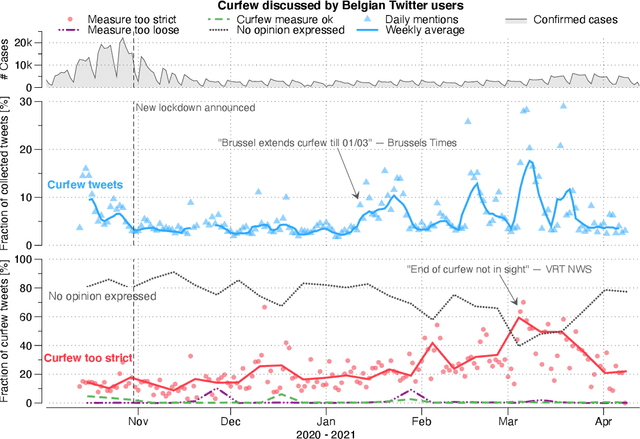
We classify seven months' worth of Belgian COVID-related Tweets using multilingual BERT and relate them to their governments' COVID measures. We classify Tweets by their stated opinion on Belgian government curfew measures (too strict, ok, too loose). We examine the change in topics discussed and views expressed over time and in reference to dates of related events such as implementation of new measures or COVID-19 related announcements in the media.
Dutch Humor Detection by Generating Negative Examples
Oct 26, 2020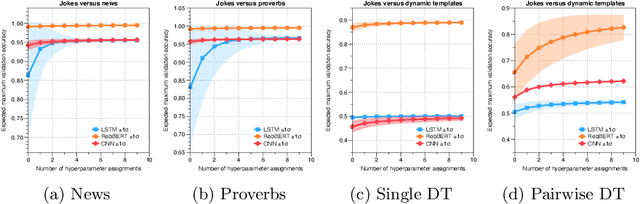
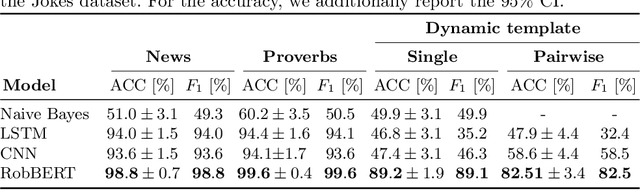
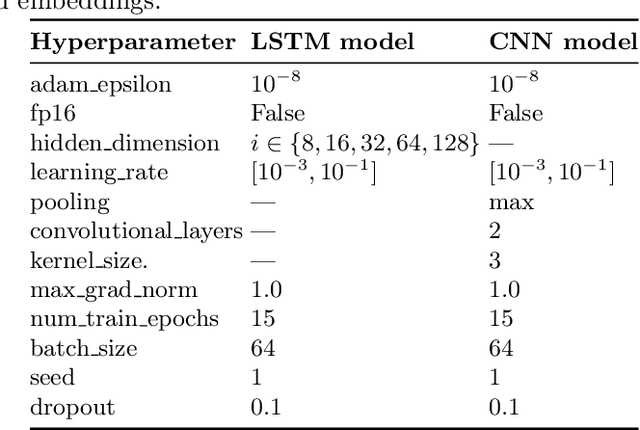

Detecting if a text is humorous is a hard task to do computationally, as it usually requires linguistic and common sense insights. In machine learning, humor detection is usually modeled as a binary classification task, trained to predict if the given text is a joke or another type of text. Rather than using completely different non-humorous texts, we propose using text generation algorithms for imitating the original joke dataset to increase the difficulty for the learning algorithm. We constructed several different joke and non-joke datasets to test the humor detection abilities of different language technologies. In particular, we compare the humor detection capabilities of classic neural network approaches with the state-of-the-art Dutch language model RobBERT. In doing so, we create and compare the first Dutch humor detection systems. We found that while other language models perform well when the non-jokes came from completely different domains, RobBERT was the only one that was able to distinguish jokes from generated negative examples. This performance illustrates the usefulness of using text generation to create negative datasets for humor recognition, and also shows that transformer models are a large step forward in humor detection.
Ethical Adversaries: Towards Mitigating Unfairness with Adversarial Machine Learning
May 14, 2020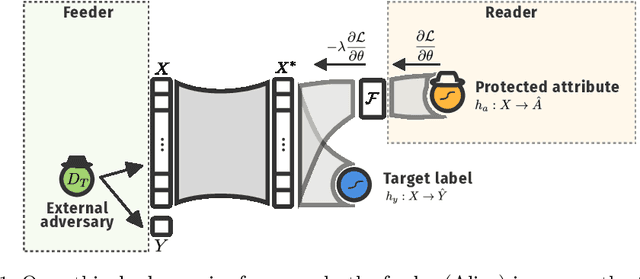
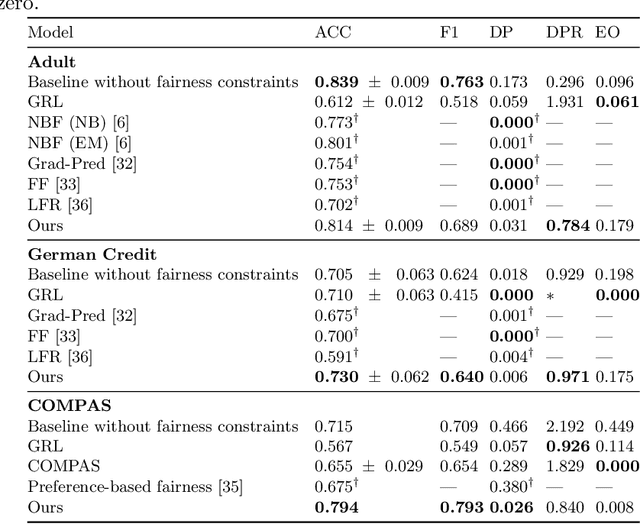
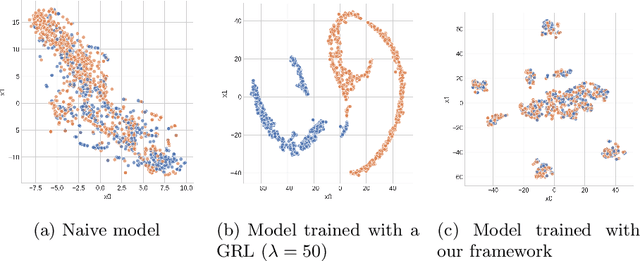
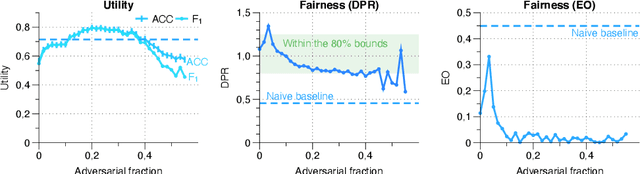
Machine learning is being integrated into a growing number of critical systems with far-reaching impacts on society. Unexpected behaviour and unfair decision processes are coming under increasing scrutiny due to this widespread use and also due to theoretical considerations. Individuals, as well as organisations, notice, test, and criticize unfair results to hold model designers and deployers accountable. This requires transparency and the possibility to describe, measure and, ideally, prove the 'fairness' of a system. This involves concepts such as fairness, transparency and accountability that will hopefully make machine learning more amenable to criticism and improvement proposals towards the fulfilment of societal goals. We concentrate on fairness, taking into account that both the transparency of the neural networks and accountability of actors and systems will require further methods. We offer a new framework that assists in mitigating unfair representations in the dataset used for training. Our framework relies on adversaries to improve fairness. First, it evaluates a model for unfairness w.r.t. protected attributes and ensures that an adversary cannot guess such attributes for a given outcome, by optimizing the model's parameters for fairness while limiting utility losses. Second, the framework leverages evasion attacks from adversarial machine learning to perform adversarial retraining with new examples unseen by the model. These two steps are iteratively applied until a significant improvement in fairness is obtained. We evaluated our framework on well-studied datasets in the fairness literature-including COMPAS-where it can surpass other approaches concerning demographic parity, equality of opportunity and also the model's utility. We also illustrate our findings on the subtle difficulties when mitigating unfairness and highlight how our framework can help model designers.
RobBERT: a Dutch RoBERTa-based Language Model
Jan 17, 2020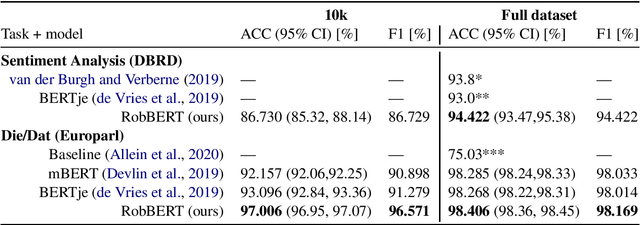

Pre-trained language models have been dominating the field of natural language processing in recent years, and have led to significant performance gains for various complex natural language tasks. One of the most prominent pre-trained language models is BERT (Bi-directional Encoders for Transformers), which was released as an English as well as a multilingual version. Although multilingual BERT performs well on many tasks, recent studies showed that BERT models trained on a single language significantly outperform the multilingual results. Training a Dutch BERT model thus has a lot of potential for a wide range of Dutch NLP tasks. While previous approaches have used earlier implementations of BERT to train their Dutch BERT, we used RoBERTa, a robustly optimized BERT approach, to train a Dutch language model called RobBERT. We show that RobBERT improves state of the art results in Dutch-specific language tasks, and also outperforms other existing Dutch BERT-based models in sentiment analysis. These results indicate that RobBERT is a powerful pre-trained model for fine-tuning for a large variety of Dutch language tasks. We publicly release this pre-trained model in hope of supporting further downstream Dutch NLP applications.