 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingcan Wang
Global Convergence of Gradient Descent for Deep Linear Residual Networks
Nov 02, 2019
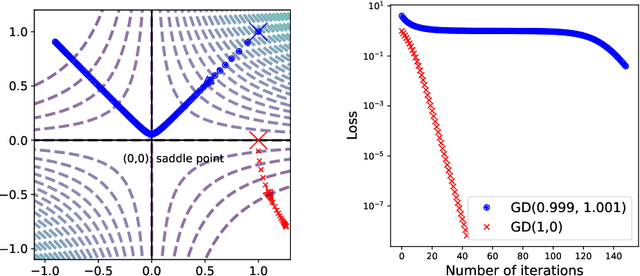
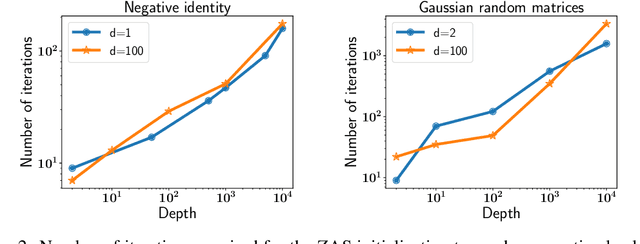
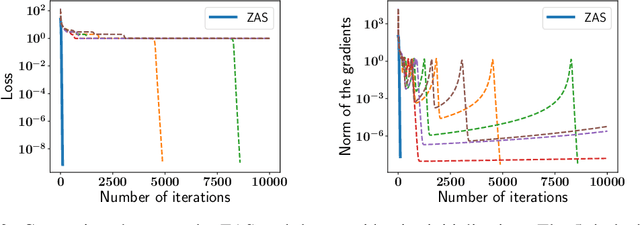
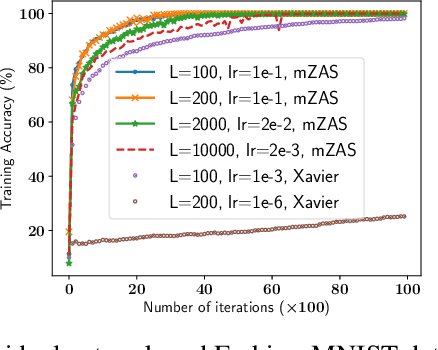
We analyze the global convergence of gradient descent for deep linear residual networks by proposing a new initialization: zero-asymmetric (ZAS) initialization. It is motivated by avoiding stable manifolds of saddle points. We prove that under the ZAS initialization, for an arbitrary target matrix, gradient descent converges to an $\varepsilon$-optimal point in $O(L^3 \log(1/\varepsilon))$ iterations, which scales polynomially with the network depth $L$. Our result and the $\exp(\Omega(L))$ convergence time for the standard initialization (Xavier or near-identity) [Shamir, 2018] together demonstrate the importance of the residual structure and the initialization in the optimization for deep linear neural networks, especially when $L$ is large.
Analysis of the Gradient Descent Algorithm for a Deep Neural Network Model with Skip-connections
Apr 14, 2019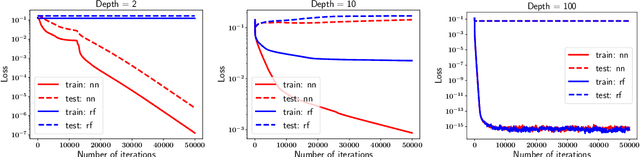
The behavior of the gradient descent (GD) algorithm is analyzed for a deep neural network model with skip-connections. It is proved that in the over-parametrized regime, for a suitable initialization, with high probability GD can find a global minimum exponentially fast. Generalization error estimates along the GD path are also established. As a consequence, it is shown that when the target function is in the reproducing kernel Hilbert space (RKHS) with a kernel defined by the initialization, there exist generalizable early-stopping solutions along the GD path. In addition, it is also shown that the GD path is uniformly close to the functions given by the related random feature model. Consequently, in this "implicit regularization" setting, the deep neural network model deteriorates to a random feature model. Our results hold for neural networks of any width larger than the input dimension.
A Priori Estimates of the Population Risk for Residual Networks
Mar 06, 2019
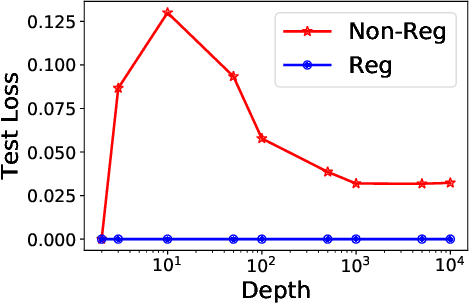
Optimal a priori estimates are derived for the population risk of a regularized residual network model. The key lies in the designing of a new path norm, called the weighted path norm, which serves as the regularization term in the regularized model. The weighted path norm treats the skip connections and the nonlinearities differently so that paths with more nonlinearities have larger weights. The error estimates are a priori in nature in the sense that the estimates depend only on the target function and not on the parameters obtained in the training process. The estimates are optimal in the sense that the bound scales as O(1/L) with the network depth and the estimation error is comparable to the Monte Carlo error rates. In particular, optimal error bounds are obtained, for the first time, in terms of the depth of the network model. Comparisons are made with existing norm-based generalization error bounds.
Featurized Bidirectional GAN: Adversarial Defense via Adversarially Learned Semantic Inference
Sep 29, 2018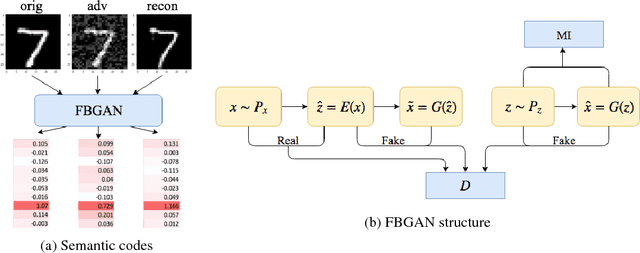
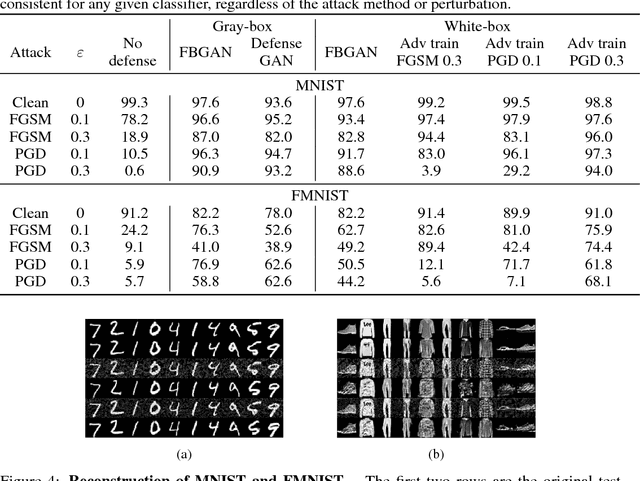
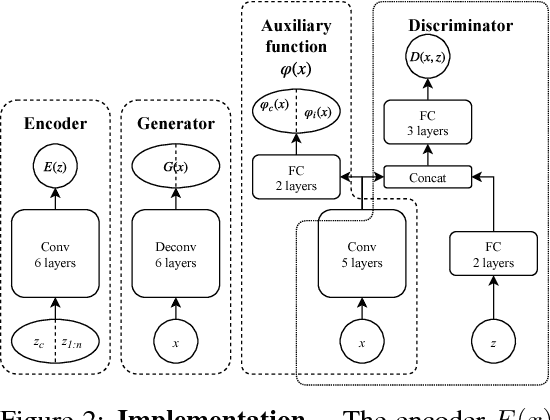
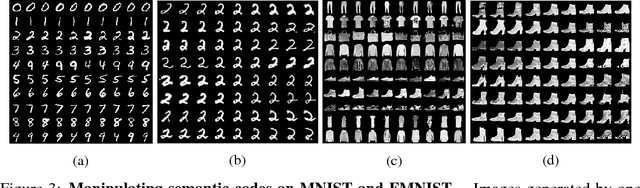
Deep neural networks have been demonstrated to be vulnerable to adversarial attacks, where small perturbations intentionally added to the original inputs can fool the classifier. In this paper, we propose a defense method, Featurized Bidirectional Generative Adversarial Networks (FBGAN), to extract the semantic features of the input and filter the non-semantic perturbation. FBGAN is pre-trained on the clean dataset in an unsupervised manner, adversarially learning a bidirectional mapping between the high-dimensional data space and the low-dimensional semantic space; also mutual information is applied to disentangle the semantically meaningful features. After the bidirectional mapping, the adversarial data can be reconstructed to denoised data, which could be fed into any pre-trained classifier. We empirically show the quality of reconstruction images and the effectiveness of defense.
Exponential Convergence of the Deep Neural Network Approximation for Analytic Functions
Jul 01, 2018We prove that for analytic functions in low dimension, the convergence rate of the deep neural network approximation is exponential.