 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePingchuan Ma
Testing and Understanding Erroneous Planning in LLM Agents through Synthesized User Inputs
Apr 27, 2024
Agents based on large language models (LLMs) have demonstrated effectiveness in solving a wide range of tasks by integrating LLMs with key modules such as planning, memory, and tool usage. Increasingly, customers are adopting LLM agents across a variety of commercial applications critical to reliability, including support for mental well-being, chemical synthesis, and software development. Nevertheless, our observations and daily use of LLM agents indicate that they are prone to making erroneous plans, especially when the tasks are complex and require long-term planning. In this paper, we propose PDoctor, a novel and automated approach to testing LLM agents and understanding their erroneous planning. As the first work in this direction, we formulate the detection of erroneous planning as a constraint satisfiability problem: an LLM agent's plan is considered erroneous if its execution violates the constraints derived from the user inputs. To this end, PDoctor first defines a domain-specific language (DSL) for user queries and synthesizes varying inputs with the assistance of the Z3 constraint solver. These synthesized inputs are natural language paragraphs that specify the requirements for completing a series of tasks. Then, PDoctor derives constraints from these requirements to form a testing oracle. We evaluate PDoctor with three mainstream agent frameworks and two powerful LLMs (GPT-3.5 and GPT-4). The results show that PDoctor can effectively detect diverse errors in agent planning and provide insights and error characteristics that are valuable to both agent developers and users. We conclude by discussing potential alternative designs and directions to extend PDoctor.
ZigMa: Zigzag Mamba Diffusion Model
Mar 20, 2024The diffusion model has long been plagued by scalability and quadratic complexity issues, especially within transformer-based structures. In this study, we aim to leverage the long sequence modeling capability of a State-Space Model called Mamba to extend its applicability to visual data generation. Firstly, we identify a critical oversight in most current Mamba-based vision methods, namely the lack of consideration for spatial continuity in the scan scheme of Mamba. Secondly, building upon this insight, we introduce a simple, plug-and-play, zero-parameter method named Zigzag Mamba, which outperforms Mamba-based baselines and demonstrates improved speed and memory utilization compared to transformer-based baselines. Lastly, we integrate Zigzag Mamba with the Stochastic Interpolant framework to investigate the scalability of the model on large-resolution visual datasets, such as FacesHQ $1024\times 1024$ and UCF101, MultiModal-CelebA-HQ, and MS COCO $256\times 256$. Code will be released at https://taohu.me/zigma/
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Mar 20, 2024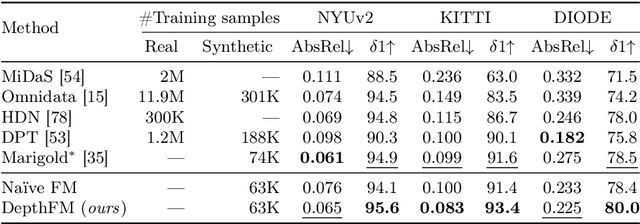

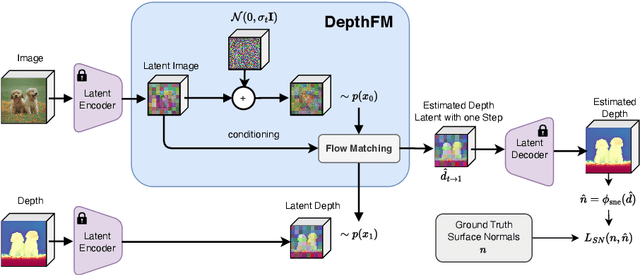

Monocular depth estimation is crucial for numerous downstream vision tasks and applications. Current discriminative approaches to this problem are limited due to blurry artifacts, while state-of-the-art generative methods suffer from slow sampling due to their SDE nature. Rather than starting from noise, we seek a direct mapping from input image to depth map. We observe that this can be effectively framed using flow matching, since its straight trajectories through solution space offer efficiency and high quality. Our study demonstrates that a pre-trained image diffusion model can serve as an adequate prior for a flow matching depth model, allowing efficient training on only synthetic data to generalize to real images. We find that an auxiliary surface normals loss further improves the depth estimates. Due to the generative nature of our approach, our model reliably predicts the confidence of its depth estimates. On standard benchmarks of complex natural scenes, our lightweight approach exhibits state-of-the-art performance at favorable low computational cost despite only being trained on little synthetic data.
Eliminating Information Leakage in Hard Concept Bottleneck Models with Supervised, Hierarchical Concept Learning
Feb 03, 2024Concept Bottleneck Models (CBMs) aim to deliver interpretable and interventionable predictions by bridging features and labels with human-understandable concepts. While recent CBMs show promising potential, they suffer from information leakage, where unintended information beyond the concepts (either when concepts are represented with probabilities or binary states) are leaked to the subsequent label prediction. Consequently, distinct classes are falsely classified via indistinguishable concepts, undermining the interpretation and intervention of CBMs. This paper alleviates the information leakage issue by introducing label supervision in concept predication and constructing a hierarchical concept set. Accordingly, we propose a new paradigm of CBMs, namely SupCBM, which achieves label predication via predicted concepts and a deliberately-designed intervention matrix. SupCBM focuses on concepts that are mostly relevant to the predicted label and only distinguishes classes when different concepts are presented. Our evaluations show that SupCBM outperforms SOTA CBMs over diverse datasets. It also manifests better generality across different backbone models. With proper quantification of information leakage in different CBMs, we demonstrate that SupCBM significantly reduces the information leakage.
An Empirical Study on Large Language Models in Accuracy and Robustness under Chinese Industrial Scenarios
Jan 27, 2024Recent years have witnessed the rapid development of large language models (LLMs) in various domains. To better serve the large number of Chinese users, many commercial vendors in China have adopted localization strategies, training and providing local LLMs specifically customized for Chinese users. Furthermore, looking ahead, one of the key future applications of LLMs will be practical deployment in industrial production by enterprises and users in those sectors. However, the accuracy and robustness of LLMs in industrial scenarios have not been well studied. In this paper, we present a comprehensive empirical study on the accuracy and robustness of LLMs in the context of the Chinese industrial production area. We manually collected 1,200 domain-specific problems from 8 different industrial sectors to evaluate LLM accuracy. Furthermore, we designed a metamorphic testing framework containing four industrial-specific stability categories with eight abilities, totaling 13,631 questions with variants to evaluate LLM robustness. In total, we evaluated 9 different LLMs developed by Chinese vendors, as well as four different LLMs developed by global vendors. Our major findings include: (1) Current LLMs exhibit low accuracy in Chinese industrial contexts, with all LLMs scoring less than 0.6. (2) The robustness scores vary across industrial sectors, and local LLMs overall perform worse than global ones. (3) LLM robustness differs significantly across abilities. Global LLMs are more robust under logical-related variants, while advanced local LLMs perform better on problems related to understanding Chinese industrial terminology. Our study results provide valuable guidance for understanding and promoting the industrial domain capabilities of LLMs from both development and industrial enterprise perspectives. The results further motivate possible research directions and tooling support.
Motion Flow Matching for Human Motion Synthesis and Editing
Dec 14, 2023Human motion synthesis is a fundamental task in computer animation. Recent methods based on diffusion models or GPT structure demonstrate commendable performance but exhibit drawbacks in terms of slow sampling speeds and error accumulation. In this paper, we propose \emph{Motion Flow Matching}, a novel generative model designed for human motion generation featuring efficient sampling and effectiveness in motion editing applications. Our method reduces the sampling complexity from thousand steps in previous diffusion models to just ten steps, while achieving comparable performance in text-to-motion and action-to-motion generation benchmarks. Noticeably, our approach establishes a new state-of-the-art Fr\'echet Inception Distance on the KIT-ML dataset. What is more, we tailor a straightforward motion editing paradigm named \emph{sampling trajectory rewriting} leveraging the ODE-style generative models and apply it to various editing scenarios including motion prediction, motion in-between prediction, motion interpolation, and upper-body editing. Our code will be released.
Boosting Latent Diffusion with Flow Matching
Dec 12, 2023Recently, there has been tremendous progress in visual synthesis and the underlying generative models. Here, diffusion models (DMs) stand out particularly, but lately, flow matching (FM) has also garnered considerable interest. While DMs excel in providing diverse images, they suffer from long training and slow generation. With latent diffusion, these issues are only partially alleviated. Conversely, FM offers faster training and inference but exhibits less diversity in synthesis. We demonstrate that introducing FM between the Diffusion model and the convolutional decoder offers high-resolution image synthesis with reduced computational cost and model size. Diffusion can then efficiently provide the necessary generation diversity. FM compensates for the lower resolution, mapping the small latent space to a high-dimensional one. Subsequently, the convolutional decoder of the LDM maps these latents to high-resolution images. By combining the diversity of DMs, the efficiency of FMs, and the effectiveness of convolutional decoders, we achieve state-of-the-art high-resolution image synthesis at $1024^2$ with minimal computational cost. Importantly, our approach is orthogonal to recent approximation and speed-up strategies for the underlying DMs, making it easily integrable into various DM frameworks.
VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models
Dec 07, 2023With recent advancements in Large Multimodal Models (LMMs) across various domains, a novel prompting method called visual referring prompting has emerged, showing significant potential in enhancing human-computer interaction within multimodal systems. This method offers a more natural and flexible approach to human interaction with these systems compared to traditional text descriptions or coordinates. However, the categorization of visual referring prompting remains undefined, and its impact on the performance of LMMs has yet to be formally examined. In this study, we conduct the first comprehensive analysis of LMMs using a variety of visual referring prompting strategies. We introduce a benchmark dataset called VRPTEST, comprising 3 different visual tasks and 2,275 images, spanning diverse combinations of prompt strategies. Using VRPTEST, we conduct a comprehensive evaluation of eight versions of prominent open-source and proprietary foundation models, including two early versions of GPT-4V. We develop an automated assessment framework based on software metamorphic testing techniques to evaluate the accuracy of LMMs without the need for human intervention or manual labeling. We find that the current proprietary models generally outperform the open-source ones, showing an average accuracy improvement of 22.70%; however, there is still potential for improvement. Moreover, our quantitative analysis shows that the choice of prompt strategy significantly affects the accuracy of LMMs, with variations ranging from -17.5% to +7.3%. Further case studies indicate that an appropriate visual referring prompting strategy can improve LMMs' understanding of context and location information, while an unsuitable one might lead to answer rejection. We also provide insights on minimizing the negative impact of visual referring prompting on LMMs.
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models
Dec 04, 2023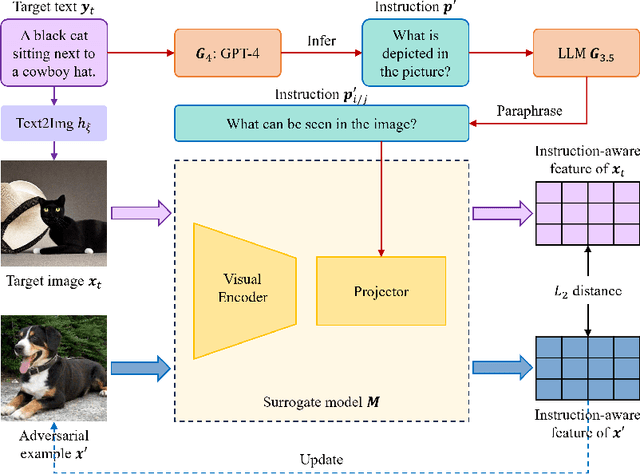
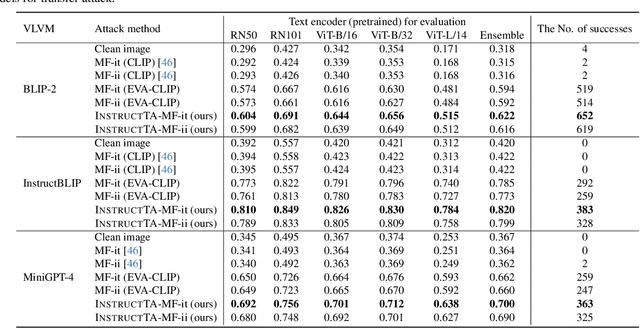
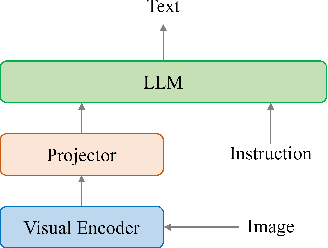
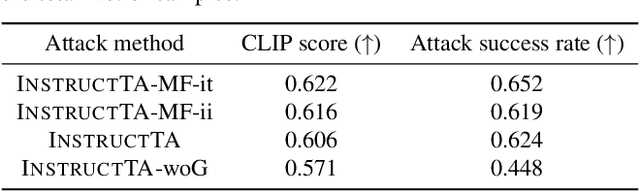
Large vision-language models (LVLMs) have demonstrated their incredible capability in image understanding and response generation. However, this rich visual interaction also makes LVLMs vulnerable to adversarial examples. In this paper, we formulate a novel and practical gray-box attack scenario that the adversary can only access the visual encoder of the victim LVLM, without the knowledge of its prompts (which are often proprietary for service providers and not publicly available) and its underlying large language model (LLM). This practical setting poses challenges to the cross-prompt and cross-model transferability of targeted adversarial attack, which aims to confuse the LVLM to output a response that is semantically similar to the attacker's chosen target text. To this end, we propose an instruction-tuned targeted attack (dubbed InstructTA) to deliver the targeted adversarial attack on LVLMs with high transferability. Initially, we utilize a public text-to-image generative model to "reverse" the target response into a target image, and employ GPT-4 to infer a reasonable instruction $\boldsymbol{p}^\prime$ from the target response. We then form a local surrogate model (sharing the same visual encoder with the victim LVLM) to extract instruction-aware features of an adversarial image example and the target image, and minimize the distance between these two features to optimize the adversarial example. To further improve the transferability, we augment the instruction $\boldsymbol{p}^\prime$ with instructions paraphrased from an LLM. Extensive experiments demonstrate the superiority of our proposed method in targeted attack performance and transferability.
DiffuseBot: Breeding Soft Robots With Physics-Augmented Generative Diffusion Models
Nov 28, 2023Nature evolves creatures with a high complexity of morphological and behavioral intelligence, meanwhile computational methods lag in approaching that diversity and efficacy. Co-optimization of artificial creatures' morphology and control in silico shows promise for applications in physical soft robotics and virtual character creation; such approaches, however, require developing new learning algorithms that can reason about function atop pure structure. In this paper, we present DiffuseBot, a physics-augmented diffusion model that generates soft robot morphologies capable of excelling in a wide spectrum of tasks. DiffuseBot bridges the gap between virtually generated content and physical utility by (i) augmenting the diffusion process with a physical dynamical simulation which provides a certificate of performance, and (ii) introducing a co-design procedure that jointly optimizes physical design and control by leveraging information about physical sensitivities from differentiable simulation. We showcase a range of simulated and fabricated robots along with their capabilities. Check our website at https://diffusebot.github.io/