 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQian Qian
3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics
Nov 18, 2020
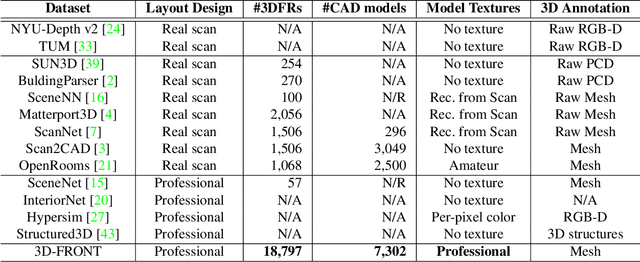
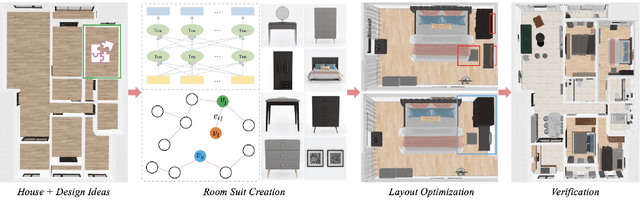
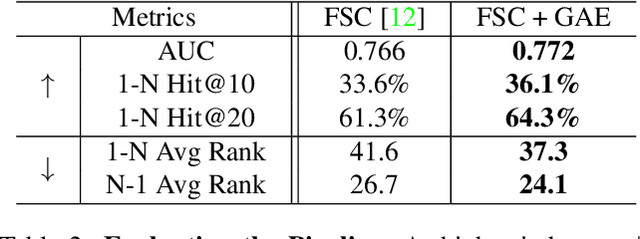
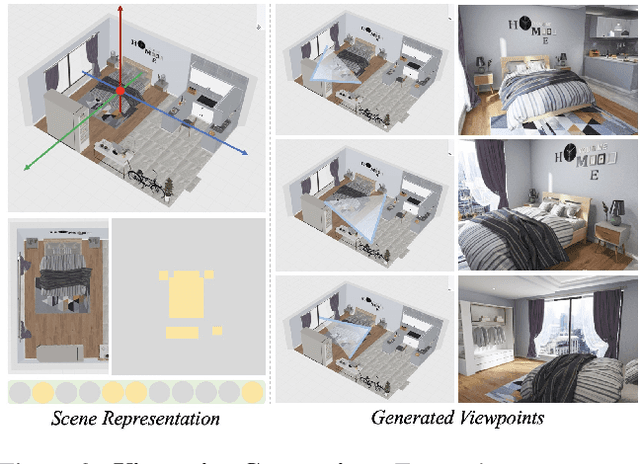
We introduce 3D-FRONT (3D Furnished Rooms with layOuts and semaNTics), a new, large-scale, and comprehensive repository of synthetic indoor scenes highlighted by professionally designed layouts and a large number of rooms populated by high-quality textured 3D models with style compatibility. From layout semantics down to texture details of individual objects, our dataset is freely available to the academic community and beyond. Currently, 3D-FRONT contains 18,797 rooms diversely furnished by 3D objects, far surpassing all publicly available scene datasets. In addition, the 7,302 furniture objects all come with high-quality textures. While the floorplans and layout designs are directly sourced from professional creations, the interior designs in terms of furniture styles, color, and textures have been carefully curated based on a recommender system we develop to attain consistent styles as expert designs. Furthermore, we release Trescope, a light-weight rendering tool, to support benchmark rendering of 2D images and annotations from 3D-FRONT. We demonstrate two applications, interior scene synthesis and texture synthesis, that are especially tailored to the strengths of our new dataset. The project page is at: https://tianchi.aliyun.com/specials/promotion/alibaba-3d-scene-dataset.
On the connections between algorithmic regularization and penalization for convex losses
Sep 08, 2019In this work we establish the equivalence of algorithmic regularization and explicit convex penalization for generic convex losses. We introduce a geometric condition for the optimization path of a convex function, and show that if such a condition is satisfied, the optimization path of an iterative algorithm on the unregularized optimization problem can be represented as the solution path of a corresponding penalized problem.
The Implicit Bias of AdaGrad on Separable Data
Jun 09, 2019

We study the implicit bias of AdaGrad on separable linear classification problems. We show that AdaGrad converges to a direction that can be characterized as the solution of a quadratic optimization problem with the same feasible set as the hard SVM problem. We also give a discussion about how different choices of the hyperparameters of AdaGrad might impact this direction. This provides a deeper understanding of why adaptive methods do not seem to have the generalization ability as good as gradient descent does in practice.