 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToon Calders
How to be fair? A study of label and selection bias
Mar 21, 2024
It is widely accepted that biased data leads to biased and thus potentially unfair models. Therefore, several measures for bias in data and model predictions have been proposed, as well as bias mitigation techniques whose aim is to learn models that are fair by design. Despite the myriad of mitigation techniques developed in the past decade, however, it is still poorly understood under what circumstances which methods work. Recently, Wick et al. showed, with experiments on synthetic data, that there exist situations in which bias mitigation techniques lead to more accurate models when measured on unbiased data. Nevertheless, in the absence of a thorough mathematical analysis, it remains unclear which techniques are effective under what circumstances. We propose to address this problem by establishing relationships between the type of bias and the effectiveness of a mitigation technique, where we categorize the mitigation techniques by the bias measure they optimize. In this paper we illustrate this principle for label and selection bias on the one hand, and demographic parity and ``We're All Equal'' on the other hand. Our theoretical analysis allows to explain the results of Wick et al. and we also show that there are situations where minimizing fairness measures does not result in the fairest possible distribution.
Beyond Accuracy-Fairness: Stop evaluating bias mitigation methods solely on between-group metrics
Jan 24, 2024Artificial Intelligence (AI) finds widespread applications across various domains, sparking concerns about fairness in its deployment. While fairness in AI remains a central concern, the prevailing discourse often emphasizes outcome-based metrics without a nuanced consideration of the differential impacts within subgroups. Bias mitigation techniques do not only affect the ranking of pairs of instances across sensitive groups, but often also significantly affect the ranking of instances within these groups. Such changes are hard to explain and raise concerns regarding the validity of the intervention. Unfortunately, these effects largely remain under the radar in the accuracy-fairness evaluation framework that is usually applied. This paper challenges the prevailing metrics for assessing bias mitigation techniques, arguing that they do not take into account the changes within-groups and that the resulting prediction labels fall short of reflecting real-world scenarios. We propose a paradigm shift: initially, we should focus on generating the most precise ranking for each subgroup. Following this, individuals should be chosen from these rankings to meet both fairness standards and practical considerations.
Model-based Counterfactual Generator for Gender Bias Mitigation
Nov 06, 2023Counterfactual Data Augmentation (CDA) has been one of the preferred techniques for mitigating gender bias in natural language models. CDA techniques have mostly employed word substitution based on dictionaries. Although such dictionary-based CDA techniques have been shown to significantly improve the mitigation of gender bias, in this paper, we highlight some limitations of such dictionary-based counterfactual data augmentation techniques, such as susceptibility to ungrammatical compositions, and lack of generalization outside the set of predefined dictionary words. Model-based solutions can alleviate these problems, yet the lack of qualitative parallel training data hinders development in this direction. Therefore, we propose a combination of data processing techniques and a bi-objective training regime to develop a model-based solution for generating counterfactuals to mitigate gender bias. We implemented our proposed solution and performed an empirical evaluation which shows how our model alleviates the shortcomings of dictionary-based solutions.
How Far Can It Go?: On Intrinsic Gender Bias Mitigation for Text Classification
Jan 30, 2023

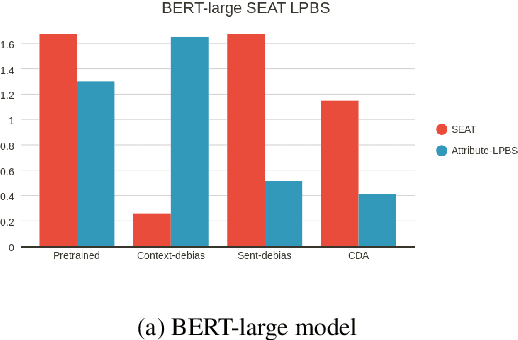
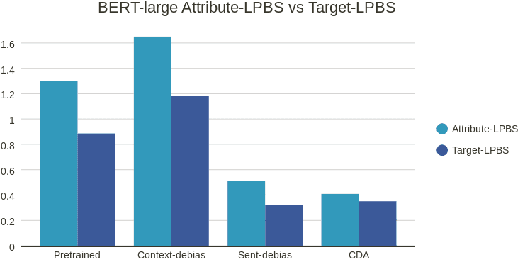
To mitigate gender bias in contextualized language models, different intrinsic mitigation strategies have been proposed, alongside many bias metrics. Considering that the end use of these language models is for downstream tasks like text classification, it is important to understand how these intrinsic bias mitigation strategies actually translate to fairness in downstream tasks and the extent of this. In this work, we design a probe to investigate the effects that some of the major intrinsic gender bias mitigation strategies have on downstream text classification tasks. We discover that instead of resolving gender bias, intrinsic mitigation techniques and metrics are able to hide it in such a way that significant gender information is retained in the embeddings. Furthermore, we show that each mitigation technique is able to hide the bias from some of the intrinsic bias measures but not all, and each intrinsic bias measure can be fooled by some mitigation techniques, but not all. We confirm experimentally, that none of the intrinsic mitigation techniques used without any other fairness intervention is able to consistently impact extrinsic bias. We recommend that intrinsic bias mitigation techniques should be combined with other fairness interventions for downstream tasks.
Text Style Transfer for Bias Mitigation using Masked Language Modeling
Jan 21, 2022



It is well known that textual data on the internet and other digital platforms contain significant levels of bias and stereotypes. Although many such texts contain stereotypes and biases that inherently exist in natural language for reasons that are not necessarily malicious, there are crucial reasons to mitigate these biases. For one, these texts are being used as training corpus to train language models for salient applications like cv-screening, search engines, and chatbots; such applications are turning out to produce discriminatory results. Also, several research findings have concluded that biased texts have significant effects on the target demographic groups. For instance, masculine-worded job advertisements tend to be less appealing to female applicants. In this paper, we present a text style transfer model that can be used to automatically debias textual data. Our style transfer model improves on the limitations of many existing style transfer techniques such as loss of content information. Our model solves such issues by combining latent content encoding with explicit keyword replacement. We will show that this technique produces better content preservation whilst maintaining good style transfer accuracy.
Measuring Fairness with Biased Rulers: A Survey on Quantifying Biases in Pretrained Language Models
Dec 14, 2021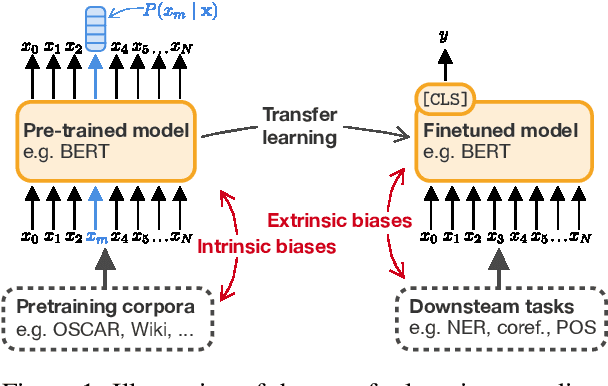

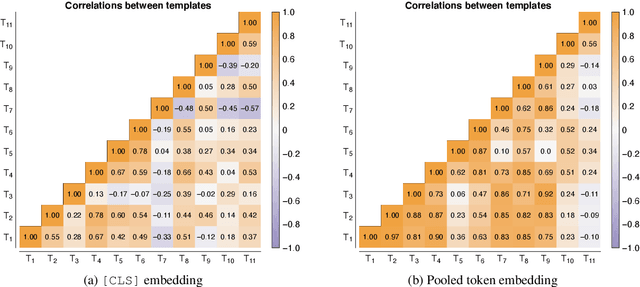

An increasing awareness of biased patterns in natural language processing resources, like BERT, has motivated many metrics to quantify `bias' and `fairness'. But comparing the results of different metrics and the works that evaluate with such metrics remains difficult, if not outright impossible. We survey the existing literature on fairness metrics for pretrained language models and experimentally evaluate compatibility, including both biases in language models as in their downstream tasks. We do this by a mixture of traditional literature survey and correlation analysis, as well as by running empirical evaluations. We find that many metrics are not compatible and highly depend on (i) templates, (ii) attribute and target seeds and (iii) the choice of embeddings. These results indicate that fairness or bias evaluation remains challenging for contextualized language models, if not at least highly subjective. To improve future comparisons and fairness evaluations, we recommend avoiding embedding-based metrics and focusing on fairness evaluations in downstream tasks.
Detecting and Explaining Drifts in Yearly Grant Applications
Oct 16, 2018



During the lifetime of a Business Process changes can be made to the workflow, the required resources, required documents, . . . . Different traces from the same Business Process within a single log file can thus differ substantially due to these changes. We propose a method that is able to detect concept drift in multivariate log files with a dozen attributes. We test our approach on the BPI Challenge 2018 data con- sisting of applications for EU direct payment from farmers in Germany where we use it to detect Concept Drift. In contrast to other methods our algorithm does not require the manual selection of the features used to detect drift. Our method first creates a model that captures the re- lations between attributes and between events of different time steps. This model is then used to score every event and trace. These scores can be used to detect outlying cases and concept drift. Thanks to the decomposability of the score we are able to perform detailed root-cause analysis.
Extending Dynamic Bayesian Networks for Anomaly Detection in Complex Logs
Aug 17, 2018



Checking various log files from different processes can be a tedious task as these logs contain lots of events, each with a (possibly large) number of attributes. We developed a way to automatically model log files and detect outlier traces in the data. For that we extend Dynamic Bayesian Networks to model the normal behavior found in log files. We introduce a new algorithm that is able to learn a model of a log file starting from the data itself. The model is capable of scoring traces even when new values or new combinations of values appear in the log file.
Mining All Non-Derivable Frequent Itemsets
Jun 03, 2002



Recent studies on frequent itemset mining algorithms resulted in significant performance improvements. However, if the minimal support threshold is set too low, or the data is highly correlated, the number of frequent itemsets itself can be prohibitively large. To overcome this problem, recently several proposals have been made to construct a concise representation of the frequent itemsets, instead of mining all frequent itemsets. The main goal of this paper is to identify redundancies in the set of all frequent itemsets and to exploit these redundancies in order to reduce the result of a mining operation. We present deduction rules to derive tight bounds on the support of candidate itemsets. We show how the deduction rules allow for constructing a minimal representation for all frequent itemsets. We also present connections between our proposal and recent proposals for concise representations and we give the results of experiments on real-life datasets that show the effectiveness of the deduction rules. In fact, the experiments even show that in many cases, first mining the concise representation, and then creating the frequent itemsets from this representation outperforms existing frequent set mining algorithms.